
转自:爱可可爱生活
摘要:基于细粒度和粗粒度注意力Transformer的音乐生成、基于表示学习的现实世界泛化、基于测量和语义属性的精确3D体形回归、来自点云的角色网格运动感知装配、基于Token合并的ViT加速、催化神经AI革命、奖励模型过度优化缩放律、面向3D生成建模的不规则潜网格、生成对抗网络的通用域自适应
1、[AS] Museformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
B Yu, P Lu, R Wang, W Hu, X Tan, W Ye...
[Nanjing University & Microsoft Research Asia & Peking University]
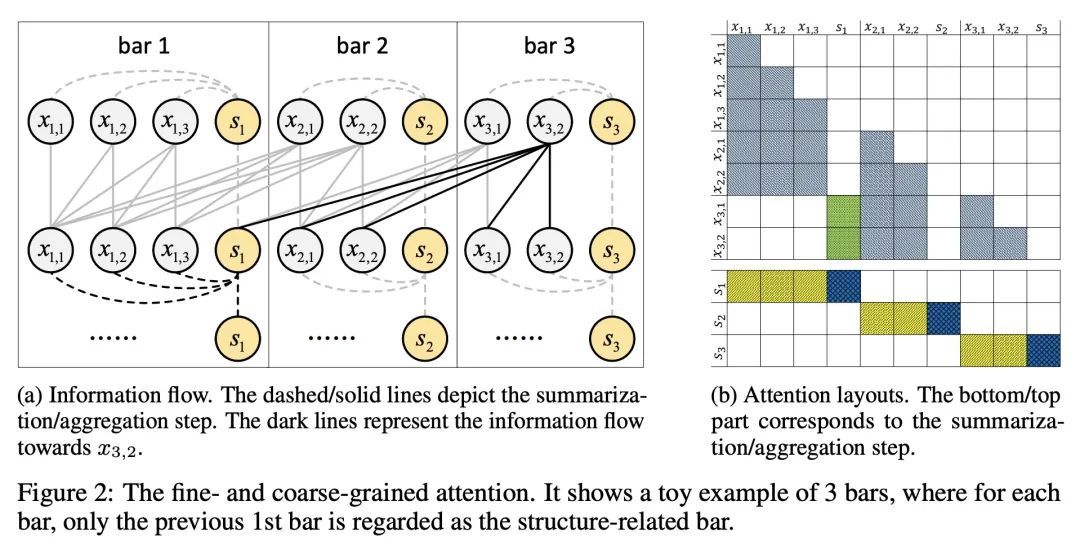
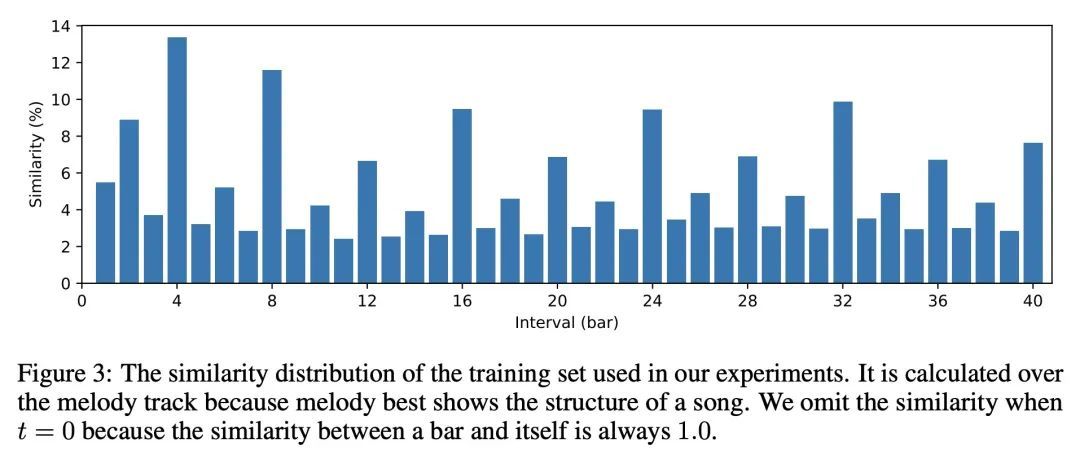
Museformer:基于细粒度和粗粒度注意力Transformer的音乐生成。符号化音乐生成的目的是自动生成乐谱。最近的一个趋势是在音乐生成中用Transformer或其变体,然而,这是次优的,因为全注意力不能有效地对典型的长音乐序列(例如,超过10,000个token)进行建模,而且现有的模型在生成音乐重复结构方面有缺陷。本文提出Museformer,一种基于新的细粒度和粗粒度注意力的音乐生成的Transformer。在细粒度注意力下,一个特定小节的token直接关注与音乐结构最相关的所有小节的token)例如,通过相似性统计选择的前1、2、4和8小节);在粗粒度注意力下,一个token只关注其他小节的总结,而不是其中的每个token,以减少计算成本。其优点是双重的。首先,可以通过细粒度的注意力捕捉与音乐结构有关的相关性,并通过粗粒度的注意力捕捉其他上下文信息。其次,它是高效的,与全注意力方法相比,可以对超过3倍的音乐序列进行建模。客观和主观的实验结果都表明,Museformer有能力生成具有高质量和更好结构的长音乐序列。
