
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:用扩散模型实现的基于文本的真实图像编辑、单线强化学习、基于离散随机性的程序自动微分、面向机器人手术中可变形组织立体3D重建的神经渲染技术、基于内在奖励匹配的基于技能强化学习、面向强化学习的Web IDE、用人工智能赋能地球观测、视觉-语言预训练综述、用具有挑战性的BIG-Bench任务挑战思维链
1、[CV] Imagic: Text-Based Real Image Editing with Diffusion Models
B Kawar, S Zada, O Lang, O Tov, H Chang, T Dekel, I Mosseri, M Irani
[Google Research]
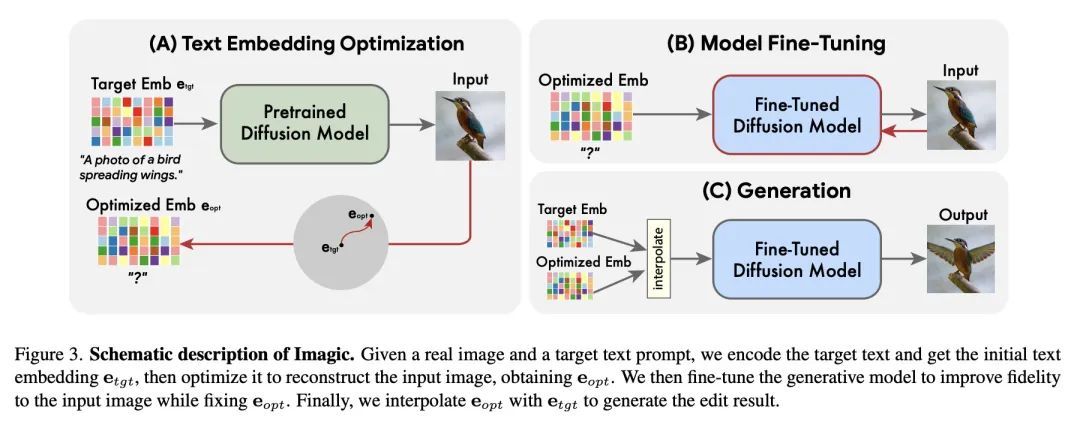
Imagic:用扩散模型实现的基于文本的真实图像编辑。以文字为条件的图像编辑最近引起了相当大的兴趣。然而,目前大多数方法要么局限于特定的编辑类型(如对象叠加、样式迁移),要么适用于合成的图像,要么需要一个共同对象的多个输入图像。本文首次展示了将复杂的(例如,非刚性的)文本引导的语义编辑应用于单一真实图像的能力。例如,可以改变图像中一个或多个物体的姿势和组成,同时保留其原始特征。所提出方法可以使一只站立的狗坐下来或跳起来,使一只鸟张开翅膀,等等——每个物体都在用户提供的单一高分辨率自然图像中。与之前的工作相反,本文提出的方法只需要一张输入图像和一个目标文本(所需的编辑)。在真实的图像上操作,不需要任何额外的输入(如图像掩码或物体的额外视图)。所提出方法,称为"Imagic",利用一个预先训练好的文本到图像的扩散模型来完成这项任务。它产生一个与输入图像和目标文本相一致的文本嵌入,同时对扩散模型进行微调,以捕捉图像的特定外观。在来自不同领域的众多输入上展示了所提出方法的质量和多功能性,展示了大量高质量的复杂语义图像编辑,所有这些都在一个统一的框架内。
Text-conditioned image editing has recently attracted considerable interest. However, most methods are currently either limited to specific editing types (e.g., object overlay, style transfer), or apply to synthetically generated images, or require multiple input images of a common object. In this paper we demonstrate, for the very first time, the ability to apply complex (e.g., non-rigid) text-guided semantic edits to a single real image. For example, we can change the posture and composition of one or multiple objects inside an image, while preserving its original characteristics. Our method can make a standing dog sit down or jump, cause a bird to spread its wings, etc. -- each within its single high-resolution natural image provided by the user. Contrary to previous work, our proposed method requires only a single input image and a target text (the desired edit). It operates on real images, and does not require any additional inputs (such as image masks or additional views of the object). Our method, which we call "Imagic", leverages a pre-trained text-to-image diffusion model for this task. It produces a text embedding that aligns with both the input image and the target text, while fine-tuning the diffusion model to capture the image-specific appearance. We demonstrate the quality and versatility of our method on numerous inputs from various domains, showcasing a plethora of high quality complex semantic image edits, all within a single unified framework.
https://arxiv.org/abs/2210.09276



