
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于相对表示的零样本潜空间沟通、图神经网络可以生成哪些函数、基于TabT5的表格到文本生成和预训练、基于等变去噪扩散概率模型的蛋白质结构和序列生成、语言模型能从上下文解释中学习吗、神经元网络的优化和泛化、面向歌唱语音神经声码器的分层扩散模型、基于几何深度学习的基于结构药物设计、长期对话的记忆管理
1、[LG] Relative representations enable zero-shot latent space communication
L Moschella, V Maiorca, M Fumero, A Norelli, F Locatello, E Rodolà
[Sapienza University of Rome & Amazon Web Services]
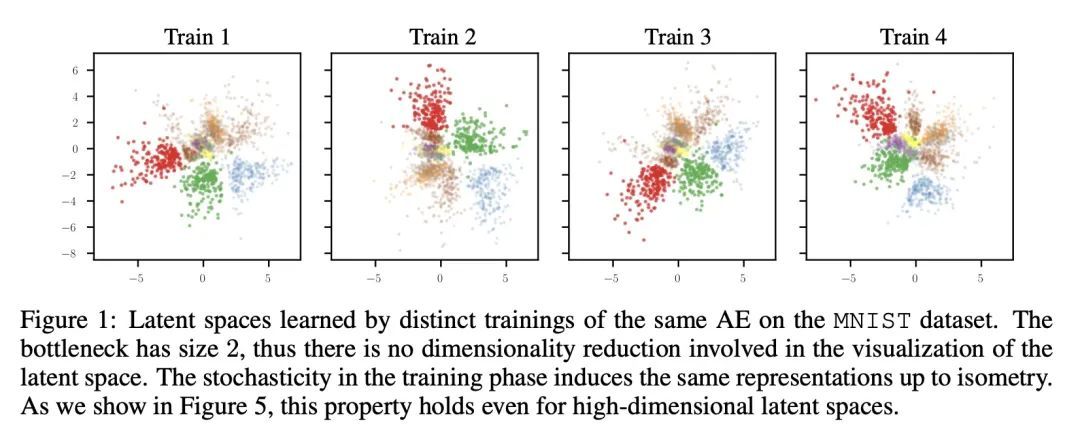
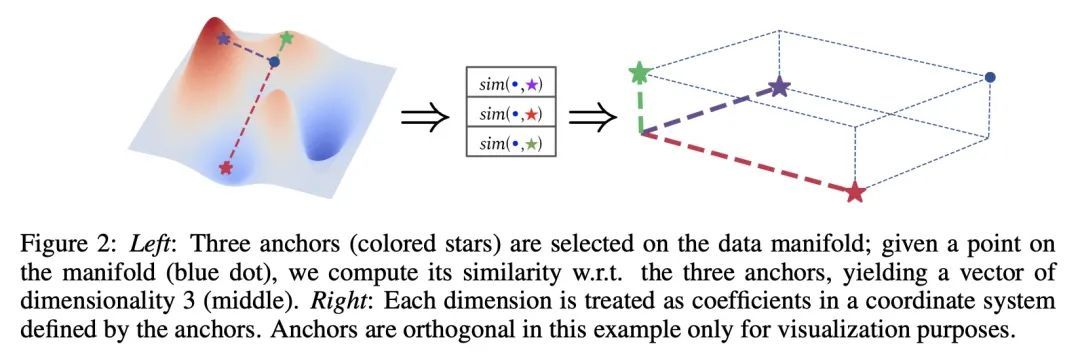
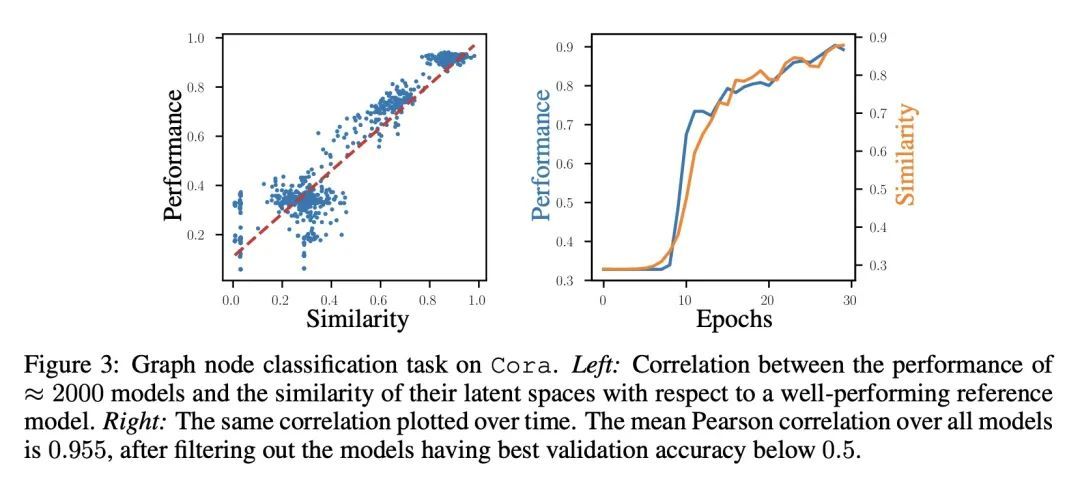
基于相对表示的零样本潜空间沟通。神经网络将位于高维空间的数据流形的几何结构嵌入到潜表示中。理想情况下,数据点在潜空间的分布应该只取决于任务、数据、损失和其他特定的架构约束。然而,诸如随机权重初始化、训练超参数或训练阶段的其他随机性来源等因素可能会引起不连贯的潜空间,从而阻碍任何形式的重用。尽管如此,本文从经验上观察到,在相同的数据和建模选择下,不同的潜空间通常以未知的准等距变换而不同:也就是说,在每个空间中,编码之间的距离不会改变。本文建议采用成对相似性作为替代的数据表示,可用来执行所需的不变性,而无需任何额外的训练。本文展示了神经架构如何利用这些相对表示来保证,在实践中,潜在的等值不变性,有效地实现了潜空间的沟通:从零样本模型缝合到不同环境之间的潜空间比较。在不同的数据集上广泛验证了所提出方法的泛化能力,这些数据集跨越了各种模态(图像、文本、图)、任务(如分类、重建)和架构(如CNN、GCN、Transformer)。
Neural networks embed the geometric structure of a data manifold lying in a high-dimensional space into latent representations. Ideally, the distribution of the data points in the latent space should depend only on the task, the data, the loss, and other architecture-specific constraints. However, factors such as the random weights initialization, training hyperparameters, or other sources of randomness in the training phase may induce incoherent latent spaces that hinder any form of reuse. Nevertheless, we empirically observe that, under the same data and modeling choices, distinct latent spaces typically differ by an unknown quasi-isometric transformation: that is, in each space, the distances between the encodings do not change. In this work, we propose to adopt pairwise similarities as an alternative data representation, that can be used to enforce the desired invariance without any additional training. We show how neural architectures can leverage these relative representations to guarantee, in practice, latent isometry invariance, effectively enabling latent space communication: from zero-shot model stitching to latent space comparison between diverse settings. We extensively validate the generalization capability of our approach on different datasets, spanning various modalities (images, text, graphs), tasks (e.g., classification, reconstruction) and architectures (e.g., CNNs, GCNs, transformers).
https://arxiv.org/abs/2209.15430

