

论文链接:https://arxiv.org/abs/2210.10163
代码链接:https://github.com/RyanWangZf/MedCLIP
导读
CLIP(Contrastive Language-Image Pre-training)即图文对比预训练,是这推动这两年多模态领域大火的奠基之作。相信大家都已经比较熟悉了。
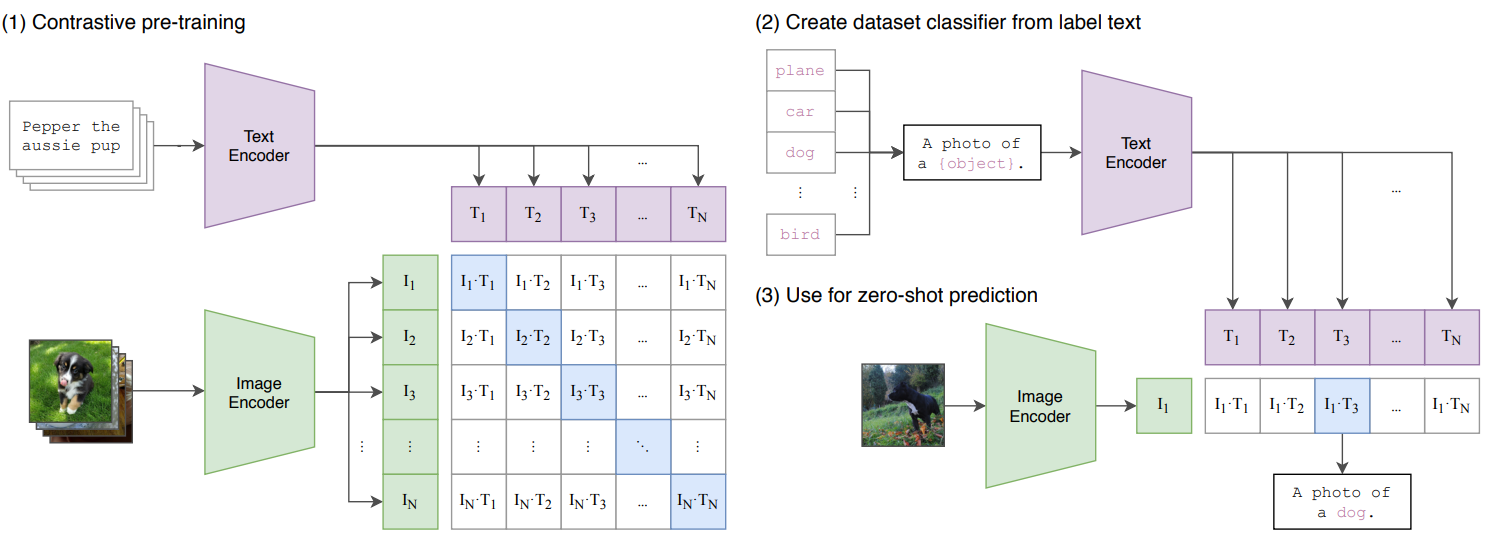
CLIP的示意图,来自原论文
在4亿个网络图片和对应的标题的加持下,CLIP使用简单的InfoNCE loss大力出奇迹,在多个图像识别任务上的零样本预测能力吊打了很多的监督学习模型。这个特性再次强化了我们对于深度学习more data, more intelligence的印象。紧接着,就出现了非常多在CLIP预训练模型的基础上整一些花活的文章,比如在视频文本上预训练,在音频文本上预训练,等等。
医疗相关也有可用的图像和文本的配对数据集。最知名的应该是一些列胸片和临床报告的配对数据,比如CheXpert, MIMIC-CXR等。早在CLIP之前,ConVIRT[2]就已经展示了InfoNCE式对比学习在医疗图文数据上的能力。但是不幸的是,由于数据不够大,表现不够excited,这篇文章没有搞出一个大新闻,最终才在今年的MLHC会议上发表。当时还让作为作者之一的Christopher Manning大佬发推吐槽了一番。
Manning关于ConVIRT的推特
简单来说,ConVIRT的思路和CLIP是一致的。在我们有胸片和对应的临床报告文本时,我们可以把每张胸片和对应的报告中的句子作为正样本对,而跟其他的报告中的句子作为负样本对。这样就可以在一个图片编码器(ResNet)和文本编码器(BERT)的加持下,愉快地做对比学习了。那么和CLIP不同的是,ConVIRT并没有考虑零样本预测的情况,而只是利用预训练的图片编码器加上一个全连接层做分类器,然后还是加标签数据做微调那一套。
