
作者:Digbalay Bose , Rajat Hebbar , Krishna Somandepalli ,等
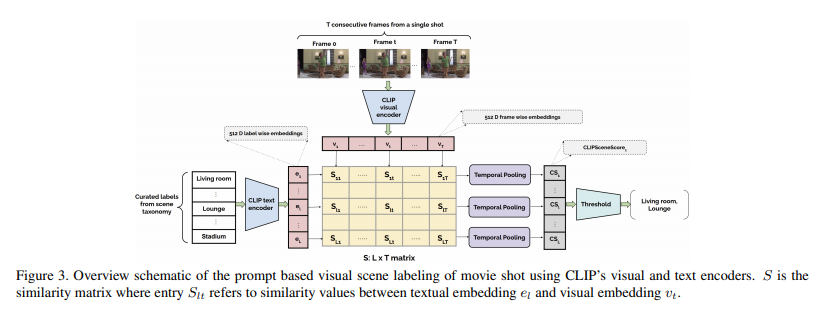
简介:本文研究视觉场景转换任务、并提出具有复杂叙事结构的电影数据集MovieCLIP。电影等长篇媒体具有复杂的叙事结构,其事件跨越了丰富多样的环境视觉场景。与电影中的视觉场景相关的特定领域挑战包括过渡、人物覆盖以及各种现实生活和虚构场景。电影中现有的视觉场景数据集分类有限,不考虑电影剪辑中的视觉场景转换。在这项工作中,作者首先自动策划一个新的、广泛的、以电影为中心的分类法,该分类法包含从电影剧本和辅助的基于网络的视频数据集派生的 179 个场景标签。基于本文提出的分类方法,作者使用CLIP对32K电影剪辑中的112万个镜头进行弱标记,而不是昂贵的手动注释。作者提供弱标记数据集(将该数据集命名为:MovieCLIP)上训练的基线视觉模型,并在由人类评估者验证的独立数据集上对其进行评估。实验表明:利用在 MovieCLIP 上预训练的模型的特征有利于下游任务(如网络视频和电影预告片的多标签场景和类型分类)。

论文下载:https://arxiv.org/pdf/2210.11065.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