Symbolic music generation aims to generate music scores automatically. A recent trend is to use Transformer or its variants in music generation, which is, however, suboptimal, because the full attention cannot efficiently model the typically long music sequences (e.g., over 10,000 tokens), and the existing models have shortcomings in generating musical repetition structures. In this paper, we propose Museformer, a Transformer with a novel fine- and coarse-grained attention for music generation. Specifically, with the fine-grained attention, a token of a specific bar directly attends to all the tokens of the bars that are most relevant to music structures (e.g., the previous 1st, 2nd, 4th and 8th bars, selected via similarity statistics); with the coarse-grained attention, a token only attends to the summarization of the other bars rather than each token of them so as to reduce the computational cost. The advantages are two-fold. First, it can capture both music structure-related correlations via the fine-grained attention, and other contextual information via the coarse-grained attention. Second, it is efficient and can model over 3X longer music sequences compared to its full-attention counterpart. Both objective and subjective experimental results demonstrate its ability to generate long music sequences with high quality and better structures.
https://arxiv.org/abs/2210.10349


2、[LG] Generalizing in the Real World with Representation Learning
T Maharaj
[Université de Montréal]
基于表示学习的现实世界泛化。机器学习(ML)将让计算机从经验中学习的问题正式化为根据一组数据实例的某些指标对性能进行优化。这与要求事先指定的行为(例如,通过硬编码的规则)形成对比。这个问题的形式化使许多对现实世界有巨大影响的应用取得了巨大进展,包括翻译、语音识别、自动驾驶汽车和药物发现。但这一形式化的实际实例提出了许多假设——例如,数据是i.i.d.:独立同分布——其合理性很少被深究。在如此短的时间内取得了巨大的进展,该领域已经开发了许多规范和临时标准,集中在相对较小的问题设置范围内。随着机器学习的应用,特别是在人工智能(AI)系统中的应用,在现实世界中变得越来越普遍,需要批判性地检查这些假设、规范和问题设置,以及已经成为事实标准的方法。对于用随机梯度下降法训练的深度网络如何以及为什么能像它们那样泛化,为什么它们在泛化时失败,以及它们在分布外数据上的表现如何,仍有很多不了解。本文介绍了为更好理解深度网络泛化所做的一些工作,确定了几种假设和问题设置无法泛化到现实世界的方式,并提出了在实践中解决这些失败的方法。
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.
https://arxiv.org/abs/2210.09925

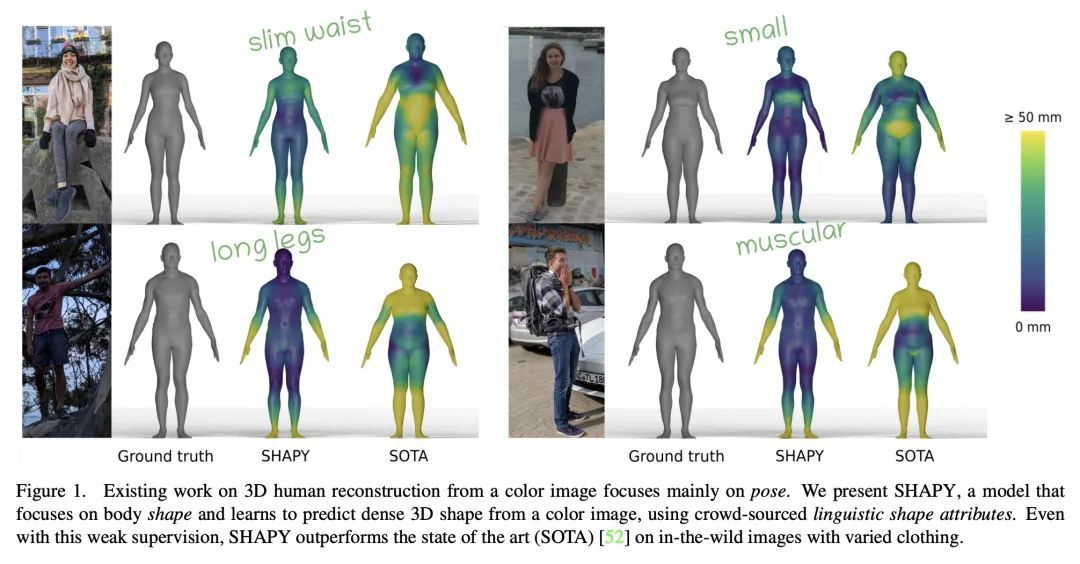