2、[LG] You Only Live Once: Single-Life Reinforcement Learning
A S. Chen, A Sharma, S Levine, C Finn
[Stanford University & UC Berkeley]
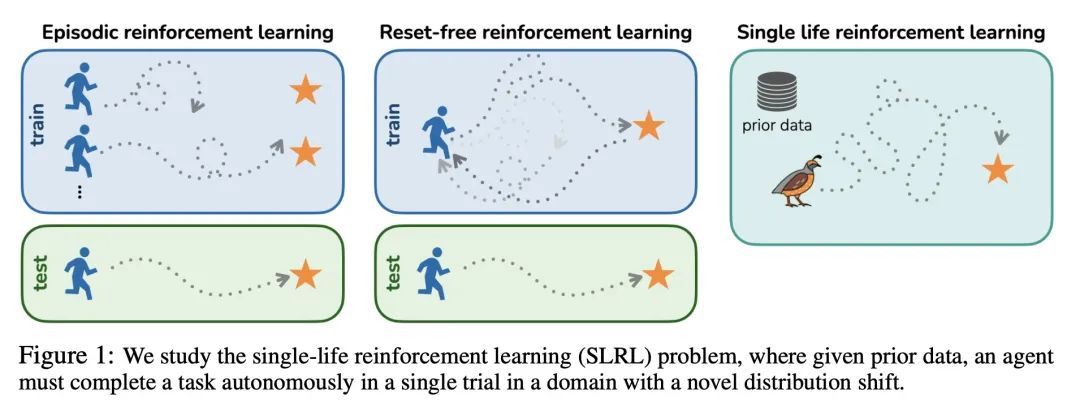
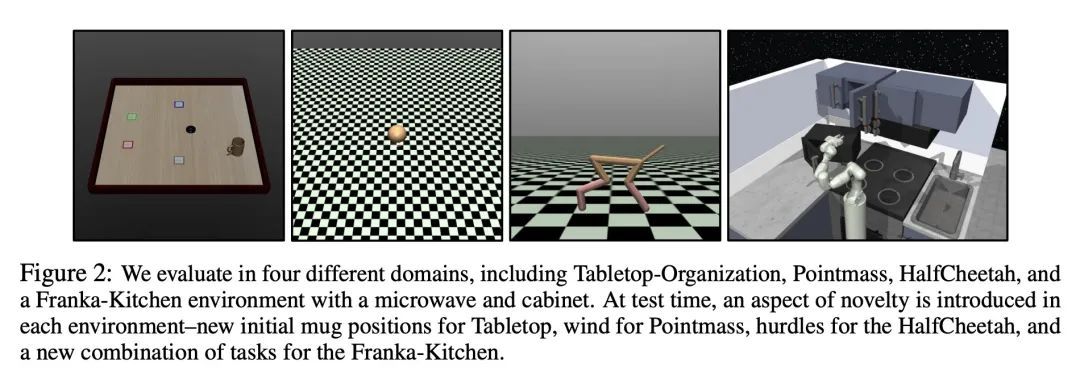
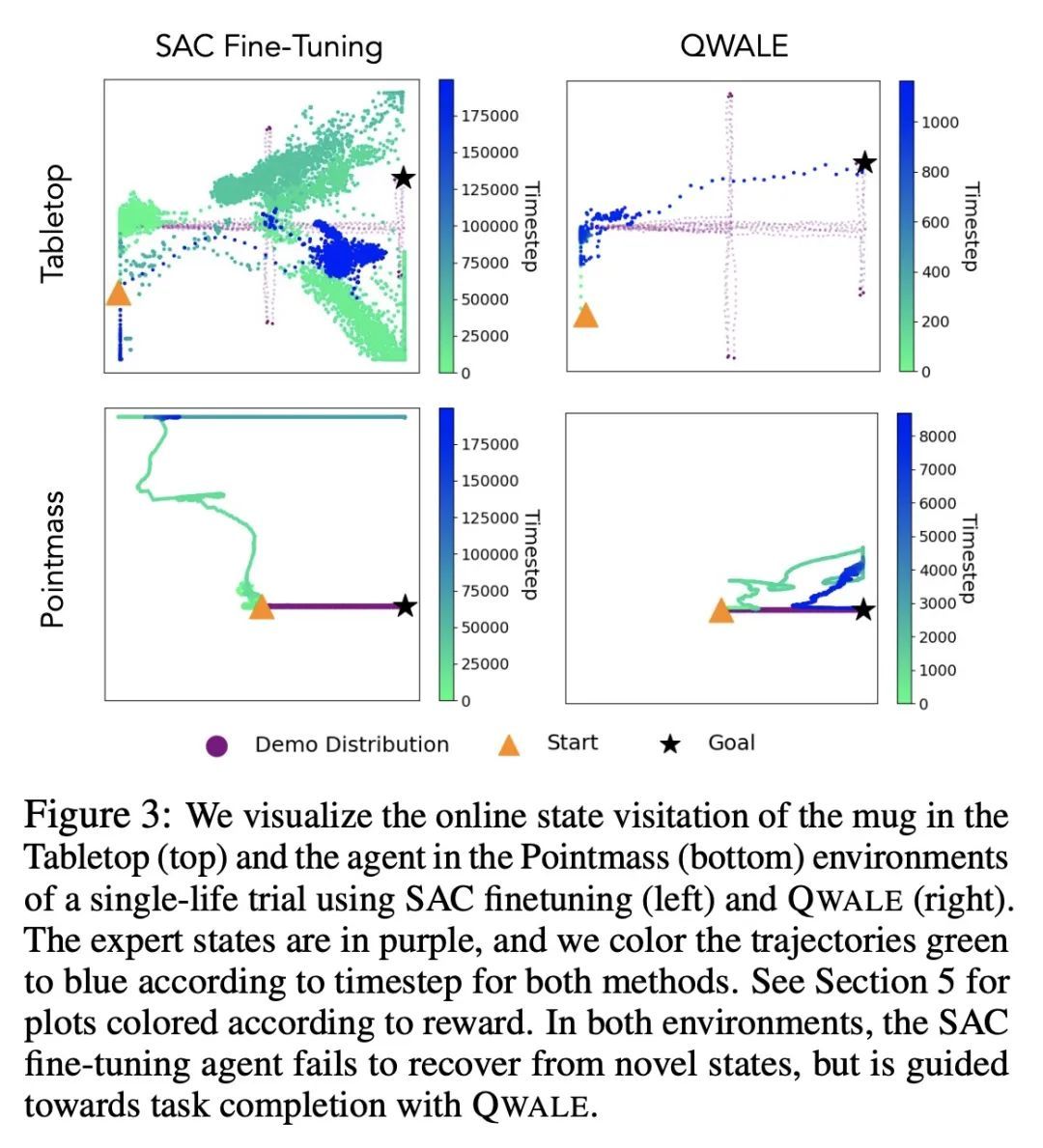
只活一次:单线强化学习。强化学习算法通常被设计为学习一种高性能策略,可以反复自主地完成一项任务,通常从头开始。然而,在许多现实世界的情况下,目标可能不是学习一个可以重复完成任务的策略,而是简单地在一次试验中成功执行一个新的任务。例如,设想一个救灾机器人的任务是从一个倒塌的建筑物中取回一个物品,在那里它不能得到人工的直接监督。它必须在一次测试时间内取回该物品,而且必须在处理未知的障碍物时进行,尽管它可以利用灾难发生前对该建筑的了解。本文将这一问题设置正式化,称为单线强化学习(SLRL),在这一问题中,智能体必须在没有干预的情况下完成一项任务,利用其先前的经验,同时与某种形式的新事物作斗争。SLRL提供了一个自然的环境来研究自主适应陌生环境的挑战,本文发现为标准情节强化学习设计的算法在这种环境下往往难以从失调状态中恢复过来。在这一观察的激励下,本文提出一种算法,即Q-加权对抗学习(QWALE),采用一种分布匹配策略,利用智能体的先前经验作为新情况下的指导。在几个单生命连续控制问题上的实验表明,基于所提出分布匹配公式的方法会多成功20-60%,因为它们能更快地从新的状态中恢复。
Reinforcement learning algorithms are typically designed to learn a performant policy that can repeatedly and autonomously complete a task, usually starting from scratch. However, in many real-world situations, the goal might not be to learn a policy that can do the task repeatedly, but simply to perform a new task successfully once in a single trial. For example, imagine a disaster relief robot tasked with retrieving an item from a fallen building, where it cannot get direct supervision from humans. It must retrieve this object within one test-time trial, and must do so while tackling unknown obstacles, though it may leverage knowledge it has of the building before the disaster. We formalize this problem setting, which we call single-life reinforcement learning (SLRL), where an agent must complete a task within a single episode without interventions, utilizing its prior experience while contending with some form of novelty. SLRL provides a natural setting to study the challenge of autonomously adapting to unfamiliar situations, and we find that algorithms designed for standard episodic reinforcement learning often struggle to recover from out-of-distribution states in this setting. Motivated by this observation, we propose an algorithm, Q-weighted adversarial learning (QWALE), which employs a distribution matching strategy that leverages the agent's prior experience as guidance in novel situations. Our experiments on several single-life continuous control problems indicate that methods based on our distribution matching formulation are 20-60% more successful because they can more quickly recover from novel states.
