
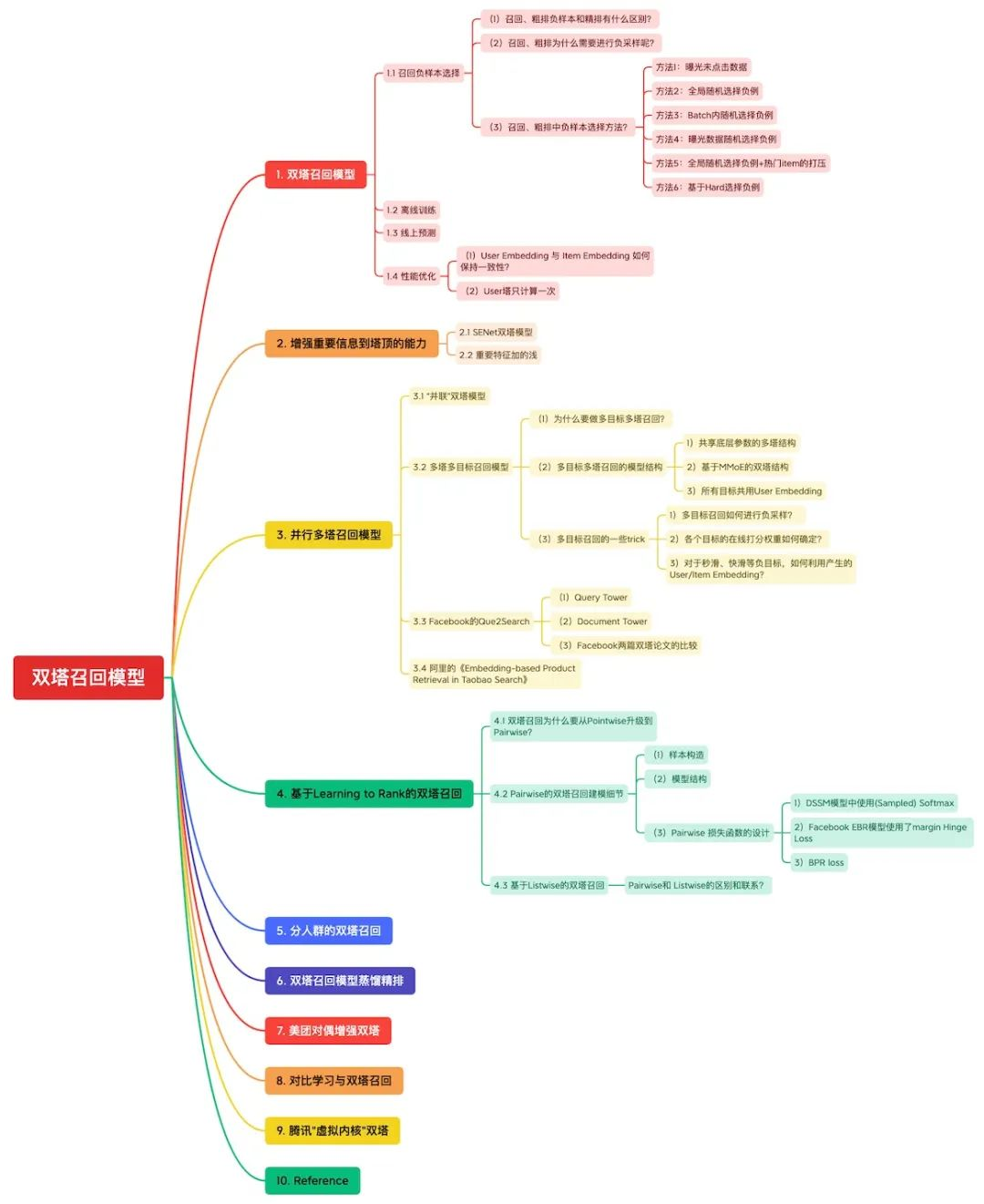
双塔各种改造方法概览:
大型推荐系统通常会将整个推荐链路拆分成召回、粗排、精排和重排等多个模块,以达到推荐效果和计算性能之间的平衡。由于召回模型的候选item通常是海量的全库物品、粗排模型的候选item是上百路召回合并后的物品集,在面临海量候选物品进行粗筛的场景下,双塔结构不仅排序速度快、模型线上效果也不差,且在工业界实战价值很高,因此双塔结构在召回和粗排环节的模型选型中被广泛采用。Microstrong从事推广搜行业也有数年,对双塔结构在工业界的落地及改造升级,并在线上拿到较高的业务增长,有些许的心得体会。本文是Microstrong对双塔模型在推荐系统召回阶段所看、所思、所做、所想的一些总结。
01. 双塔召回模型
我把双塔召回模型样本处理、离线训练、线上部署、性能优化总结如下:
1.1 召回负样本选择
如果说排序是特征的艺术,那么召回、粗排就是样本的艺术,特别是负样本的艺术。我这里提三个不做召回、粗排方向的同学经常会问的问题:
(1)召回、粗排负样本和精排有什么区别?