2、[LG] What Functions Can Graph Neural Networks Generate?
M Fereydounian, H Hassani, A Karbasi
[University of Pennsylvania & Yale University]
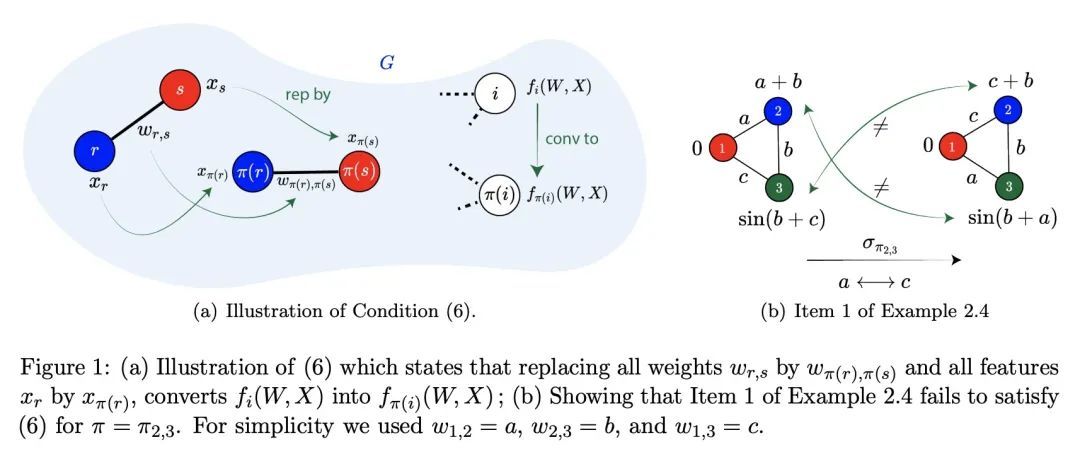
图神经网络可以生成哪些函数?本文通过对图函数的一个关键代数条件,即所谓的排列兼容性(permutation compatibility),完全回答了上述问题,该条件将图的权重和特征的排列与函数约束联系起来。证明了: (i) GNN作为一种图函数,必然是互换兼容的;(ii) 反过来,任何互换兼容的函数,当限制在具有不同节点特征的输入图上时,可以由GNN生成;(iii) 对于任意节点特征(不一定是不同的),一个简单的特征增强方案足以由GNN生成一个互换兼容的函数。(iv) 排列兼容可以通过只检查二次多函数约束来验证,而不是对所有的排列进行详尽的搜索;(v) 一旦用节点身份增强节点特征,GNN就可以生成任意图函数,从而超越图的同构性和排列兼容。上述特征为正式研究GNN与图上其他算法程序之间的复杂联系铺平了道路。例如,所提出的表示意味着许多自然图问题,如最小切割值、最大流量值、最大线段大小和最短路径都可以由GNN用简单的特征增强来生成。相反,著名的Weisfeiler-Lehman图同构性测试在具有相同特征的排列兼容函数不能由GNN生成时就会失败。本分析的核心是一个新的表示定理,它确定了GNN的基础函数,使得能将目标图函数的属性转化为GNN的聚合函数的属性。
In this paper, we fully answer the above question through a key algebraic condition on graph functions, called permutation compatibility, that relates permutations of weights and features of the graph to functional constraints. We prove that: (i) a GNN, as a graph function, is necessarily permutation compatible; (ii) conversely, any permutation compatible function, when restricted on input graphs with distinct node features, can be generated by a GNN; (iii) for arbitrary node features (not necessarily distinct), a simple feature augmentation scheme suffices to generate a permutation compatible function by a GNN; (iv) permutation compatibility can be verified by checking only quadratically many functional constraints, rather than an exhaustive search over all the permutations; (v) GNNs can generate any graph function once we augment the node features with node identities, thus going beyond graph isomorphism and permutation compatibility. The above characterizations pave the path to formally study the intricate connection between GNNs and other algorithmic procedures on graphs. For instance, our characterization implies that many natural graph problems, such as min-cut value, max-flow value, max-clique size, and shortest path can be generated by a GNN using a simple feature augmentation. In contrast, the celebrated Weisfeiler-Lehman graph-isomorphism test fails whenever a permutation compatible function with identical features cannot be generated by a GNN. At the heart of our analysis lies a novel representation theorem that identifies basis functions for GNNs. This enables us to translate the properties of the target graph function into properties of the GNN's aggregation function.
