

论文链接:https://arxiv.org/pdf/2209.06794.pdf
导读
语言和视觉任务的建模中,更大的神经网络模型能获得更好的结果,几乎已经是共识。在语言方面,T5、GPT-3、Megatron-Turing、GLAM、Chinchilla 和 PaLM 等模型显示出了在大文本数据上训练大型 transformer 的明显优势。视觉方面,CNN、视觉 transformer 和其他模型都从大模型中取得了很好的结果。language-and-vision 建模也是类似的情况,如 SimVLM、Florence、CoCa、GIT、BEiT 和 Flamingo。
在这篇论文中,来自谷歌的研究者通过一个名为 PaLI (Pathways Language and Image)的模型来延续这一方向的研究。
PaLI 使用单独 “Image-and-text to text” 接口执行很多图像、语言以及 "图像 + 语言" 任务。PaLI 的关键结构之一是重复使用大型单模态 backbone 进行语言和视觉建模,以迁移现有能力并降低训练成本。
在语言方面,作者复用有 13B 参数的 mT5-XXL。mT5-XXL 已经把语言理解和泛化能力一体打包。作者通过实验证明这些功能可以维护并扩展到多模态情况。
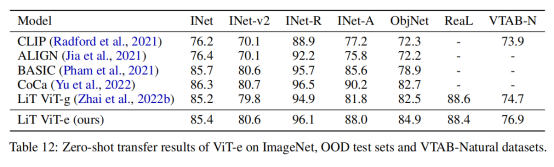