3、[CV] Accurate 3D Body Shape Regression Using Metric and Semantic Attributes
V Choutas, L Müller, CHP Huang, S Tang, D Tzionas…
[Max Planck Institute for Intelligent Systems & ETH Zurich]
基于测量和语义属性的精确3D体形回归。虽然从图像中回归3D人体网格的方法进展迅速,但估计的身体形状往往不能捕捉到真实的形状。这是一个问题,因为对于许多应用来说,准确的体形和姿态一样重要。体形精度落后于姿态精度的关键原因是缺乏数据。人工可以标记3D关节而这些关节制约着3D姿态,但要"标记"3D体形却不那么容易。由于图像和3D体形的配对数据很少,本文利用了两个信息来源:(1)收集了各种"时尚"模型的互联网图像以及一小部分人体测量数据;(2)收集了各种3D身体网格和模型图像的语言学形状属性。总之,这些数据集为推断密集的3D形状提供了足够的约束。以几种新的方式利用人体测量和语言形状属性来训练一个神经网络,称为SHAPY,可以从RGB图像中回归3D人体姿态和形状。在公共基准上评估SHAPY,但注意到它们要么缺乏显著的身体形状变化、真实形状或服装变化。因此,本文收集了一个新的数据集来评估3D人体形状估计,称为HBW,包含"实际场景人体"的照片,带有真实的3D身体扫描。在这个新基准上,SHAPY在3D人体形状估计的任务上明显优于最先进的方法。本文第一次证明,从图像中进行的3D体形回归可以从容易获得的人体测量和语言形状属性中进行训练。
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
https://openaccess.thecvf.com/content/CVPR2022/html/Choutas_Accurate_3D_Body_Shape_Regression_Using_Metric_and_Semantic_Attributes_CVPR_2022_paper.html


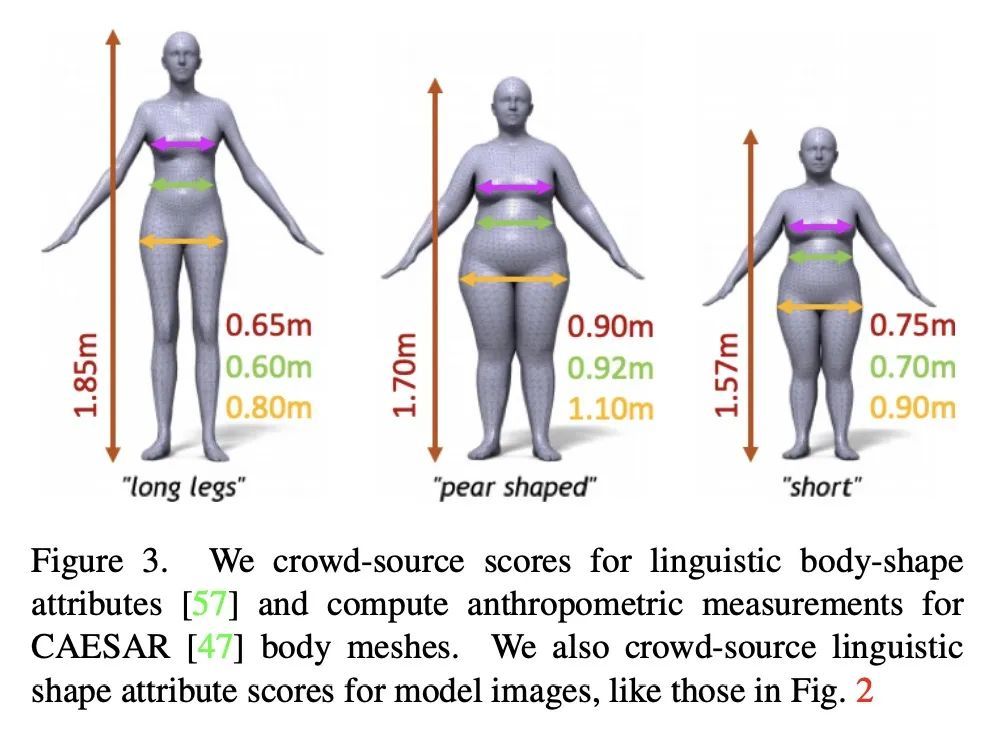
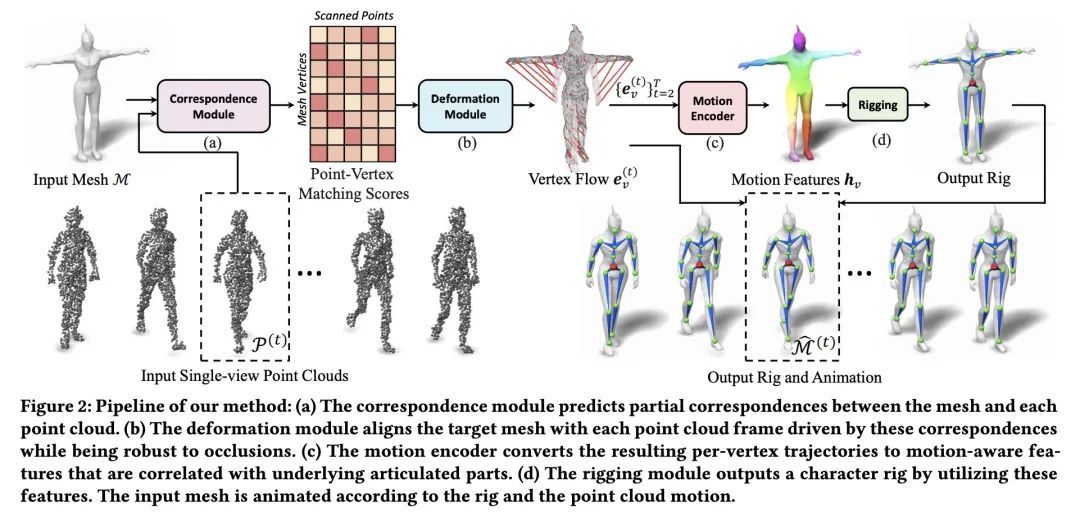
4、[CV] Morig: Motion-aware rigging of character meshes from point clouds