https://arxiv.org/abs/2202.08833

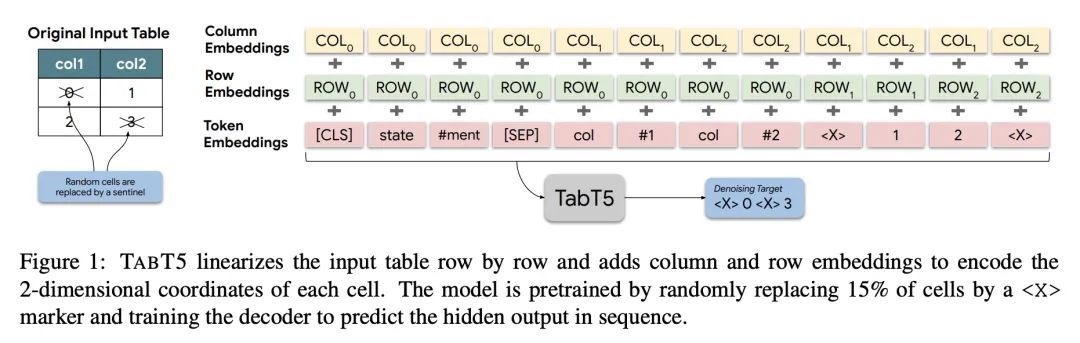
3、[CL] Table-To-Text generation and pre-training with TabT5
E Andrejczuk, J M Eisenschlos, F Piccinno, S Krichene, Y Altun
[Google Research]
基于TabT5的表格到文本生成和预训练。仅有编码器的Transformer模型已经成功地应用于不同的表格理解任务,如TAPAS。这些架构的一个主要限制是,其被限制在类似于分类的任务上,如单元格选择或连带关系检测。本文提出TABT5,一种编-解码器模型,基于表格和文本输入生成自然语言文本。TABT5克服了仅有编码器的限制,加入了解码器组件,并利用输入结构与表格特定的嵌入和预训练。TABT5在几个领域取得了新的最先进结果,包括电子表格公式预测,序列准确率提高了15%,QA序列准确率提高了2.5%,数据到文本生成BLEU提高了2.5%。
Encoder-only transformer models have been successfully applied to different table understanding tasks, as in TAPAS (Herzig et al., 2020). A major limitation of these architectures is that they are constrained to classification-like tasks such as cell selection or entailment detection. We present TABT5, an encoder-decoder model that generates natural language text based on tables and textual inputs. TABT5 overcomes the encoder-only limitation by incorporating a decoder component and leverages the input structure with table specific embeddings and pre-training. TABT5 achieves new state-of-the-art results on several domains, including spreadsheet formula prediction with a 15% increase in sequence accuracy, QA with a 2.5% increase in sequence accuracy and data-to-text generation with a 2.5% increase in BLEU.