https://arxiv.org/abs/2210.08863

3、[LG] Automatic Differentiation of Programs with Discrete Randomness
G Arya, M Schauer, F Schäfer, C Rackauckas
[MIT& Chalmers University of Technology]
基于离散随机性的程序自动微分。自动微分(AD)是一种构建计算原始程序导数的新程序的技术,由于基于梯度的优化所带来的性能提升,在整个科学计算和深度学习中已经变得无处不在。然而,AD系统被限制在对参数有连续依赖性的程序子集上。那些由分布参数控制的离散随机行为的程序,如投掷硬币的概率为正面,对这些系统构成了挑战,因为结果(正面与反面)和参数(P)之间的联系从根本上是离散的。本文开发了一种新的基于重参数化的方法,允许生成期望值是原始程序期望值的导数的程序。本文展示了这种方法是如何给出一个无偏和低方差的估计器的,它与传统的AD机制一样自动化。本文展示了离散时间马尔科夫链的无偏正向模式AD,基于代理的模型,如康威的生命游戏,以及粒子过滤器的无偏反向模式AD。
Automatic differentiation (AD), a technique for constructing new programs which compute the derivative of an original program, has become ubiquitous throughout scientific computing and deep learning due to the improved performance afforded by gradient-based optimization. However, AD systems have been restricted to the subset of programs that have a continuous dependence on parameters. Programs that have discrete stochastic behaviors governed by distribution parameters, such as flipping a coin with probability of being heads, pose a challenge to these systems because the connection between the result (heads vs tails) and the parameters (p) is fundamentally discrete. In this paper we develop a new reparameterization-based methodology that allows for generating programs whose expectation is the derivative of the expectation of the original program. We showcase how this method gives an unbiased and low-variance estimator which is as automated as traditional AD mechanisms. We demonstrate unbiased forward-mode AD of discrete-time Markov chains, agent-based models such as Conway's Game of Life, and unbiased reverse-mode AD of a particle filter. Our code is available at this https URL.
https://arxiv.org/abs/2210.08572

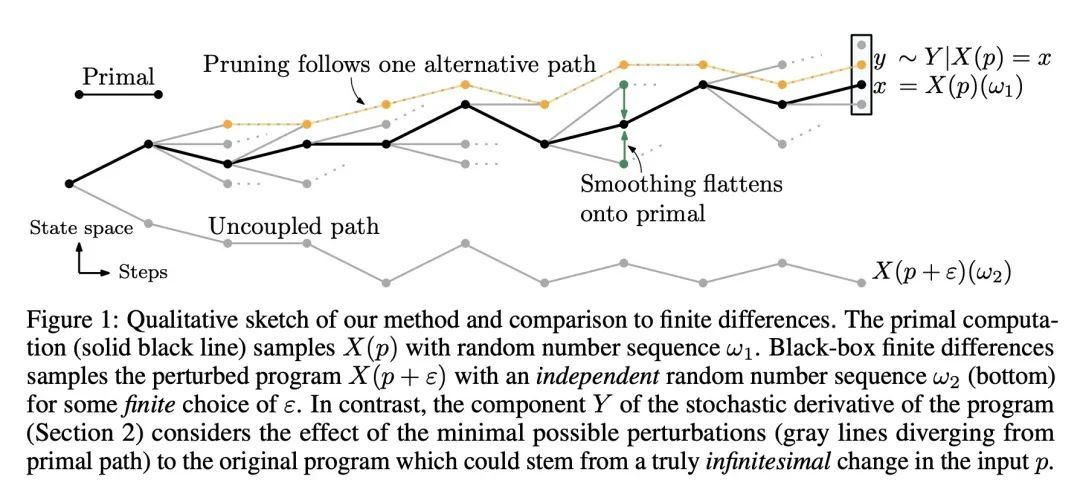


4、[CV] Neural Rendering for Stereo 3D Reconstruction of Deformable Tissues in Robotic Surgery
Y Wang, Y Long, S H Fan, Q Dou
