
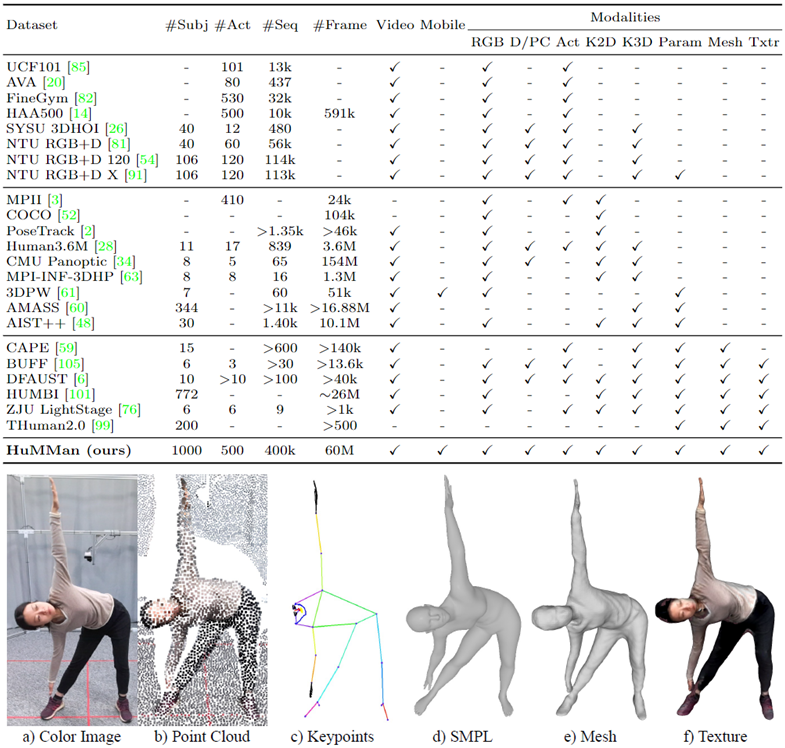
人的4D感知与建模是计算机视觉和图像学的基本任务,也有着广泛的应用。随着新传感器与算法的出现,对多样化的数据集的需求也日渐提升。在这个工作中,本文贡献了HuMMan:一个大规模多模态4D人体数据集。HuMMan包含1000个人物,40万段视频,6000万帧数据。
HuMMan有着多个优势:1)多模态数据和标注包括彩色图片、点云、关键点、SMPL参数以及带纹理的网格模型;2)数据采集方案中部署了移动端设备;3)一个500个动作的集合,覆盖了人体基本的动作;4)HuMMan支持多种任务如动作识别、姿态估计、参数化人体估计以及带纹理的网格模型重建。在HuMMan上的实验指出了细粒度的动作识别、动态人体网格模型重建、基于点云的参数化人体估计以及跨设备的域间隙(domain gap),都是非常值得深入研究的问题。
论文名称:HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Part 1 硬件搭建
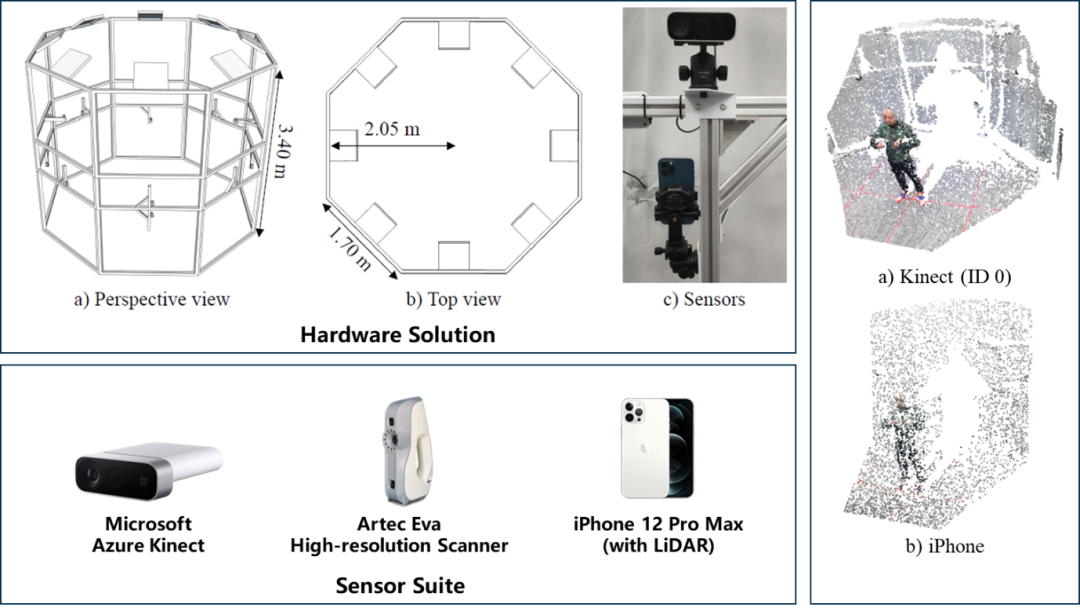