https://arxiv.org/abs/2210.09162

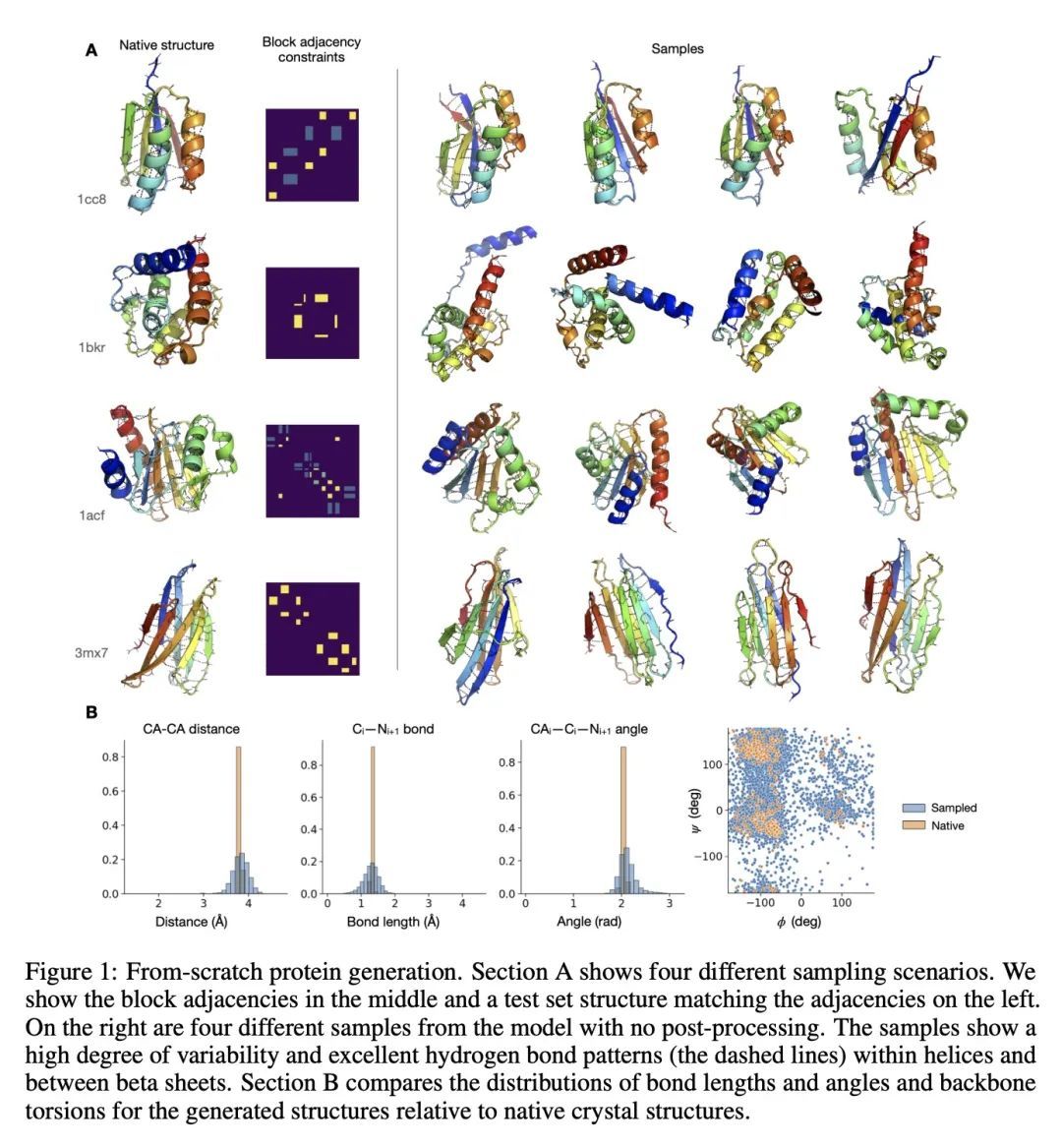
4、[LG] Protein Structure and Sequence Generation with Equivariant Denoising Diffusion Probabilistic Models
N Anand, T Achim
[Stanford University]
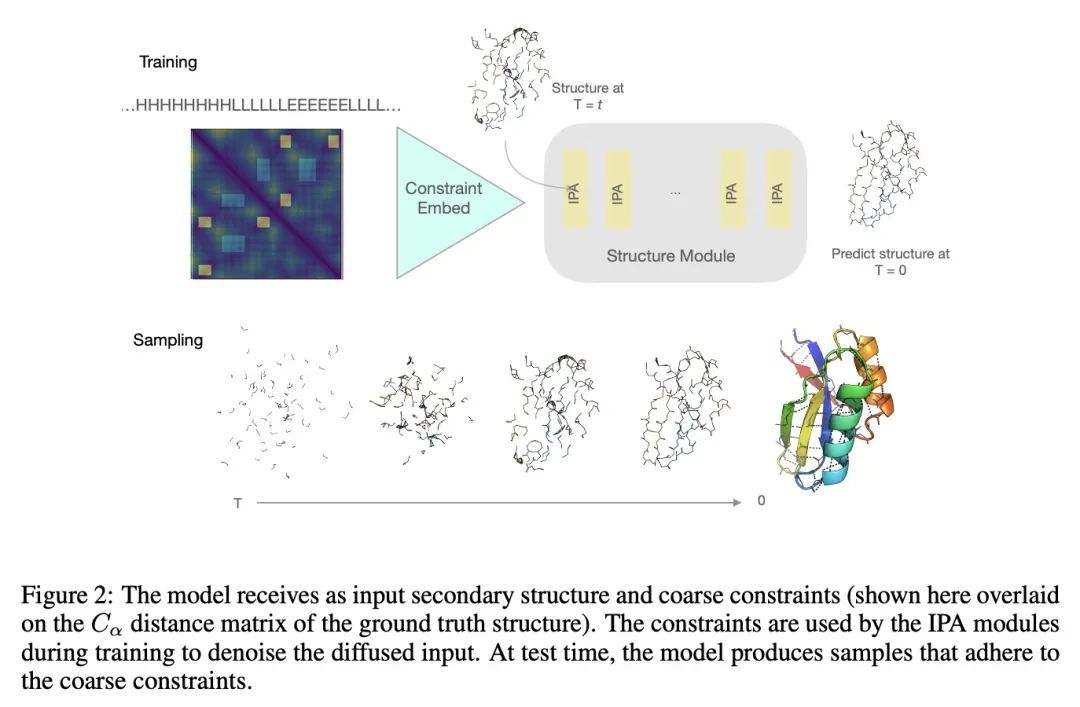
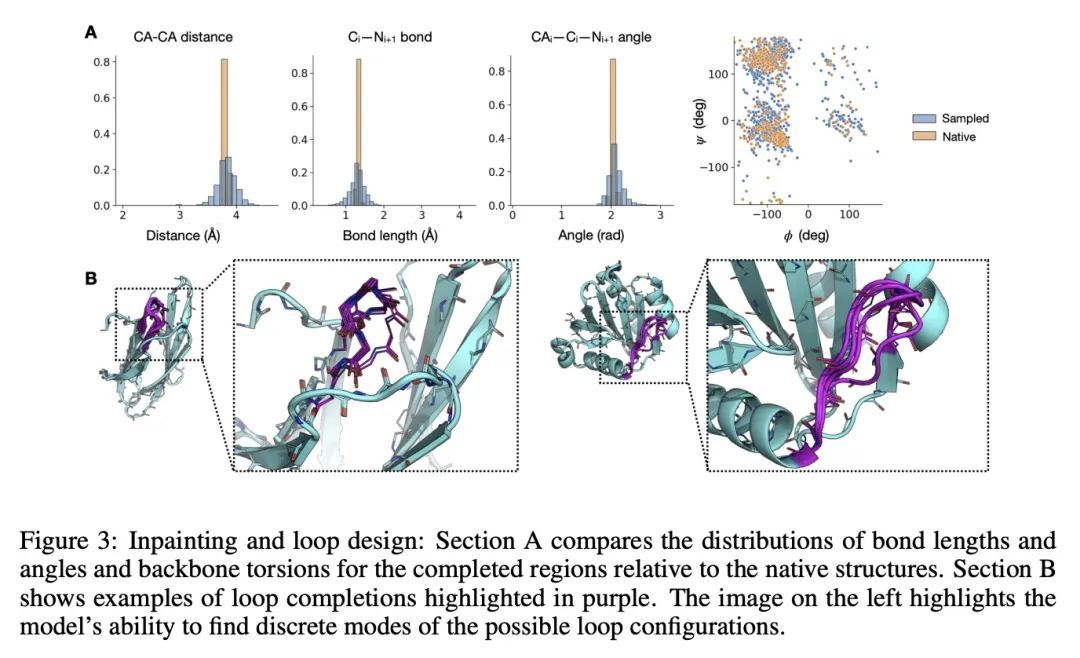
基于等变去噪扩散概率模型的蛋白质结构和序列生成。蛋白质是一种大分子,在生命基础的细胞过程中起着重要的作用。生物工程的一项重要任务是设计具有特定3D结构和化学特性的蛋白质,以实现目标功能。为此,本文提出一种蛋白质结构和序列生成模型,可以在比之前的分子生成模型方法大得多的尺度上运行。该模型完全从实验数据中学习,并以蛋白质拓扑结构的紧凑规范为条件,生成全原子骨架配置以及序列和侧链预测。通过对其样本的定性和定量分析来证明该模型的质量。
Proteins are macromolecules that mediate a significant fraction of the cellular processes that underlie life. An important task in bioengineering is designing proteins with specific 3D structures and chemical properties