[The Chinese University of Hong Kong]
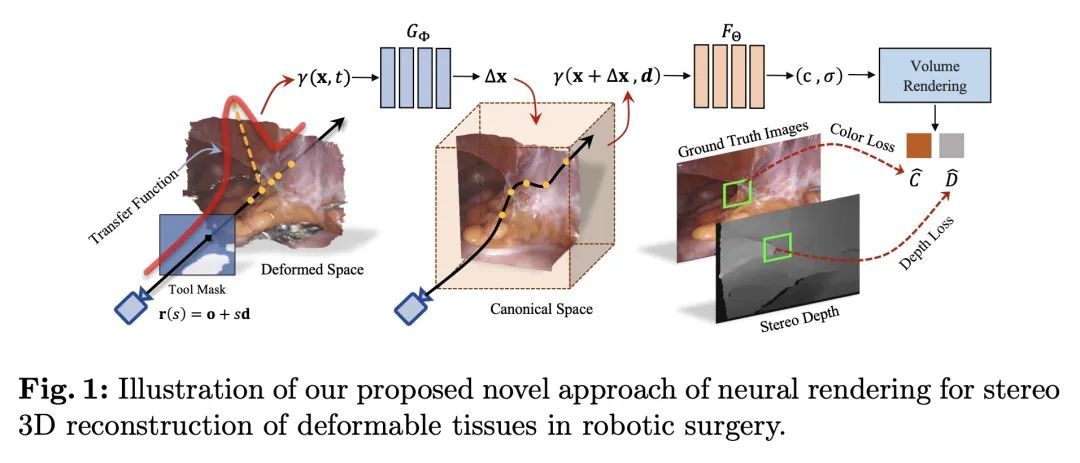
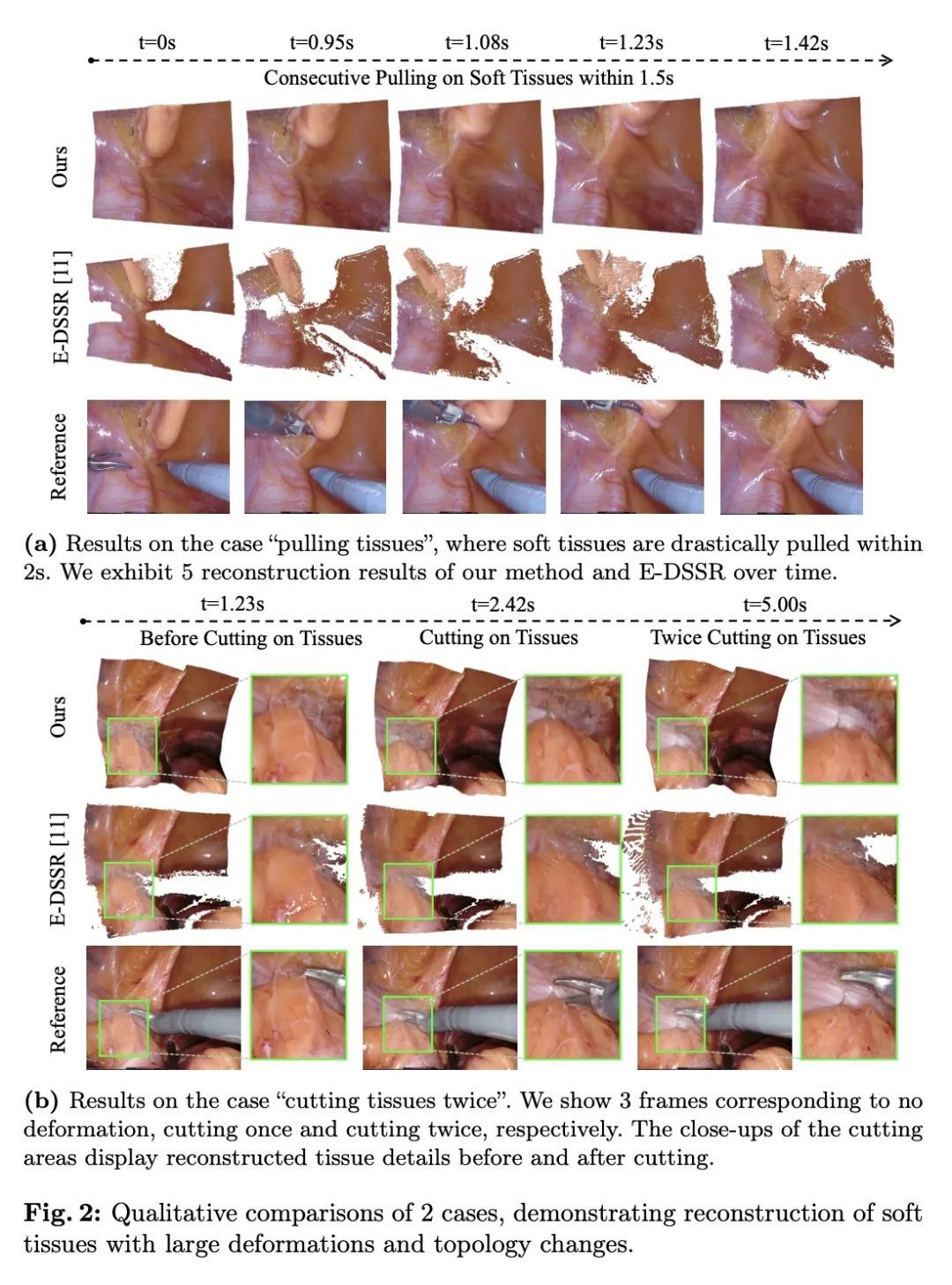
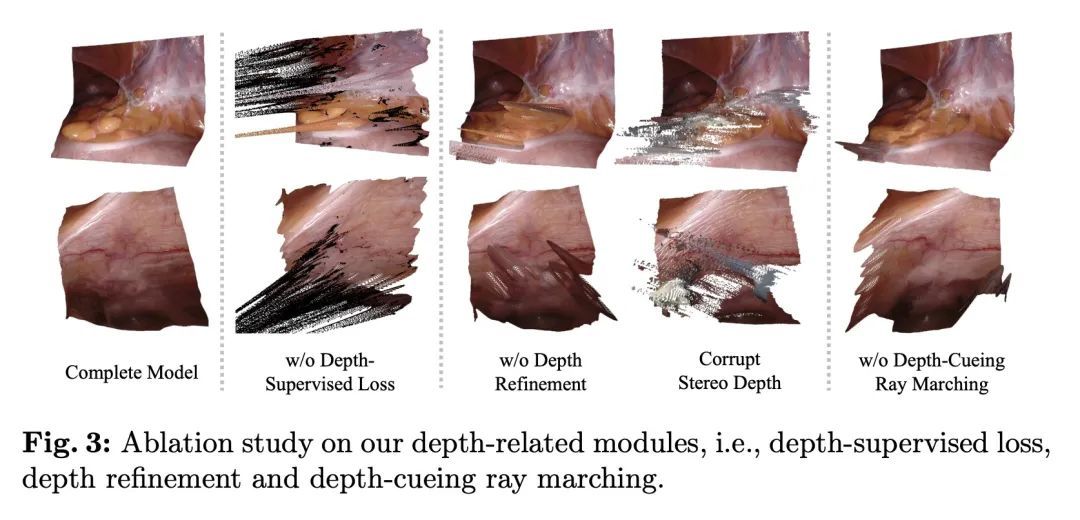
面向机器人手术中可变形组织立体3D重建的神经渲染技术。从内窥镜立体视频中重建机器人手术中的软组织对许多应用都很重要,如术中导航和图像引导的机器人手术自动化。之前关于这项任务的工作主要依靠基于SLAM的方法,这些方法很难处理复杂的手术场景。在神经渲染的最新进展的启发下,本文提出一种新框架,用于在单视角设置下的机器人手术中从双眼捕获的可变形组织重建。该框架采用动态神经辐射场来表示MLP中的可变形手术场景,并以基于学习的方式优化形状和变形。除了非刚性变形外,工具遮挡和单视角的不良3D线索也是软组织重建的特殊挑战。为了克服这些困难,本文提出了一系列策略,包括工具掩码引导的射线投射、立体深度提示的射线行进和立体深度监督的优化。通过对DaVinci机器人手术视频的实验,所提出方法在处理各种复杂的非刚性形变方面明显优于目前最先进的重建方法。
Reconstruction of the soft tissues in robotic surgery from endoscopic stereo videos is important for many applications such as intra-operative navigation and image-guided robotic surgery automation. Previous works on this task mainly rely on SLAM-based approaches, which struggle to handle complex surgical scenes. Inspired by recent progress in neural rendering, we present a novel framework for deformable tissue reconstruction from binocular captures in robotic surgery under the single-viewpoint setting. Our framework adopts dynamic neural radiance fields to represent deformable surgical scenes in MLPs and optimize shapes and deformations in a learning-based manner. In addition to non-rigid deformations, tool occlusion and poor 3D clues from a single viewpoint are also particular challenges in soft tissue reconstruction. To overcome these difficulties, we present a series of strategies of tool mask-guided ray casting, stereo depth-cueing ray marching and stereo depth-supervised optimization. With experiments on DaVinci robotic surgery videos, our method significantly outperforms the current state-of-the-art reconstruction method for handling various complex non-rigid deformations. To our best knowledge, this is the first work leveraging neural rendering for surgical scene 3D reconstruction with remarkable potential demonstrated. Code is available at: this https URL.