在视觉方面,除复用 2B 参数 ViT-G 模型外,作者还训练了拥有 4B 参数的模型 ViT-e("enormous")。ViT-e 在图像任务上表现出很好的性能(ImageNet 上准确率达到 90.9%;ObjectNet 准确率达到 84.9%)。
作者发现了联合 scaling 视觉和语言组件的好处,视觉提供了更好的投入回报(每个参数 / FLOP 带来的准确度提升)。实验结果表明,最大的 PaLI 模型——PaLI-17B 在两种任务模式下表现相对平衡,ViT-e 模型约占总参数的 25%。而先前的大规模视觉和语言建模工作,情况并非总是如此(Wang 等人,2022a;Alayrac 等人,2022),因为视觉和语言 backbone 之间的先验量表并不匹配。
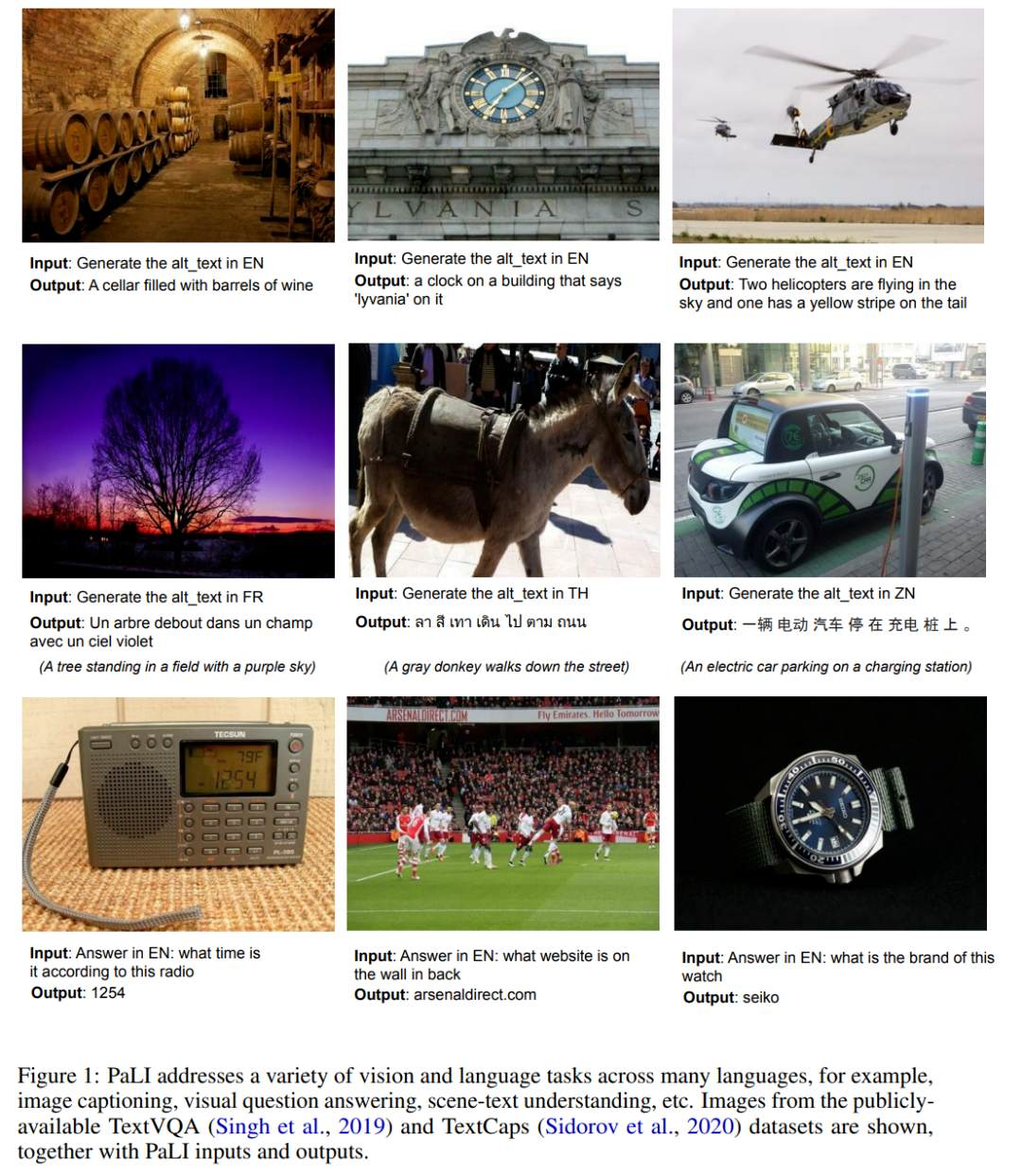
作者通过将多个图像和 (或) 语言任务转换为广义的类似 VQA 的任务,实现它们之间的知识共享。使用 “image+query to answer” 来构建所有任务,其中检索和回答都表示为文本标记。这使得 PaLI 能够使用跨任务的迁移学习,并在广泛的视觉和语言问题中增强 language-and-image 理解能力:图像描述、视觉问答、场景文本理解等(如图 1 所示)。
方法
PALI的目标之一是研究语言和视觉模型在性能和规模上的联系是否相同,特别是语言-图像模型的可扩展性(scalability)。
所以模型的架构设计上就很简单,主要是为了实验方便,尤其是可重复使用且可扩展。