which enable targeted functions. To this end, we introduce a generative model of both protein structure and sequence that can operate at significantly larger scales than previous molecular generative modeling approaches. The model is learned entirely from experimental data and conditions its generation on a compact specification of protein topology to produce a full-atom backbone configuration as well as sequence and side-chain predictions. We demonstrate the quality of the model via qualitative and quantitative analysis of its samples. Videos of sampling trajectories are available at this https URL .
https://arxiv.org/abs/2205.15019

5、[CL] Can language models learn from explanations in context?
A K. Lampinen, I Dasgupta, S C. Y. Chan, K Matthewson, M H Tessler, A Creswell, J L. McClelland, J X. Wang, F Hill
[DeepMind]
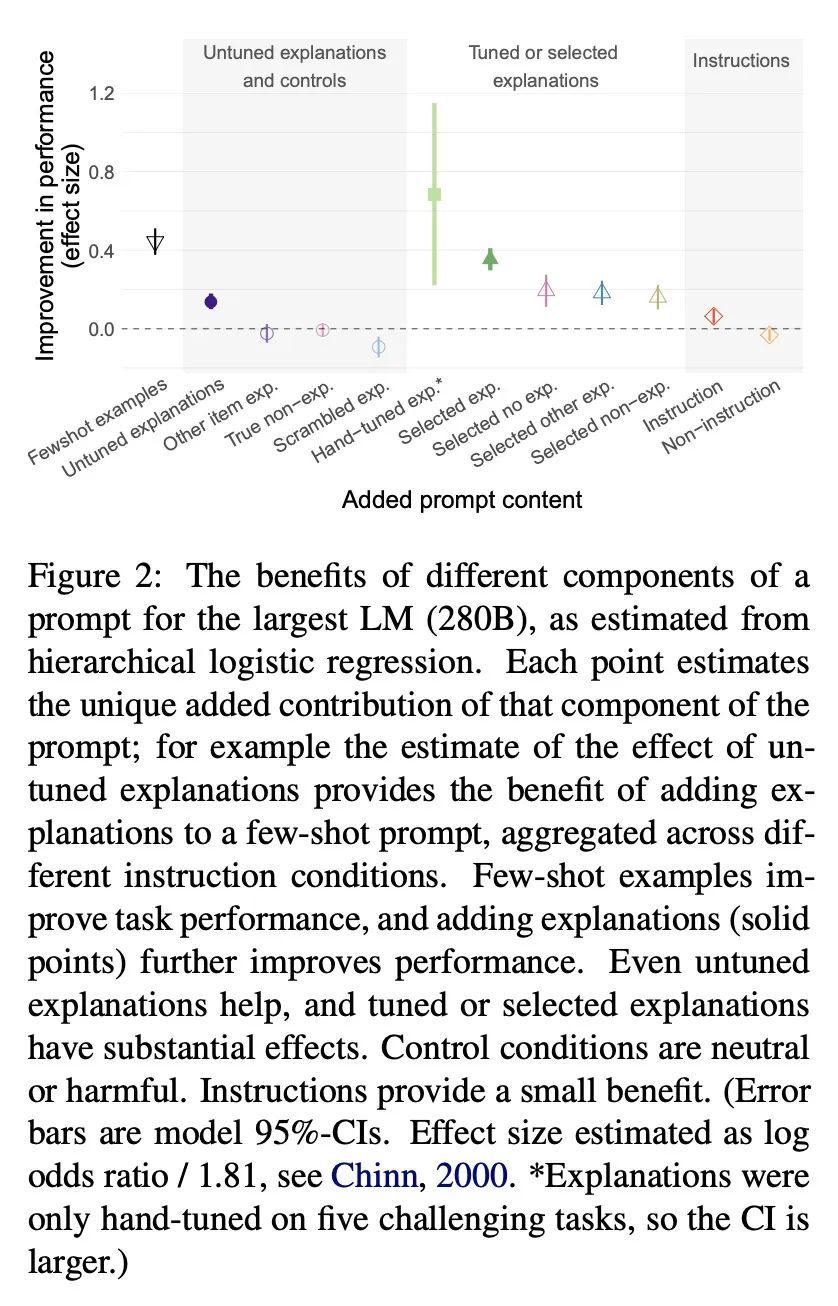
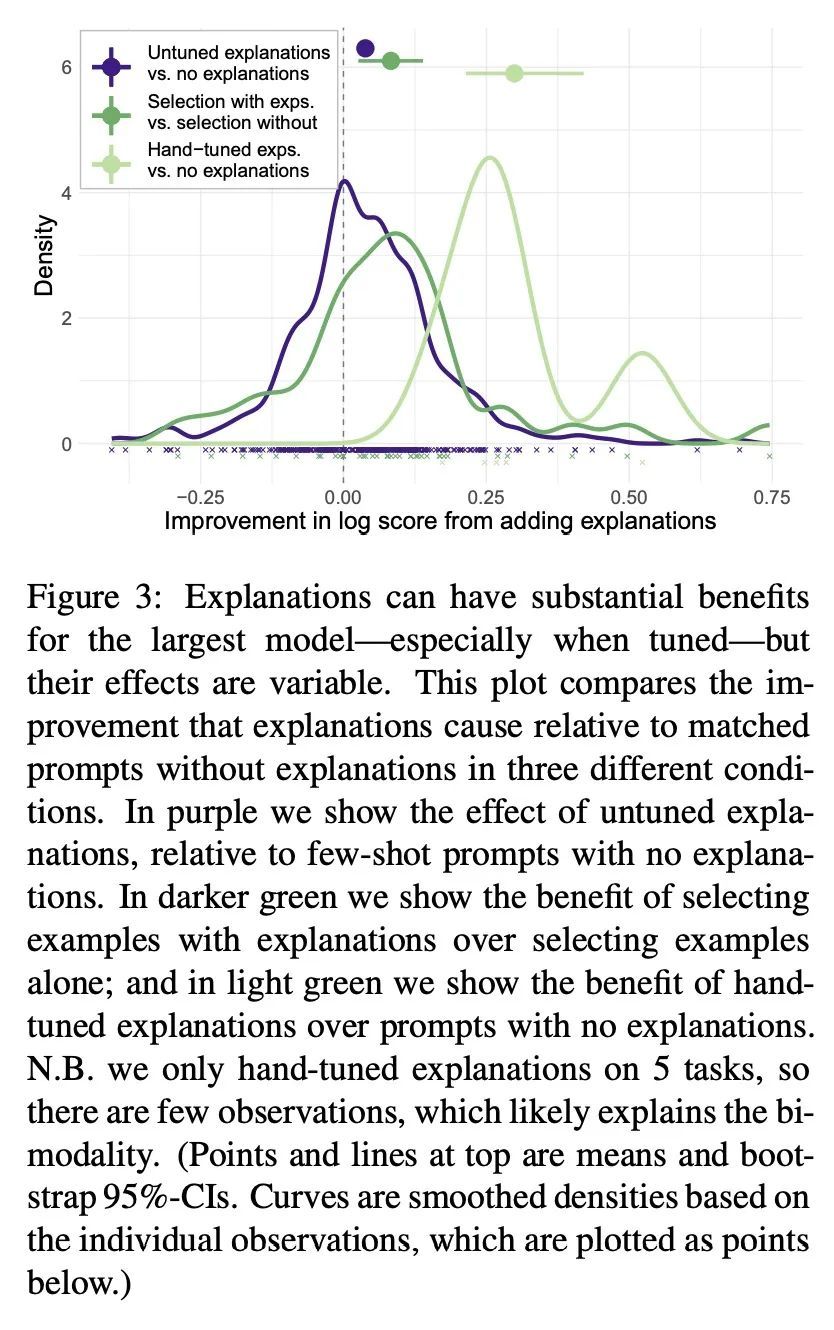
语言模型能从上下文解释中学习吗?语言模型(LM)可以通过自适应少量上下文中的例子来完成新的任务。对人类来说,将例子与任务原理联系起来的解释可以提高学习效果。因此,本文研究对少样本例子的解释是否能帮助语言模型。将40个具有挑战性的任务中的问题加上答案解释,以及各种匹配控制解释进行标注。评估不同类型的解释、说明和控制是如何影响零样本和少样本的表现。用统计学上的多层次模型技术来分析这些结果,考虑了条件、任务、提示和模型之间的嵌套依赖关系。结果发现,即使不进行微调,解释也能提高成绩。此外,针对小型验证集的性能进行手工调整的解释提供了更大的好处,并且通过选择例子和解释来建立提示,比单独选择例子大大改善了性能。最后,即使是未经微调的解释也比精心匹配的对照组要好,这表明好处是由于一个例子和它的解释之间的联系,而不是较低层次的特征。然而,只有大型模型才会受益。综上所述,解释可以支持大型语言模型在挑战性任务中的上下文学习。
Language Models (LMs) can perform new tasks by adapting to a few in-context examples. For humans, explanations that connect examples to task principles