https://arxiv.org/abs/2206.15255

5、[LG] Skill-Based Reinforcement Learning with Intrinsic Reward Matching
A Adeniji, A Xie, P Abbeel
[UC Berkeley]
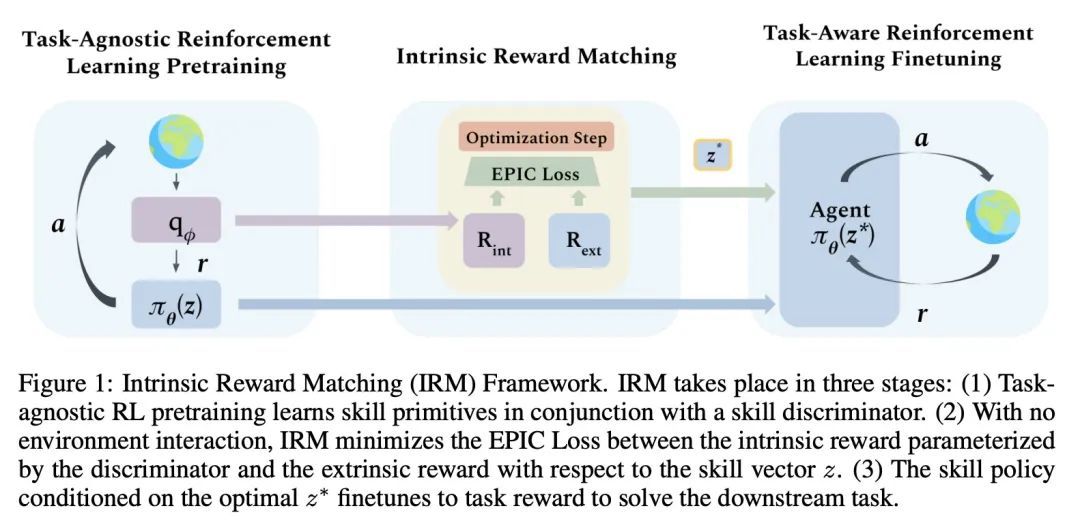
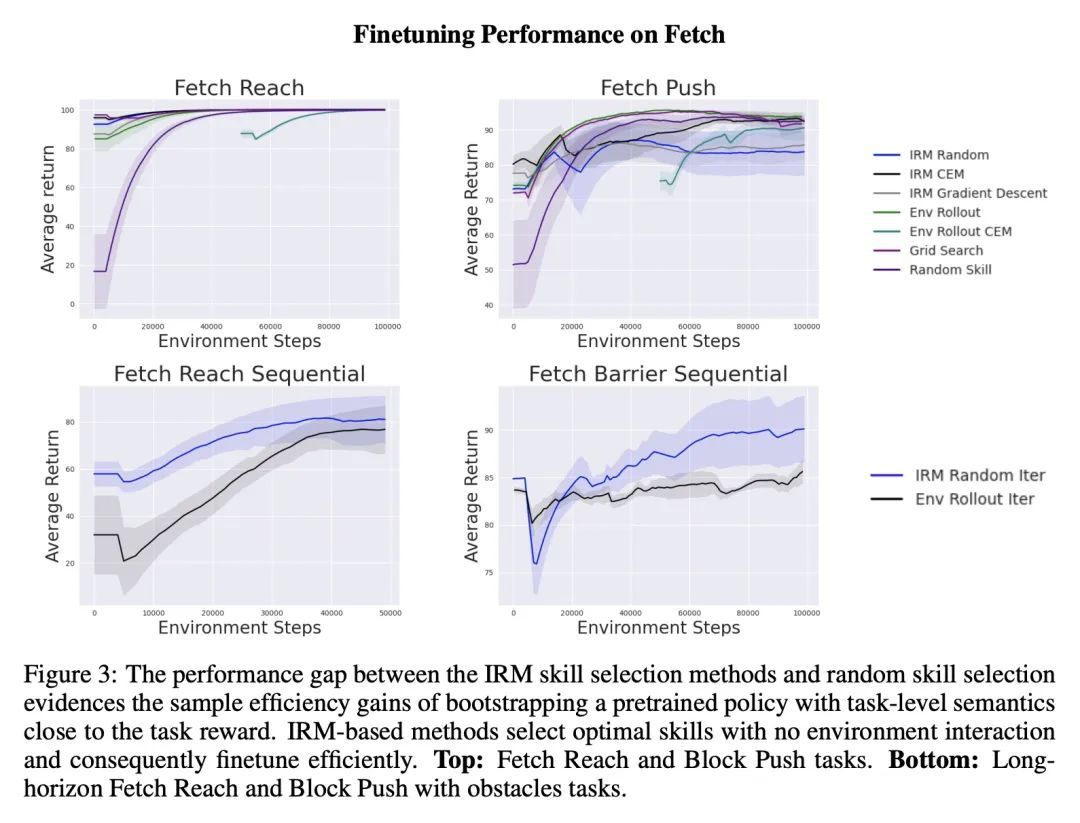
基于内在奖励匹配的基于技能强化学习。虽然无监督的技能发现在自主获取行为基元方面显示出良好的前景,但在任务不可知技能预训练和下游任务感知微调之间仍然存在很大的方法学上的脱节。本文提出内在奖励匹配(IRM),通过技能鉴别器统一了这两个阶段的学习,技能鉴别器是预训练模型的一个组成部分,在微调过程中经常被丢弃。传统的方法是直接在策略层面上对预训练的智能体进行微调,通常依靠昂贵的环境展开来经验性地确定最佳技能。然而,对一项任务最简明而完整的描述往往是奖励函数本身,技能学习方法通过与技能策略相对应的判别器学习内在的奖励函数。本文建议利用技能判别器来匹配内在的和下游的任务奖励,在没有环境样本的情况下确定未见任务的最佳技能,从而以更高的样本效率进行微调。此外,本文将IRM推广到技能序列,并解决更复杂的、长周期的任务,证明了IRM在无监督强化学习基准上与之前的技能选择方法相比具有竞争力,并使得能在具有挑战性的桌面操作任务上更有效地利用预训练的技能。
While unsupervised skill discovery has shown promise in autonomously acquiring behavioral primitives, there is still a large methodological disconnect between task-agnostic skill pretraining and downstream, task-aware finetuning. We present Intrinsic Reward Matching (IRM), which unifies these two phases of learning via the skill discriminator, a pretraining model component often discarded during finetuning. Conventional approaches finetune pretrained agents directly at the policy level, often relying on expensive environment rollouts to empirically determine the optimal skill. However, often the most concise yet complete description of a task is the reward function itself, and skill learning methods learn an intrinsic reward function via the discriminator that corresponds to the skill policy. We propose to leverage the skill discriminator to match the intrinsic and downstream task rewards and determine the optimal skill for an unseen task without environment samples, consequently finetuning with greater sample-efficiency. Furthermore, we generalize IRM to sequence skills and solve more complex, long-horizon tasks. We demonstrate that IRM is competitive with previous skill selection methods on the Unsupervised Reinforcement Learning Benchmark and enables us to utilize pretrained skills far more effectively on challenging tabletop manipulation tasks.