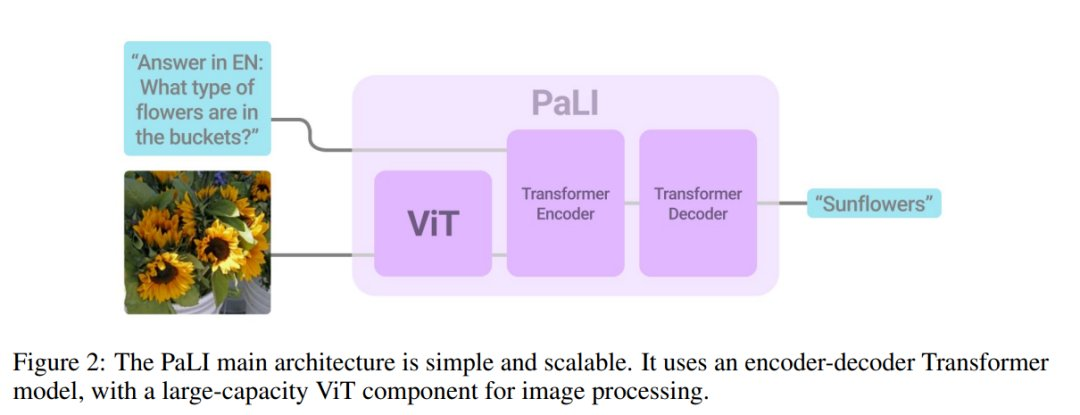
模型由一个处理输入文本的Transformer编码器和一个生成输出文本的自回归Transformer解码器组成。
在处理图像时,Transformer编码器的输入还包括代表由ViT处理的图像的视觉词(visual words)。
PaLI模型的一个关键设计是重用,研究人员用之前训练过的单模态视觉和语言模型(如mT5-XXL和大型ViTs)的权重作为模型的种子,这种重用不仅使单模态训练的能力得到迁移,而且还能节省计算成本。
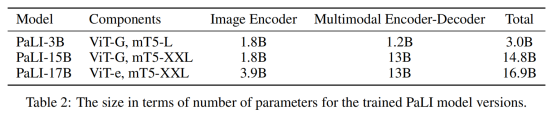
模型的视觉组件使用的是迄今为止最大的ViT架构ViT-e,它与18亿参数的ViT-G模型具有相同的结构,并使用相同的训练参数,区别就是扩展为了40亿参数。
虽然在视觉领域和语言领域都对缩放规律进行了研究,但在视觉和语言的组合模型中对缩放行为的探讨较少,扩大视觉骨干模型的规模可能会导致在分类任务中的收益饱和。
研究人员也进一步证实了这一点,可以观察到 ViT-e在ImageNet上只比ViT-G好一点,但ViT-e在PaLI的视觉语言任务上有很大的改进。例如,ViT-e在COCO字幕任务上比ViT-G多出近3个CIDEr点。任务上比ViT-G多出3分。这也暗示了未来在视觉语言任务中使用更大的ViT骨架模型的空间。