在ConVIRT之后,Stanford又出了一篇GLoRIA[3],在之前工作的基础上加了很多注意力(attention)机制。即考虑了图像编码器中间层里的特征图和文本中每个词之前的attention,得到一个经过加权的局部特征(local representation)。相对应的就是原本的图像和文本特征,在文中叫做全局特征(global representation)。也是在这篇文章中,第一次实现了医疗图片在图文预训练之后的基于prompt的零样本预测。
方法
MedCLIP要解决的问题,我想可以用一张图说明。
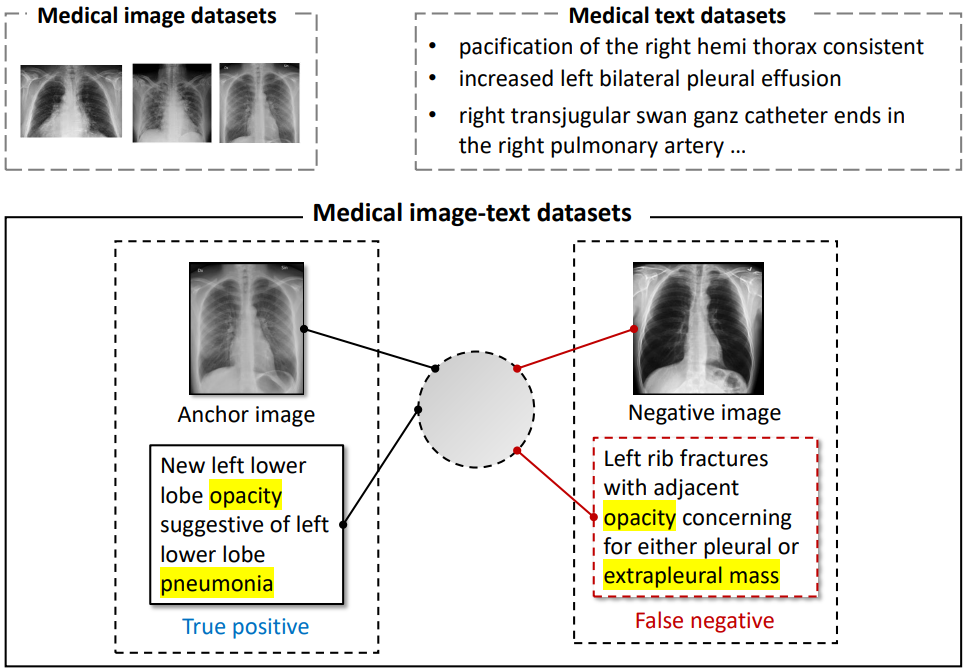
MedCLIP要解决的问题:(1)如何解决只能利用配对图文训练的限制;(2)如何解决由于只使用配对图文作为正样本带来的假阴性样本问题。
首先,跟CLIP相比,医疗领域的图像文本配对总量要小的多。CLIP可以在4亿数据上充分训练,但是,X-ray和配对的报告的公开数据集最大的也只有数十万这个级别,分别是CheXpert(20万)和MIMIC-CXR(37万)。这就严重限制了模型的能力。同时,我们其实还有大量的纯医疗图像或者纯文本数据。由于使用CLIP的对比学习方法,模型只能利用天生配对的图片+报告来训练。这就导致了医疗图文训练的天生在数据量方面的跛腿,从而很难达到CLIP那样的高度。
另外,由于假定只有配对的图片和文本是正样本,其它的都被当作负样本,很多的潜在正样本都被当作了负样本,即False Negatives。同CLIP使用的日常图文不同,X-rays之间的差别其实很小。在没有经过专业训练的普通人眼里几乎分辨不出来任何差别。并且,很多报告可能都描述了类似的症状和病情,但都被一律当作了负样本处理。这就导致了模型在训练过程中感觉到了疑惑:图片1和文本B明明匹配,却要求把它们的特征分开。这大大影响了学习到的表征的质量。