Z Xu, Y Zhou, L Yi, E Kalogerakis
[UMass Amherst & Adobe Research & Tsinghua University]
Morig: 来自点云的角色网格运动感知装配。本文提出MoRig,一种由捕捉表演角色运动的单视角点云流驱动的自动装配角色网格的方法,能根据捕获的点云运动对3D网格进行动画处理。MoRig的神经网络将点云中的运动线索编码为关于表演人物的铰接部分的信息特征。这些运动感知特征指导推断出适合输入网状结构的骨架,然后根据点云运动进行动画处理。该方法可以为不同的角色提供装备和动画,包括具有不同关节的类人动物、四足动物和玩具。考虑到了点云中的遮挡区域以及输入的网格和捕获的角色之间的零件比例不匹配。与其他忽略运动线索的装配方法相比,MoRig能产生更精确的装配,非常适合于从捕获的角色中重新定位运动。
We present MoRig, a method that automatically rigs character meshes driven by single-view point cloud streams capturing the motion of performing characters. Our method is also able to animate the 3D meshes according to the captured point cloud motion. MoRig's neural network encodes motion cues from the point clouds into features that are informative about the articulated parts of the performing character. These motion-aware features guide the inference of an appropriate skeletal rig for the input mesh, which is then animated based on the point cloud motion. Our method can rig