https://arxiv.org/abs/2210.07426


另外几篇值得关注的论文:
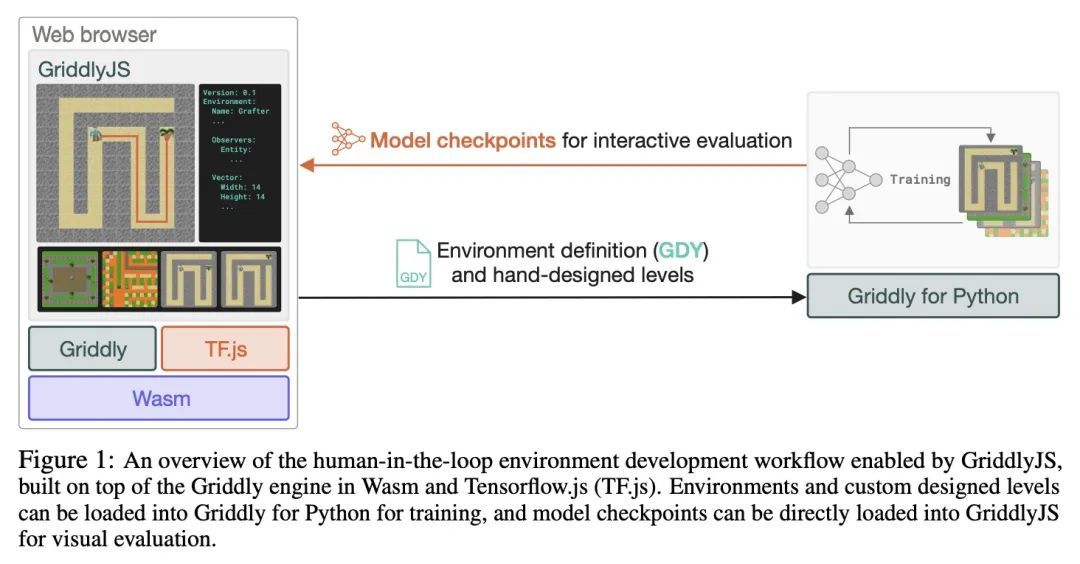
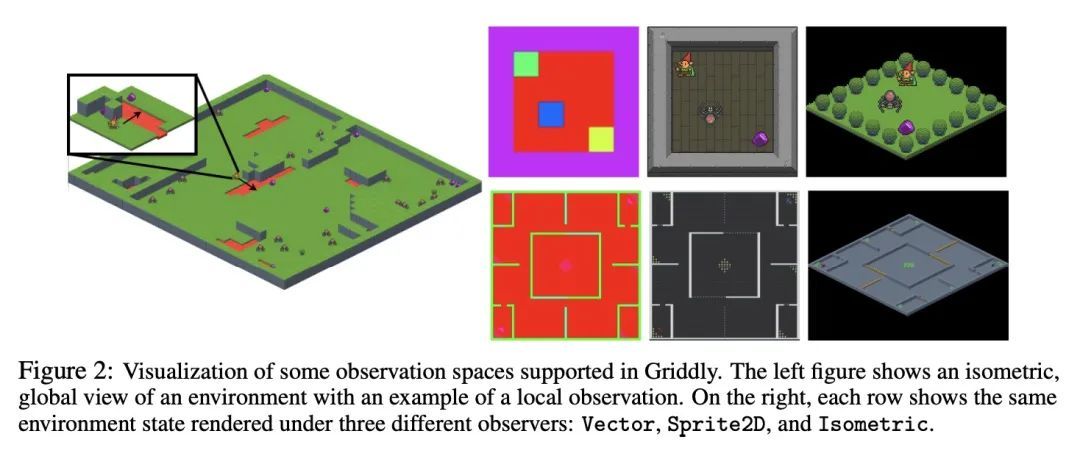
[LG] GriddlyJS: A Web IDE for Reinforcement Learning
GriddlyJS:面向强化学习的Web IDE
C Bamford, M Jiang, M Samvelyan, T Rocktäschel
[Queen Mary University & Meta AI & UCL]
https://arxiv.org/abs/2207.06105


[CV] EarthNets: Empowering AI in Earth Observation