研究人员采用mT5骨干作为语言建模组件,使用预训练的mT5-Large(10亿参数)和mT5-XXL (130亿参数)来初始化PaLI的语言编码器-解码器,然后在许多语言任务中进行继续混合训练,包括纯语言理解任务,这也有助于避免灾难性的遗忘mT5的语言理解和生成能力。
最后得到了三个不同尺寸的PALI模型。
为了训练 PaLI-17B,作者构建了全新的大容量 image-and-language 数据集 WebLI,包含 10B 的图文对数据,WebLI 数据集包含 100 多种语言的文本。通过训练模型用多种语言执行多模态任务,这大大增加了任务的多样性,并测试了模型在跨任务和跨语言之间有效扩展的能力。作者也提供了数据卡来介绍有关 WebLI 及其构造的信息。
PaLI-17B 在多个 benchmark 上都达到了 SOTA,表现优于某些强大的模型(见表 1)。
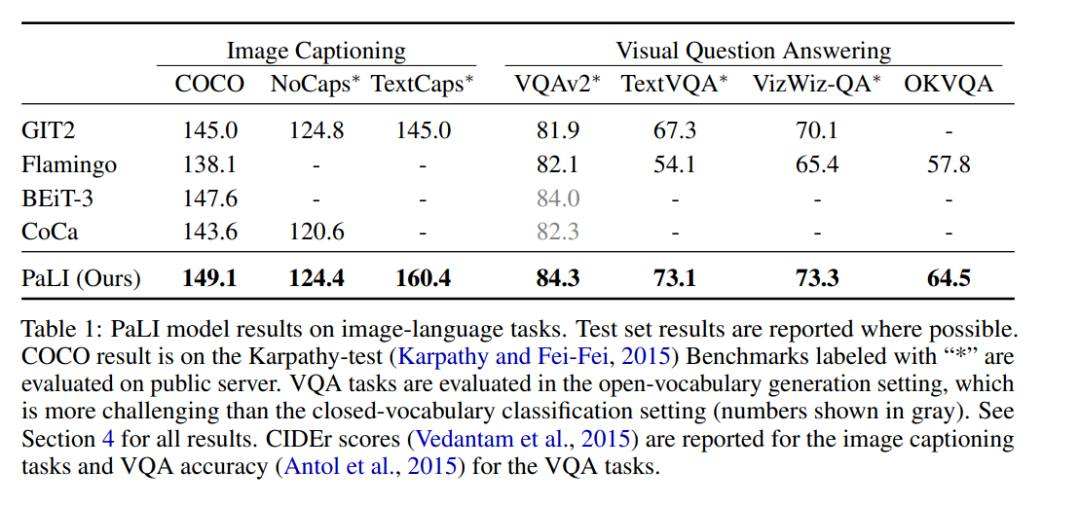
具体来说,PaLI 在 COCO 数据集 benchmark 上的表现优于多数新旧模型,在 Karpaty 分割上的得分为 149.1。PaLI 在 VQAv2 上使用类似 Flamingo 的开放词汇文本生成的设置达到 84.3% 的最新 SOTA,该结果甚至优于在固定词汇分类环境中评估的模型,例如 CoCa、SimVLM、BEiT-3。作者的工作为未来的多模态模型提供了 scaling 路线图。Model scaling 对于多语言环境中的语言图像理解特别重要。作者的结果支持这样一个结论:与其他替代方案相比,scaling 每个模式的组件会产生更好的性能。
实验分析