and animate diverse characters, including humanoids, quadrupeds, and toys with varying articulation. It accounts for occluded regions in the point clouds and mismatches in the part proportions between the input mesh and captured character. Compared to other rigging approaches that ignore motion cues, MoRig produces more accurate rigs, well-suited for re-targeting motion from captured characters.
https://arxiv.org/abs/2210.09463



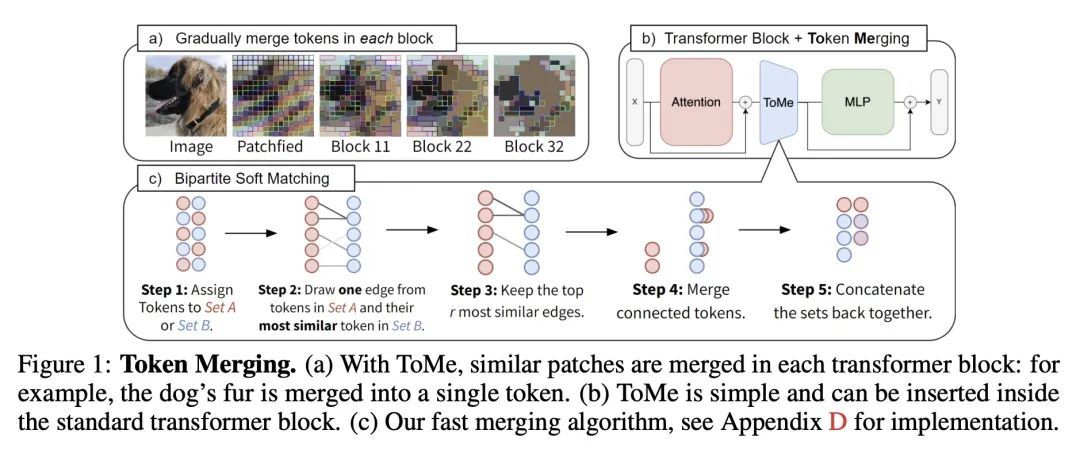
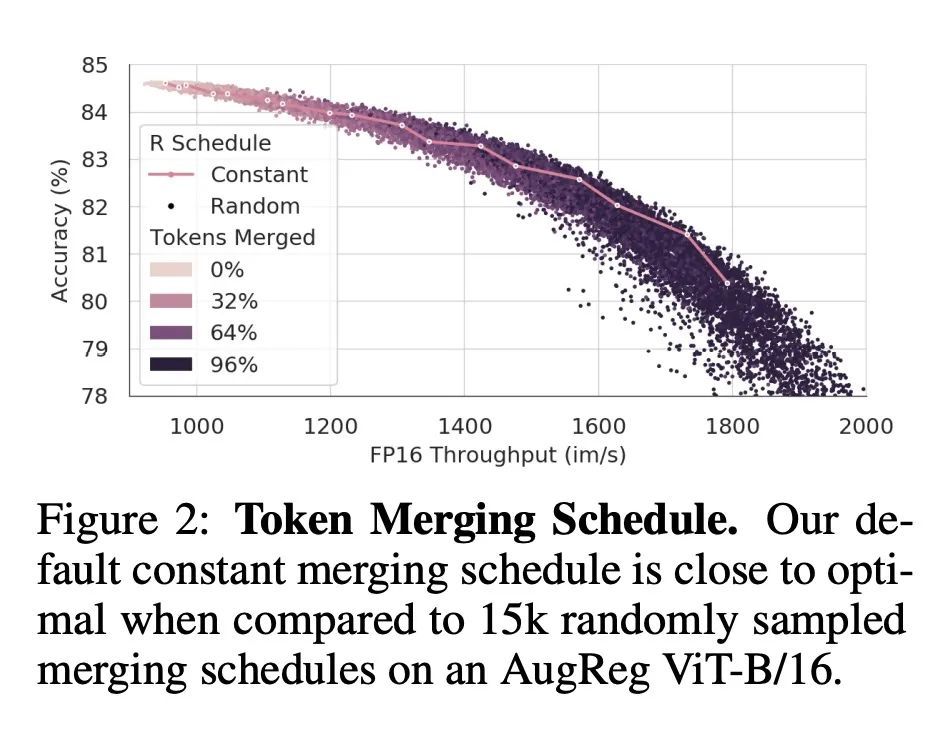
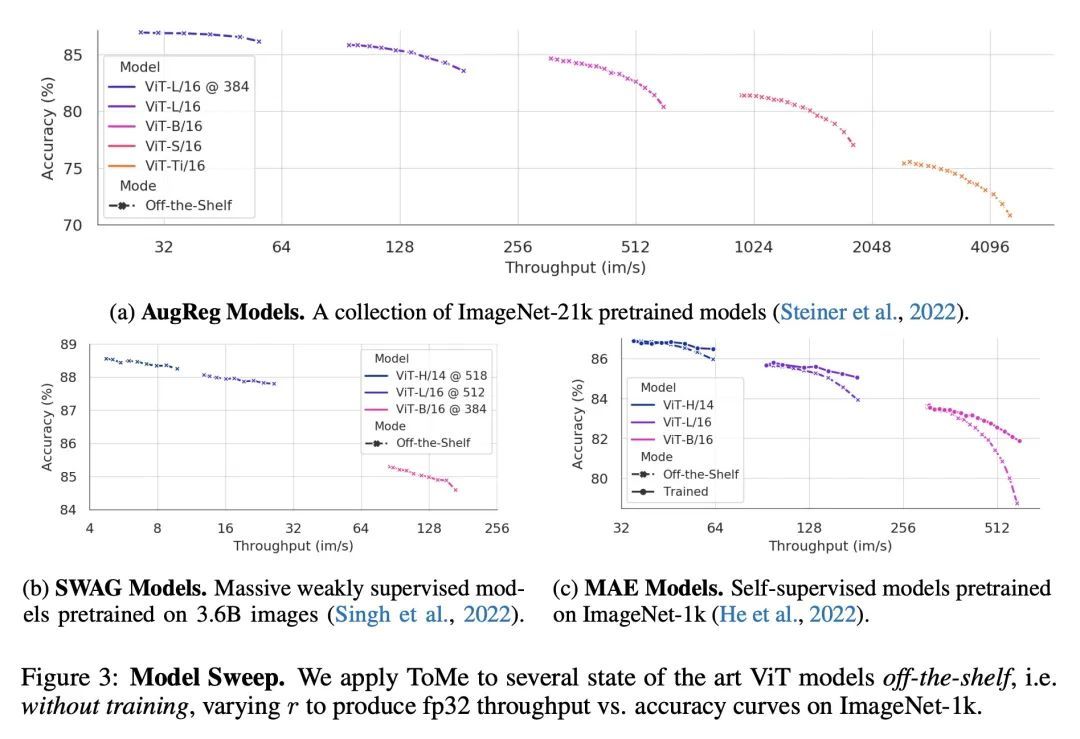
5、[CV] Token Merging: Your ViT But Faster
D Bolya, C Fu, X Dai, P Zhang, C Feichtenhofer, J Hoffman
[Meta AI & Georgia Tech]
基于Token合并的ViT加速。本文提出Token Merging (ToMe),一种简单的方法,可以提高现有ViT模型的吞吐量,而不需要进行训练。ToMe用一种通用的、轻量级的匹配算法,在一个Transformer中逐渐结合相似的token,其速度与修剪算法一样快,同时更准确。现成的ToMe在图像上的吞吐量是最先进的ViT-L @ 512和ViT-H @ 518模型的2倍,在视频上的吞吐量是ViT-L的2.2倍,而在每种情况下,准确率只下降0.2-0.3%。ToMe也可以很容易地在训练中应用,在实际训练中,对视频的MAE微调速度提高了2倍。用ToMe进行训练可以进一步减少准确率的下降,从而使ViT-B在音频上的吞吐量达到2倍,而MAP的下降只有0.4%。从质量上看,ToMe将物体部分合并为一个token,即使是在多帧视频中。总的来说,ToMe的准确性和速度在图像、视频和音频上都能与最先进的技术竞争。