针对上面的这两个问题,我们希望能够解耦(decouple)图片和文本的配对关系,转而用一个人工构建的弱标签系统作为匹配图片和文本的工具。见下图。
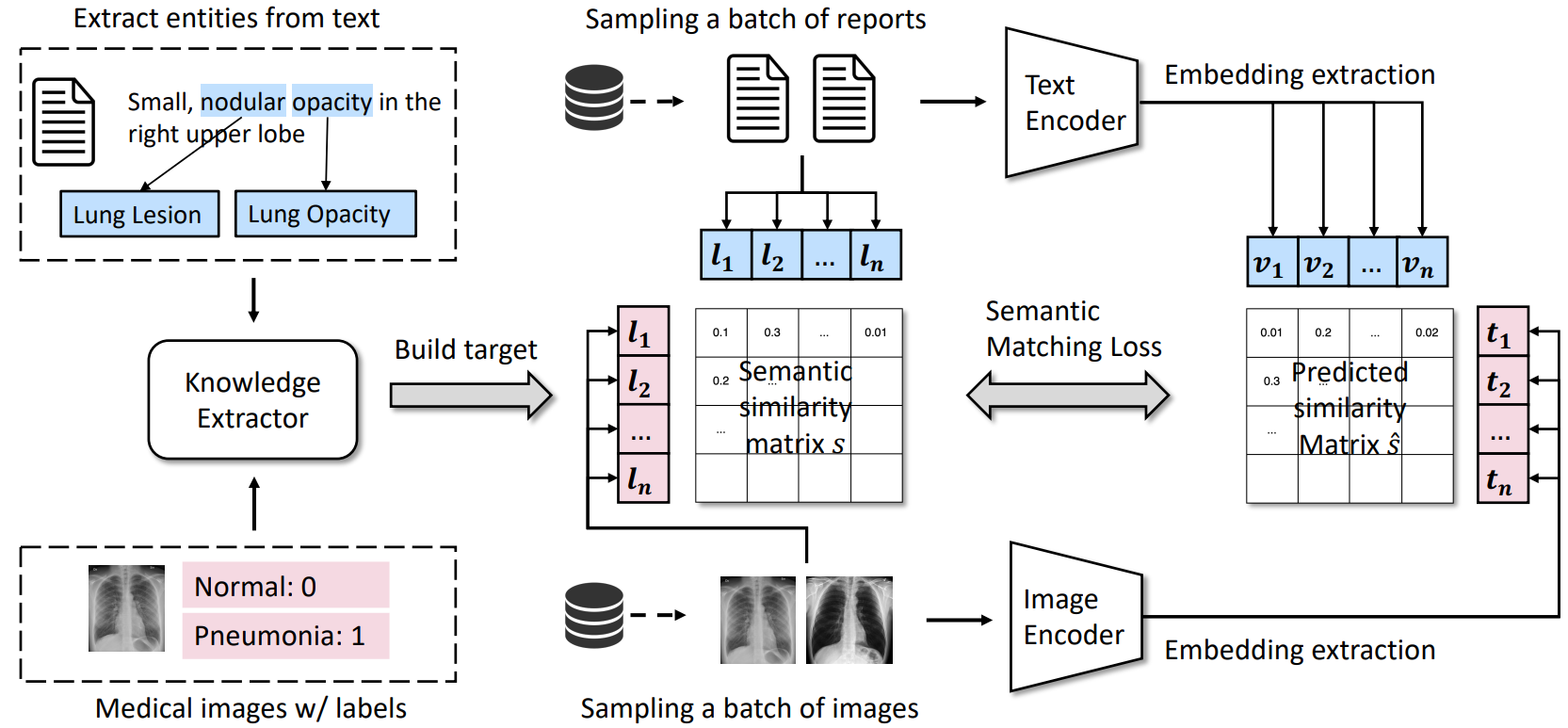
MedCLIP的基本架构
咱们这里主要关注最左边这一块。对于每条文本,我们都可以抽取它之中存在的一些关键实体,作为这条文本的弱标签。对于图片,我们有它们的标签,因为它们可能来源于已经标注好的纯图像数据集,或者有对应的报告,那么就用报告的标签作为它的标签。
在获得这两个标签后,对比学习的目标就不再是一个对角的identity矩阵,而是两个标签向量的内积,作为图片和文本之间的一个相似度。
实验
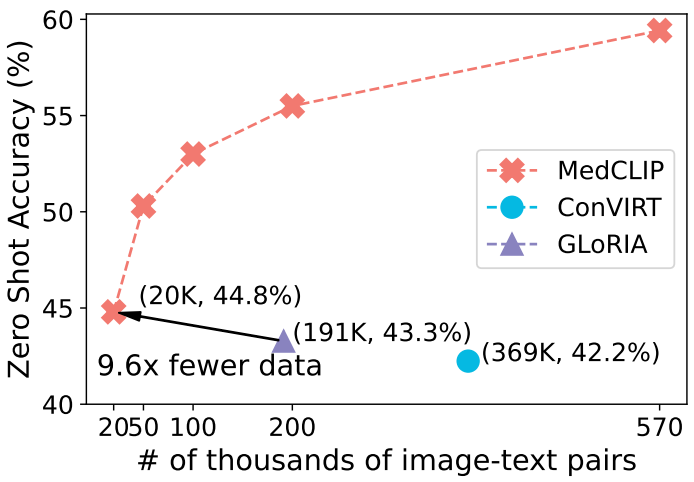
MedCLIP方法展现了惊人的数据效率(data efficiency):利用1/10的数据就可以达到之前sota方法的表现。
可以看到,相比GLoRIA[4],我们的方法在只用20K数据的时候就已经达到了更强的零样本预测能力。随着样本量的增大,MedCLIP的表现也在逐渐scale。可以期待如果更多的数据可用,它的表现还可以更好。值得注意的是,在我们的实验里,CheXpert+MIMIC-CXR作为预训练数据集。但是,因为MedCLIP的特性,我们还可以考虑加入更多的图片数据进来。
总结
这篇文章的方法和思想非常简单,就是一个利用外部知识来构建文本和图像的弱标签,从而能够解耦图片和文本对,做到指数级扩大可用的正负样本。同时,利用弱标签,我们能够甄别出很多的False Negative样本,从而提高模型的表征学习能力。
后续的工作可以考虑如何进一步提高弱标签的质量,以及在有噪弱标签的情况下进一步提高预训练的鲁棒性。或者,在模型架构主要是图片编码器一侧提升设计,让模型更多的抓住医疗图片的重要区域,从而提升表征的判别能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