我们训练精排模型的时候(假设是优化点击目标),一般会用“用户点击”实例做为正例,“曝光未点击”实例做为负例,来训练模型,基本大家都是这么干的。现在,召回以及粗排,也需要训练模型,意思是说,也需要定义正例和负例。一般正例,也都是用“用户点击”实例做为正例,但是怎么选择负例,这里面有不少学问。
- 精排: 正样本为真实点击,负样本为真实曝光未点击。
- 粗排: 一般情况下和精排样本一致,但这会造成一个问题:粗排训练样本和实际线上打分样本分布不一致,训练样本仅是线上打分样本一个比较小的子集。面对这个问题大家通常的解法是,从精排未下发的样本里采一部分,添加至粗排模型的训练负样本中,会带来一定的提升。即粗排也需要进行负采样。
- 召回: 正样本为真实点击,负样本为真实曝光未点击+「负采样」。
(2)召回、粗排为什么需要进行负采样呢?
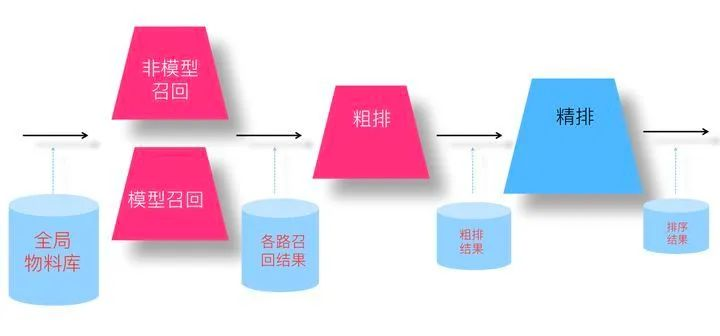
图来源:SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎https://zhuanlan.zhihu.com/p/358779957
我们先来看下不同阶段模型面对的输入数据情况,对于召回模型来说,它面临的输入数据,是所有物料库里的物品;对于粗排模型来说,它面对的输入数据,是各路召回的结果;对于精排模型来说,它面临的输入是粗排模型的输出结果。如果我们仍然用“曝光未点击”实例做为召回和粗排的负例训练数据,你会发现这个训练集合,只是全局物料库的一小部分,它的分布和全局物料库以及各路召回结果数据分布都不一致。召回和粗排模型面临的实际输入数据与“曝光未点击”作为负例的训练数据有较大的分布差异,所以只用“曝光未点击”这种负例训练召回和粗排模型,效果如何就带有疑问,我们一般把这个现象称为“Sample Selection Bias”问题。
可以看到召回、粗排是要做采样,其原因是:离线训练数据要和线上分布尽可能一致,虽然曝光未点击肯定是负样本,但是还有很多物品未曝光,同时因为推荐系统bias的存在可能某些样本你永远学不到,负采样的目的就是尽量符合线上真实分布,要让模型“见见世面“。
(3)召回、粗排中负样本选择方法?
