
作者:Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, 等
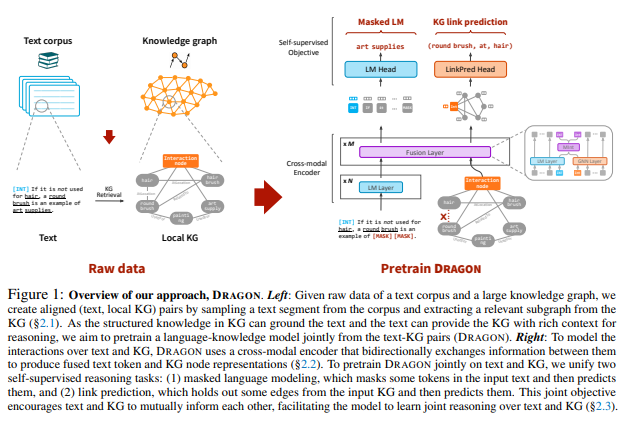
简介:本文研究文本和知识图谱大规模预训练深度联合的模型。已证明对文本进行语言模型 (LM) 预训练有助于各种下游 NLP 任务。最近的工作表明,知识图谱 (KG) 可以补充文本数据,提供结构化的背景知识,为推理提供有用的支撑。然而,这些作品并未经过预训练以大规模学习这两种模式的深度融合,从而限制了获得文本和 KG 完全联合表示的潜力。在本文,作者提出了 深度双向语言知识图谱预训练(DRAGON),一种自我监督的方法、用于从文本和 KG 大规模预训练深度联合语言知识基础模型。具体来说,作者的模型将成对的文本段和相关的 KG 子图作为输入,并双向融合来自两种模式的信息。作者通过统一两个自监督推理任务来预训练这个模型,掩码语言建模和知识图谱链接预测。DRAGON 在各种下游任务(包括一般和生物医学领域的问答)上优于现有的 LM 和 LM+KG 模型,平均绝对增益为 +5%。特别是,DRAGON 在关于语言和知识的复杂推理(在涉及长上下文或多步推理的问题上 +10%)和低资源 QA(在 OBQA 和 RiddleSense 上 +8%)和新的状态方面取得了显着的性能 。

论文下载:https://arxiv.org/pdf/2210.09338.pdf
代码下载:https://github.com/michiyasunaga/dragon
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