

论文链接:https://arxiv.org/pdf/2206.12559.pdf
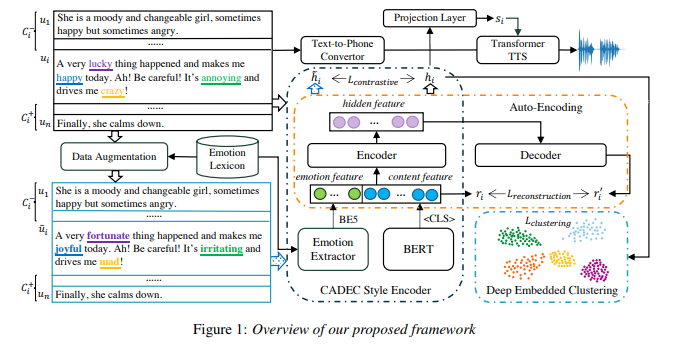
有表现力的语音合成在风格表征的学习和预测方面仍然面临较大的挑战。从参考语音中提取风格表征或从文本中预测风格标签需要大量的标记数据,获取这些数据成本高,且难以准确定义和标注。在本文中,我们提出了一个新的框架,以自监督学习的方式从丰富的纯文本数据中学习风格表征。进一步地,我们将风格表征作为条件信息加入到一个多风格的语音合成框架中,实现了有表现力的语音合成。我们在有声书生成场景中进行了人工评测,与一般的使用多风格标签的语音合成模型相比,我们的方法在多个数据集、多个说话人上实现了更好的效果。此外,通过使用隐式的上下文相关的风格表征,合成音频在长文本段落中的情感过渡更加自然。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