「方法1:曝光未点击数据。」
常用的方式,但是会导致Sample Selection Bias。我们的经验是,这个数据还是需要的,只是要和其它类型的负样本选择方法,按照一定比例进行混合,来缓解Sample Selection Bias问题。当然,有些结论貌似是不用这个数据,所以用还是不用,可能跟应用场景有关。
「方法2:全局随机选择负例。」
从全局候选物料里面随机抽取item做为召回或者粗排的负例。例如经典论文《Deep Neural Networks for YouTube Recommendations》中的Youtube DNN模型。虽然保证了输入数据的分布一致性,但这么选择的负例和正例差异太大,导致模型太好区分,可能学到的知识不够充分。
「方法3:Batch内随机选择负例。」
输入数据只有用户点击物品的正样本。训练的时候,在Batch内随机采样一定比例除本item外的其它item作为当前用户的负样本。这个本质上是:给定用户,在所有其它用户的正例里进行随机选择,构造负例。它在一定程度上,也可以解决Sample Selection Bias问题。比如经典论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》中的Google双塔召回模型,就是用的这种负例方法。
《Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations》提出了一种混合采样的策略。负样本既包括batch内采样,即相当于做unigram分布采样,另外也会对全部物料做均匀分布的随机采样,同时混合两种样本。负样本同时拼接batch内负样本和随机负样本。通过这种方式来对负样本的分布进行调整。训练的时候,每个batch只采样一次并共享同一批负样本。
详细细节请参考:Google Play双塔召回算法 - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/533449018
「方法4:曝光数据随机选择负例。」
就是说,在给所有用户曝光的数据里,随机选择做为负例。这个我们测试过,在某些场景下是有效的。
「方法5:全局随机选择负例+热门item的打压。」
全局随机选择负例是:拿点击样本做正样本,拿从全局候选物料里面随机抽取item做为召回或粗排的负样本。这种负采样方法是有效的,因为线上召回时,候选库里大多数的物料是与用户八杆子打不着的,随机抽样能够很好地模拟这一分布。
但是这里要特别注意 “随机抽样的概率”,千万不要以为是在整个候选库里等概率抽样。在任何一个推荐系统中,都难逃“2-8”定律的影响,即20%的热门item占据了80%的曝光量或点击量,也就是少数热门物料占据了绝大多数的曝光与点击。
这样一来, 正样本被少数热门物料所绑架, 导致所有人的召回结果都集中于少数热门物料, 完全失去了个性化。因此, 当热门物料做正样本时, 要降采样, 减少对正样本集的绑架。比 如, 某 物 料 成 为 正 样 本的 概 率 \( P_{pos}(w_i)=(\sqrt{\frac{z(w_i)}{\alpha}}+1)\frac{\alpha}{z(w_i)} \),其 中 \( z(w_i)=\frac{\text{点击过} w_{i} \text{的用户数}}{\text{同时段所有发生过点击行为的用户总数}} \) ,α 是一个超参一般在1e-3~1e-5之间。
当热门物料做负样本时, 就要提升热门item成为负样本的概率。可以从两个角度来理解:
- 既然热门item已经 “绑架”了正样本集, 我们也需要提高热门item在负样本集中的比例, 以抵销热门item对loss的影响;
- 如果在采样生成负样本时采取uniform sampling, 因为有海量的候选item, 而采样量有限, 因此极有可能采样得到的item与 user“八杆子打不着”, 即所谓的easy negative。而如果多采集一些热门item当负样本, 因为绝大多数用户都喜欢热门item, 这样采集到的负样本是所谓的hard negative, 会极大地提升模型的分辨能力。
有NLP背景的同学会发现,以上采集正负item时所使用概率公式,与word2vec中所使用公式一模一样。没错,Language Model中根据“上下文”预测“缺失词”的问题,其实就可以看成一个召回问题。因此,word2vec中处理高频词的方式,也可以拿来为我们所用,在召回中打压高热item。
「方法6:基于Hard选择负例。」
Hard Negative能够增加模型在训练时的难度,让模型关注细节。Airbnb根据业务逻辑来选取Hard Negative:
- 增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,加大了模型的学习难度。
- 增加“被房主拒绝”作为负样本,增强了正负样本在“匹配用户兴趣爱好”上的相似性,加大了模型的学习难度。
2020年Facebook的论文《Embedding-based Retrieval in Facebook Search》提出拿召回位置在101~500上的物料作为Hard Negative Sample,排名太靠前那是正样本,不能用;太靠后,与随机无异,也不能用;只能取中段。也可以将排序模型打分靠后的作为Hard Negtive,但是选择100-200还是300-500就只能去尝试了。
「【推荐阅读】」
负样本为王:评Facebook的向量化召回算法 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/165064102
SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/358779957
模型利器 - 召回/排序中的负样本优化方法 - 十三的文章 - 知乎 https://zhuanlan.zhihu.com/p/453776850
召回和粗排负样本构造问题 - Louis的文章 - 知乎 https://zhuanlan.zhihu.com/p/352961688
召回模型中的负样本构造 - iwtbs的文章 - 知乎 https://zhuanlan.zhihu.com/p/358450850
推荐系统传统召回是怎么实现热门item的打压? - 石塔西的回答 - 知乎 https://www.zhihu.com/question/426543628/answer/1631702878
Google Play双塔召回算法 - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/533449018
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