EarthNets:用人工智能赋能地球观测
Z Xiong, F Zhang, Y Wang, Y Shi, X X Zhu
[Technical University of Munich]
https://arxiv.org/abs/2210.04936

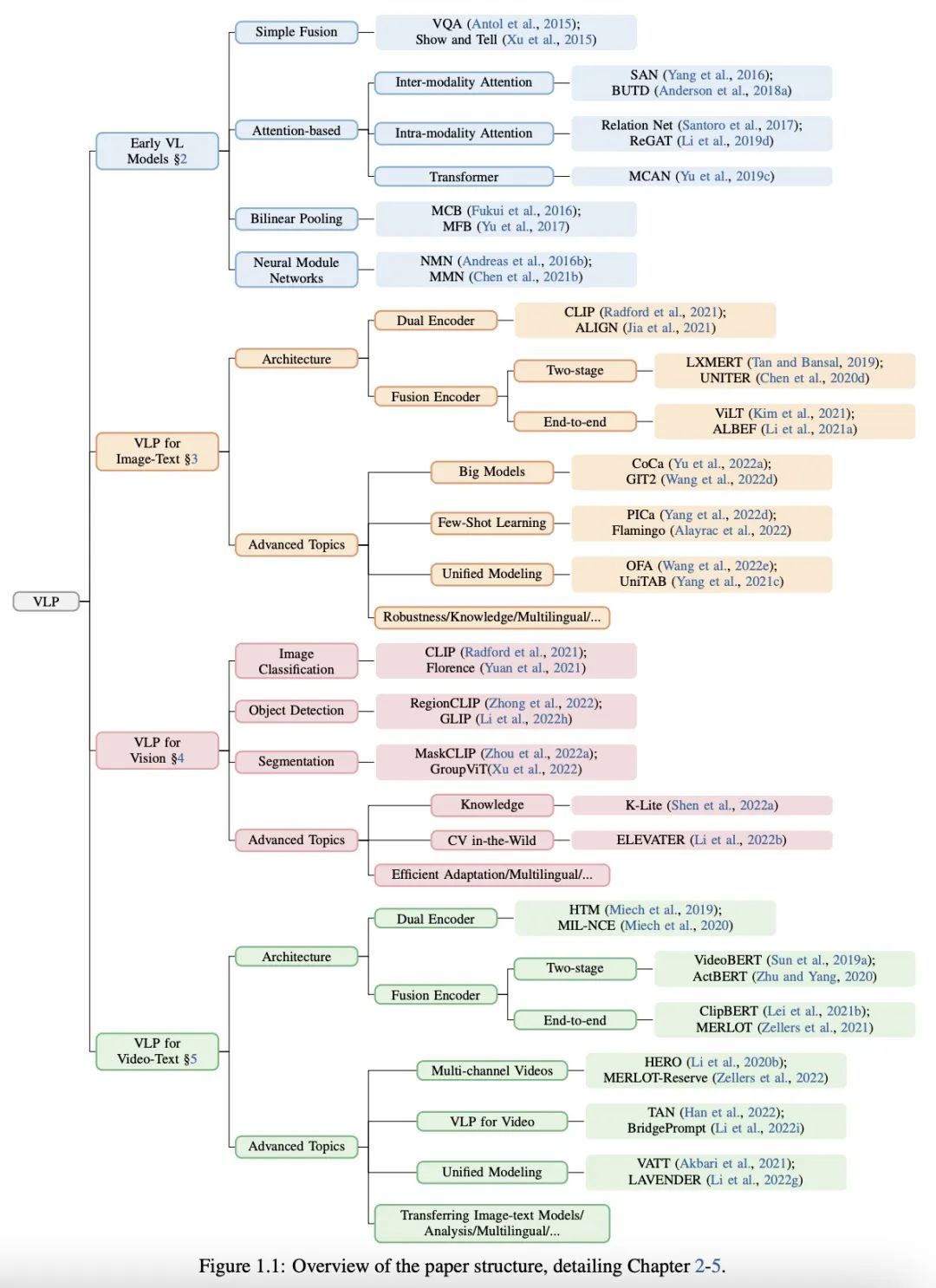
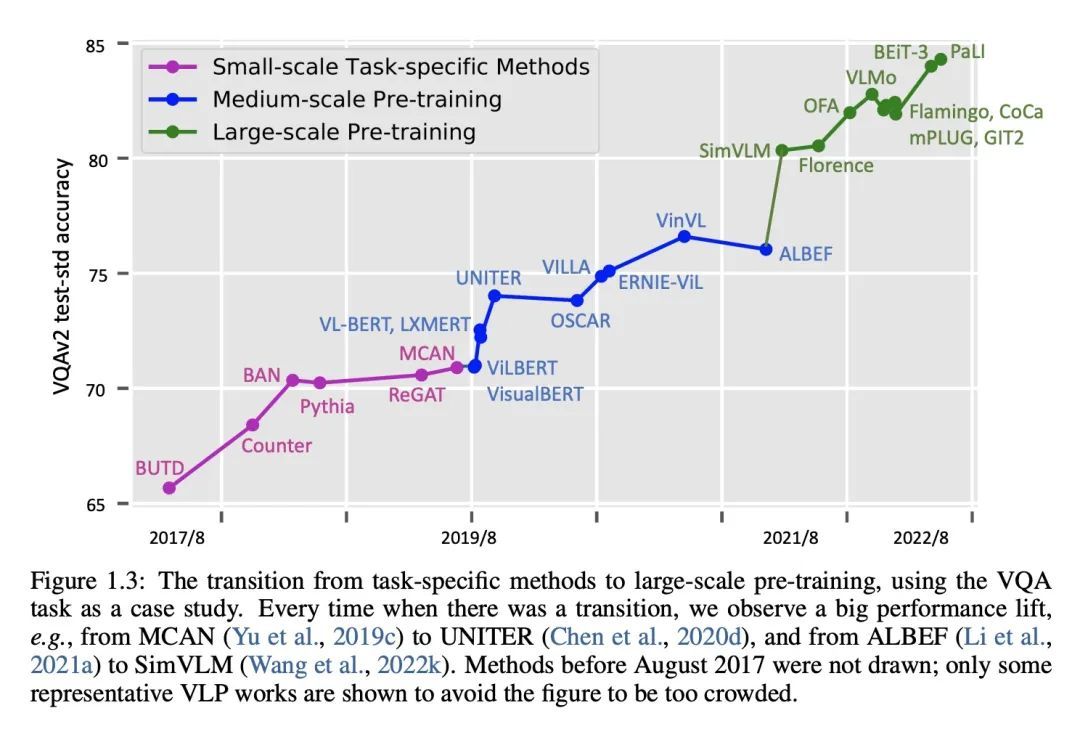
[CV] Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
视觉-语言预训练:基础、最新进展和未来趋势
Z Gan, L Li, C Li, L Wang, Z Liu, J Gao
[Microsoft Corporation]
https://arxiv.org/abs/2210.09263