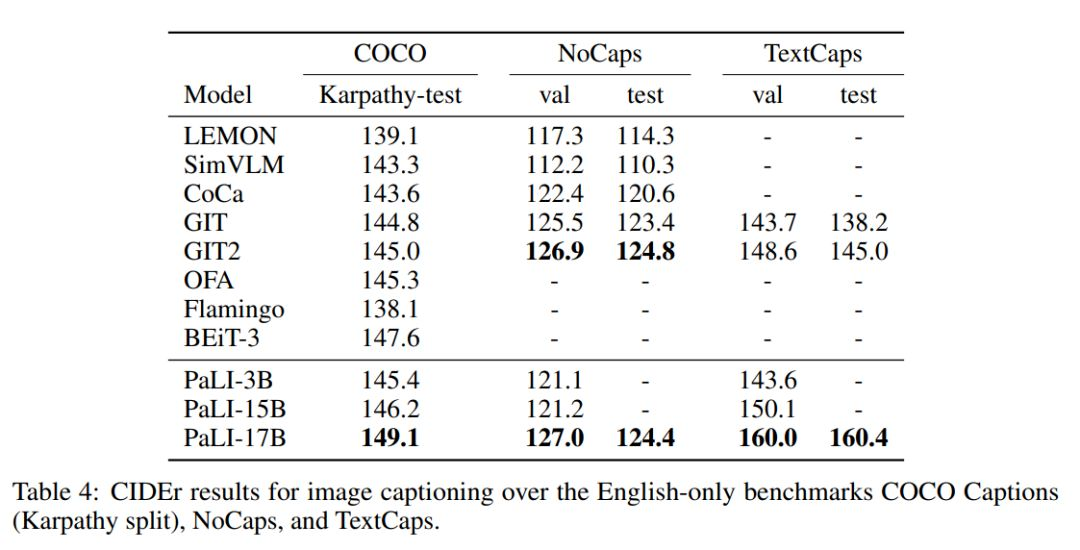
作者在三个纯英文图像的 benchmark 上评估了 PaLI 模型的变体,结果如表 4 所示。
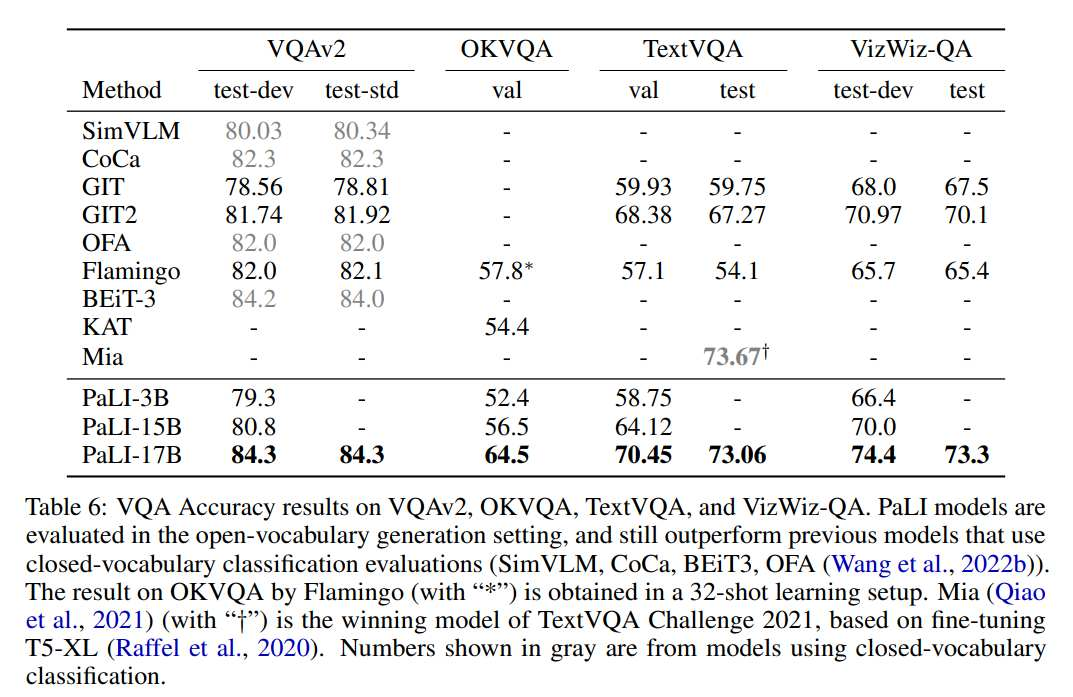
作者对四个仅英文视觉问答(VQA)benchmark 进行评估,结果见表 6。
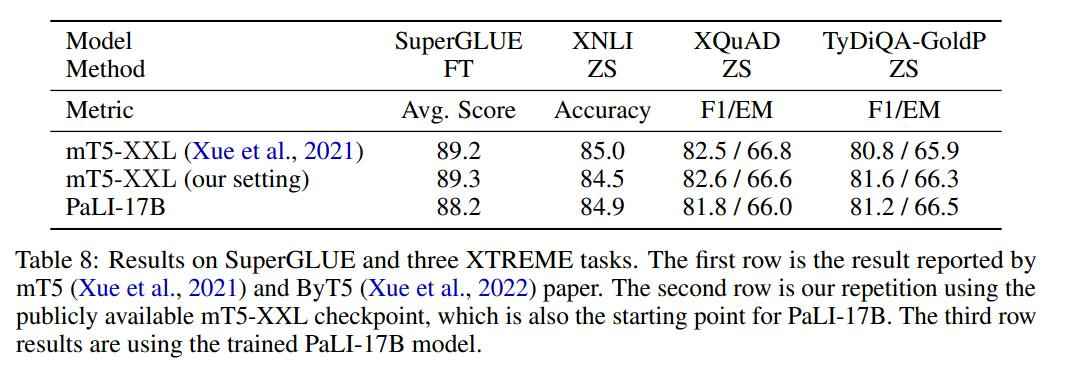
作者将 mT5-XXL 和 PaLI-17B 在一系列语言理解任务 benchmark 进行比较,对比结果如表 8 所示。
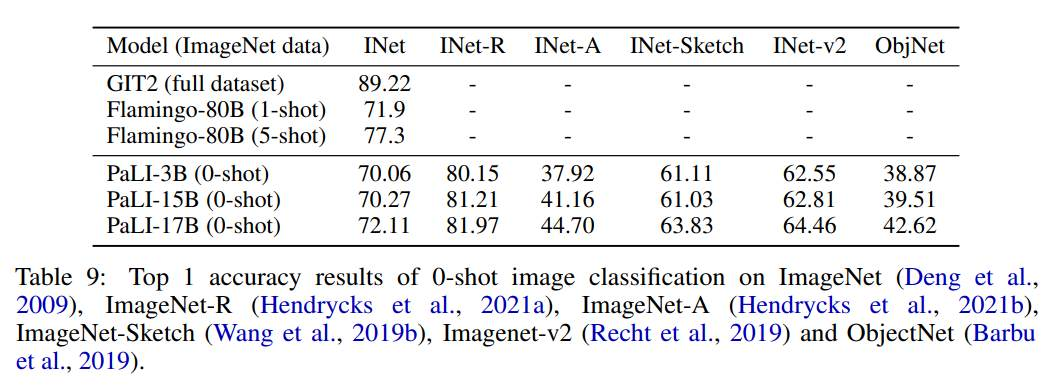
作者使用 224x224 分辨率(在高分辨率预微调之前)对 PaLI 模型在 Imagenet 和 Imagenet OOD 数据集上进行评估,评估结果如表 9 所示。
从实验效果上来看,越大的模型必然能够从越大的数据上建模越多的知识,除了PaLI模型参数量数一数二的突破,本文利用到的Image-and-text to text思路,以及对多模态同时进行多尺度的设计可能才是最让人眼前一亮的思路。作者通过将多个图像和 (或) 语言任务转换为广义的类似 VQA 的任务,沿着这个思路,在大模型中实现更有效的image to sequence能不能得到更好的应用?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