We introduce Token Merging (ToMe), a simple method to increase the throughput of existing ViT models without needing to train. ToMe gradually combines similar tokens in a transformer using a general and light-weight matching algorithm that is as fast as pruning while being more accurate. Off-the-shelf, ToMe can 2x the throughput of state-of-the-art ViT-L @ 512 and ViT-H @ 518 models on images and 2.2x the throughput of ViT-L on video with only a 0.2-0.3% accuracy drop in each case. ToMe can also easily be applied during training, improving in practice training speed up to 2x for MAE fine-tuning on video. Training with ToMe further minimizes accuracy drop, leading to 2x the throughput of ViT-B on audio for only a 0.4% mAP drop. Qualitatively, we find that ToMe merges object parts into one token, even over multiple frames of video. Overall, ToMe's accuracy and speed are competitive with state-of-the-art on images, video, and audio.
https://arxiv.org/abs/2210.09461

另外几篇值得关注的论文:
[AI] Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
迈向下一代人工智能:催化神经AI革命
A Zador, B Richards, B Ölveczky, S Escola, Y Bengio, K Boahen... https://arxiv.org/abs/2210.08340

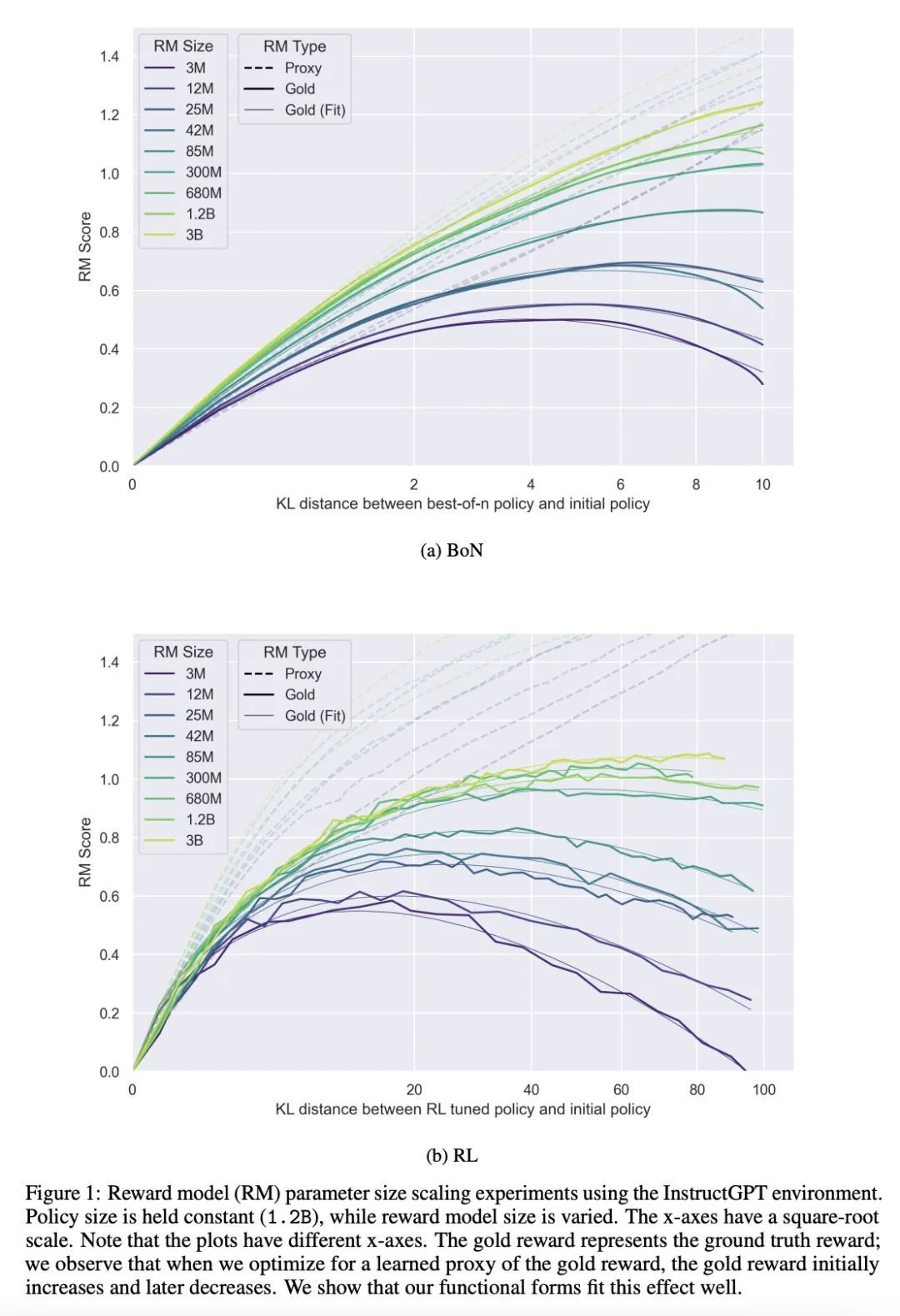
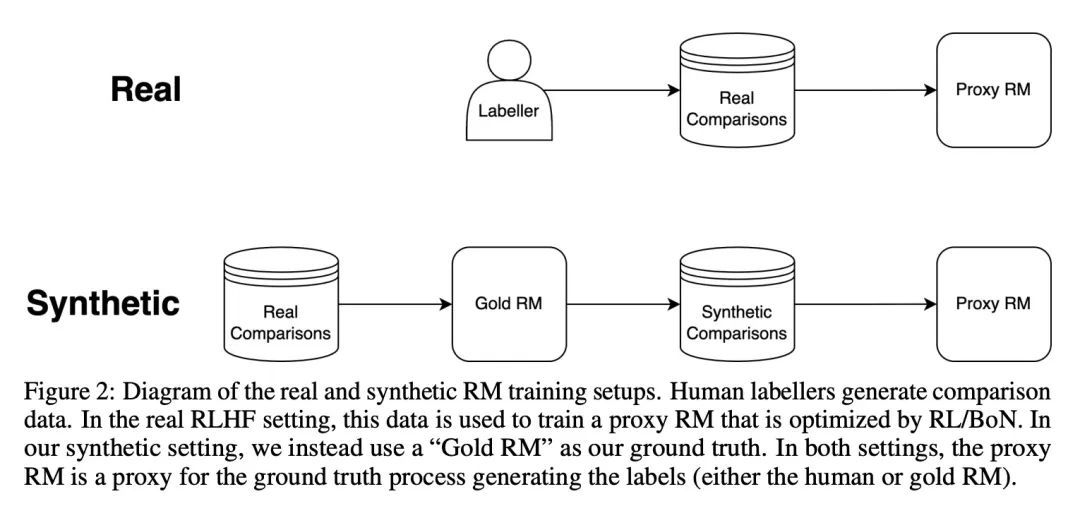
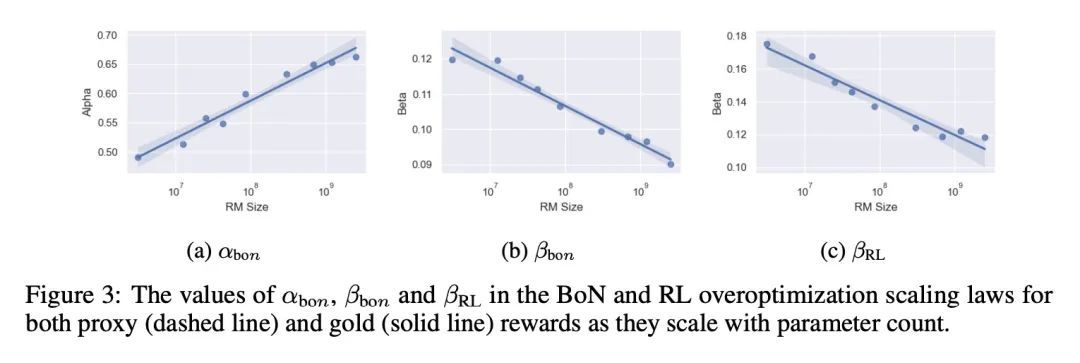
[LG] Scaling Laws for Reward Model Overoptimization
奖励模型过度优化缩放律
L Gao, J Schulman, J Hilton
[OpenAI]
https://arxiv.org/abs/2210.10760

[CV] 3DILG: Irregular Latent Grids for 3D Generative Modeling
3DILG:面向3D生成建模的不规则潜网格
B Zhang, M Nießner, P Wonka
[KAUST & Technical University of Munich]
https://arxiv.org/abs/2205.13914




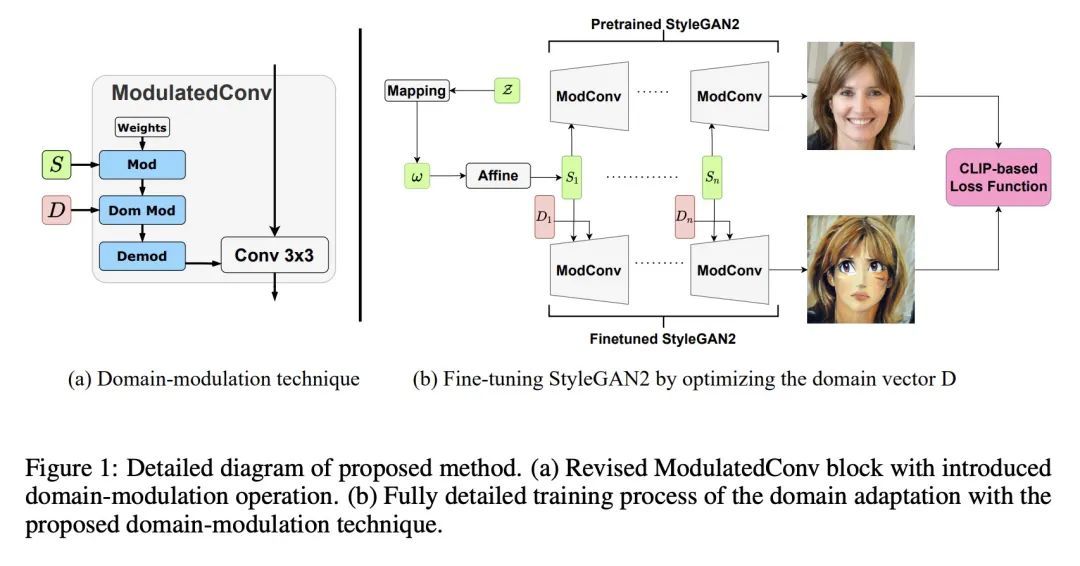
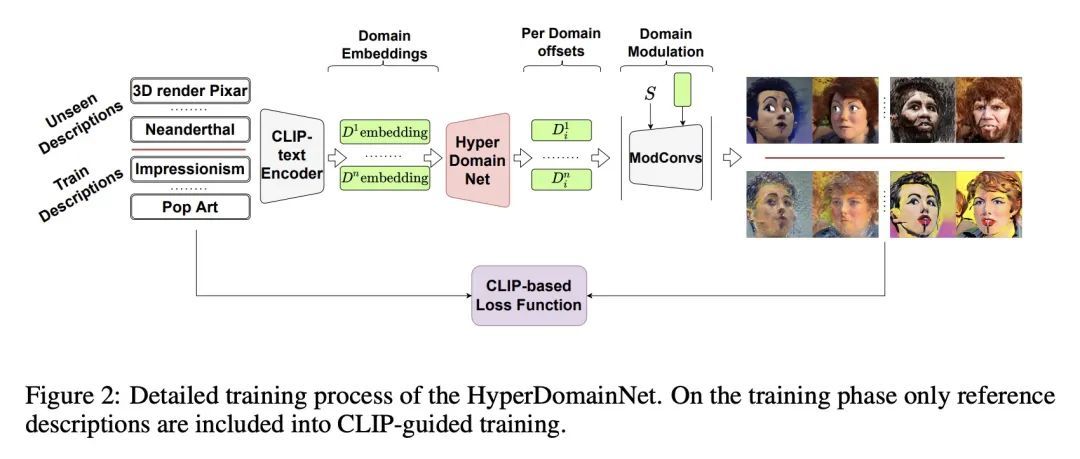
[CV] HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks
HyperDomainNet:生成对抗网络的通用域自适应
A Alanov, V Titov, D Vetrov
[HSE University & MIPT]
https://arxiv.org/abs/2210.08884

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