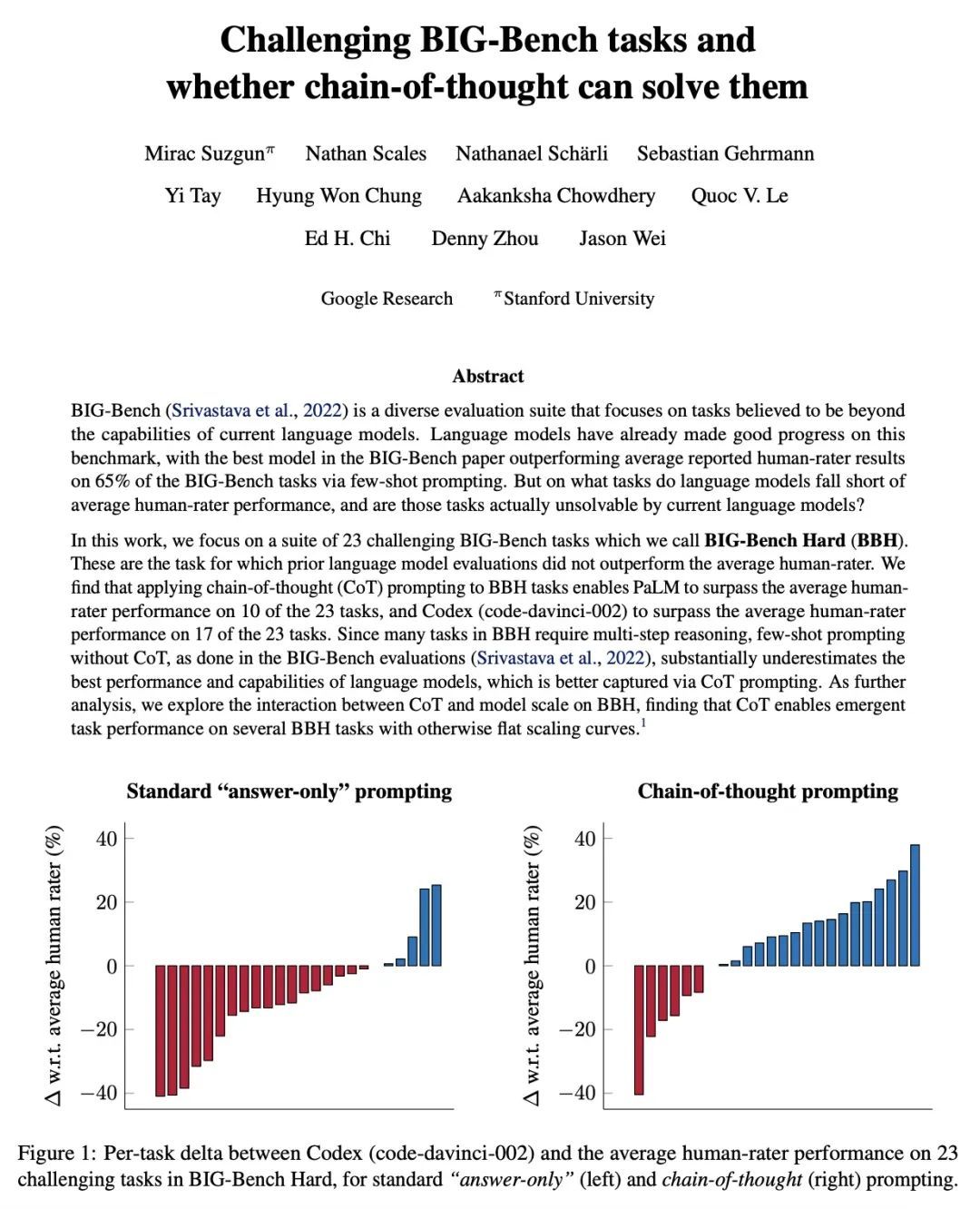
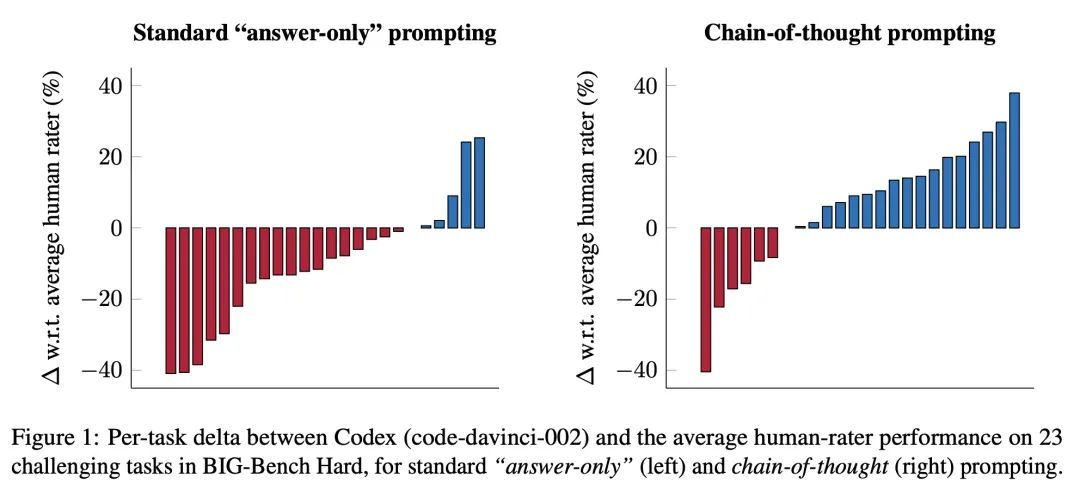
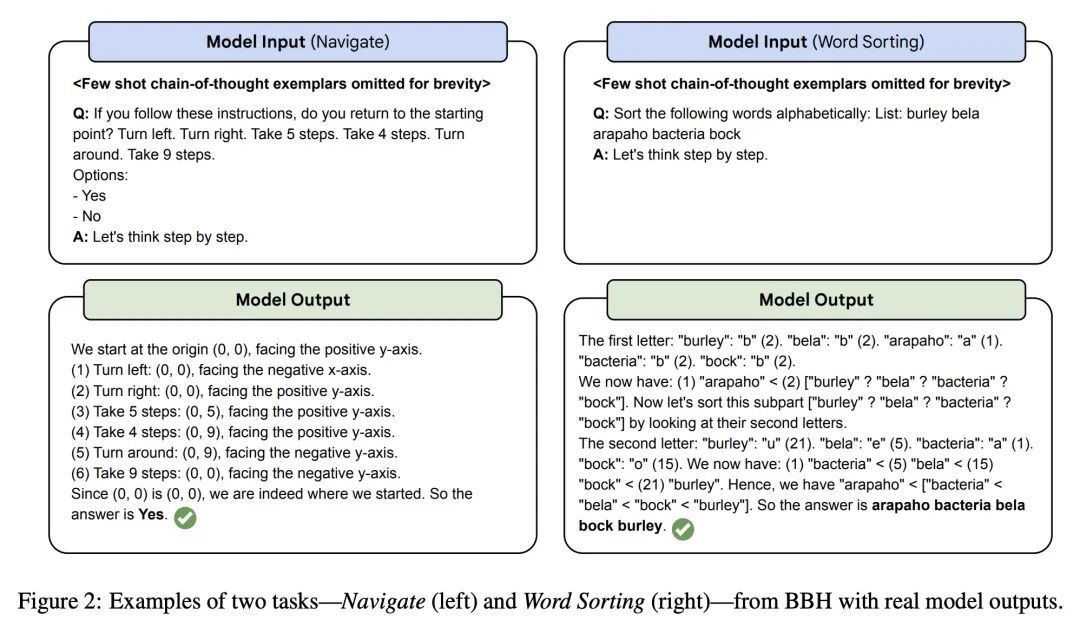
[CL] Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
用具有挑战性的BIG-Bench任务挑战思维链
M Suzgun, N Scales, N Schärli, S Gehrmann, Y Tay...
[Google Research & Stanford University]
https://arxiv.org/abs/2210.09261
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