我们为获取高质量深度图专门设计了一个较为紧凑的数据采集设施,使用10部Kinect Azure相机来获取同步的RGB-D帧。另外,我们增加了一部手持扫描仪来获取高精度人体网格(精度可达0.1 mm)。更重要的是,我们额外包括了流行的移动端设备(内置激光雷达),采集了对现实应用非常相关的数据。
Part 2 工具链
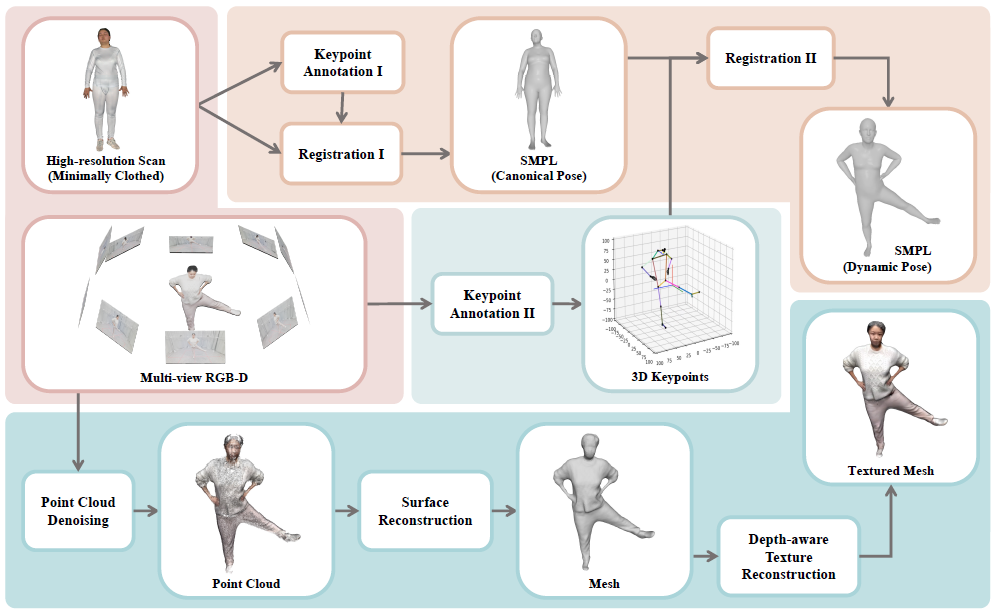
我们开发的工具链支持多种数据和标注模态,例如图片、点云、关键点、SMPL参数以及带纹理的网格模型。
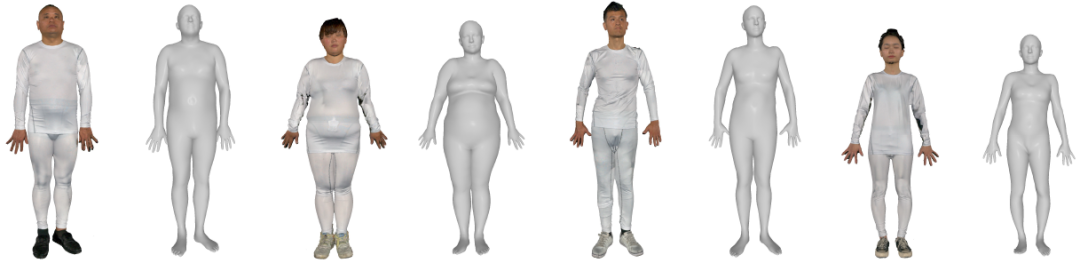
其中,我们通过将SMPL配准到高清人体扫描上获取精确的人体形状参数。
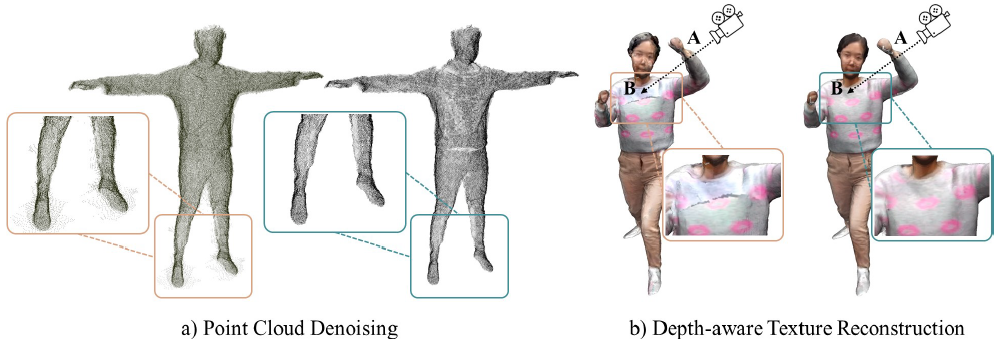
对于带纹理的网格模型,我们主要的步骤包括点云去噪与利用深度的纹理重建,从而降低投影误差。

我们提供参数化模型与带纹理的网格模型的动态序列,更多的细节请见我们的论文。
Part 3 动作集

我们从人体解剖学的角度设计了500个动作的动作集,其三个特点为层级式的设计、完备(包括了上半身动作、下半身动作和全身动作)、无歧义(我们的动作定义是依赖于驱动的肌肉,而不是抽象的描述)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