can improve learning. We therefore investigate whether explanations of few-shot examples can help LMs. We annotate questions from 40 challenging tasks with answer explanations, and various matched control explanations. We evaluate how different types of explanations, instructions, and controls affect zero- and few-shot performance. We analyze these results using statistical multilevel modeling techniques that account for the nested dependencies among conditions, tasks, prompts, and models. We find that explanations can improve performance -- even without tuning. Furthermore, explanations hand-tuned for performance on a small validation set offer substantially larger benefits, and building a prompt by selecting examples and explanations together substantially improves performance over selecting examples alone. Finally, even untuned explanations outperform carefully matched controls, suggesting that the benefits are due to the link between an example and its explanation, rather than lower-level features. However, only large models benefit. In summary, explanations can support the in-context learning of large LMs on challenging tasks.
https://arxiv.org/abs/2204.02329


另外几篇值得关注的论文:
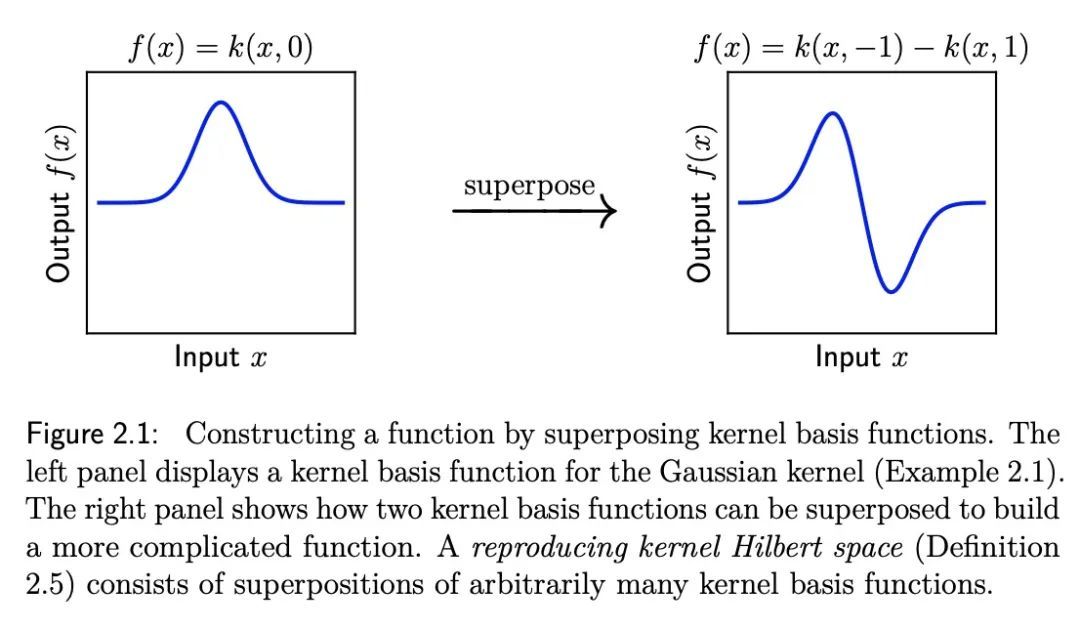
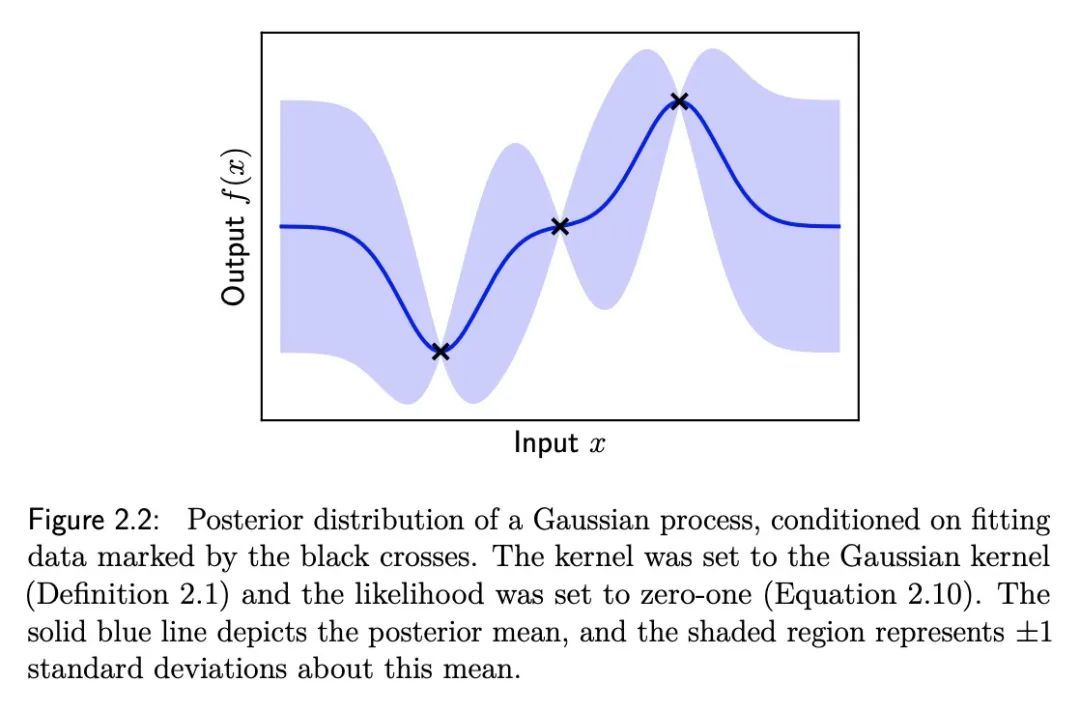
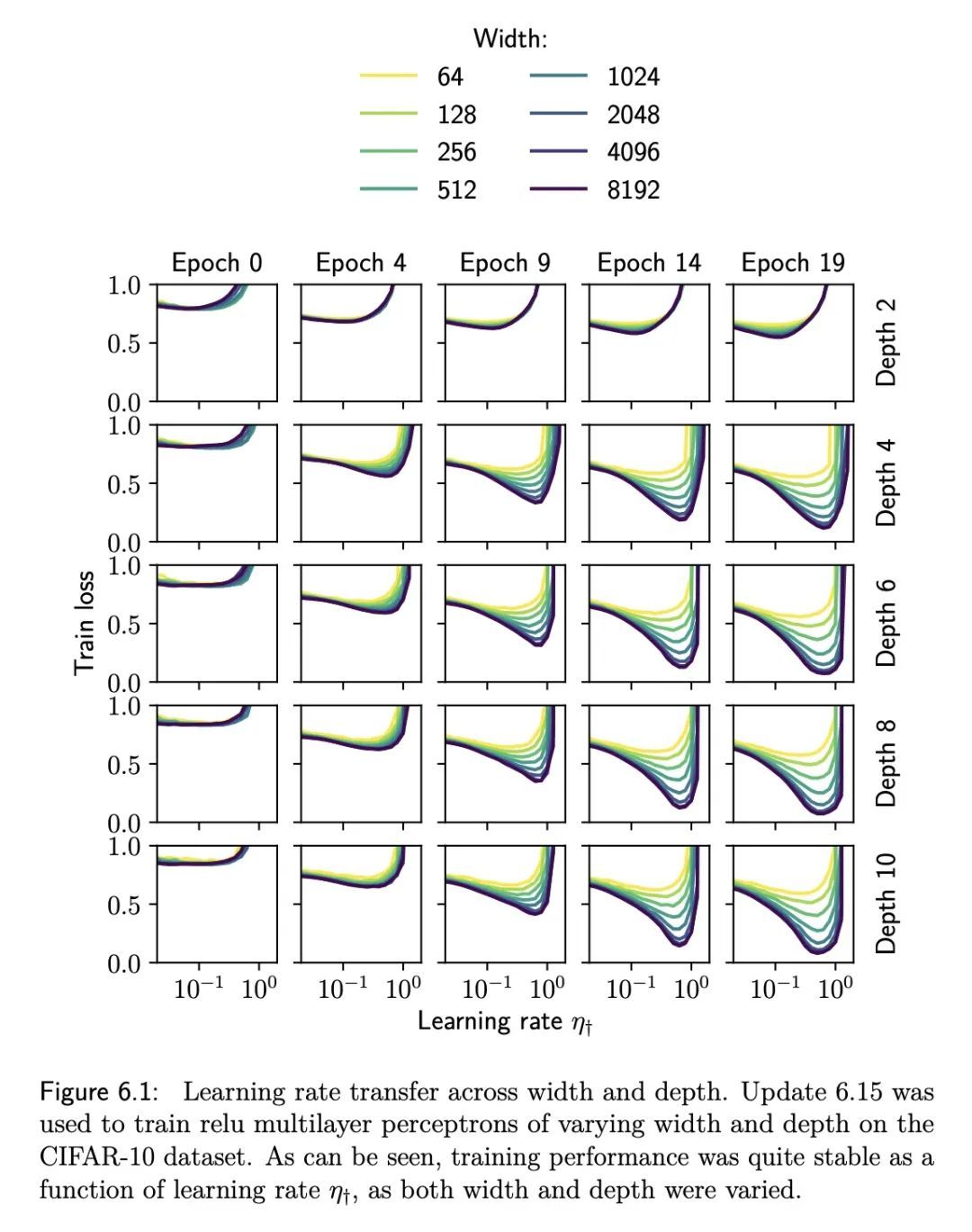
[LG] Optimisation & Generalisation in Networks of Neurons
神经元网络的优化和泛化
J Bernstein
[California Institute of Technology]
https://arxiv.org/abs/2210.10101

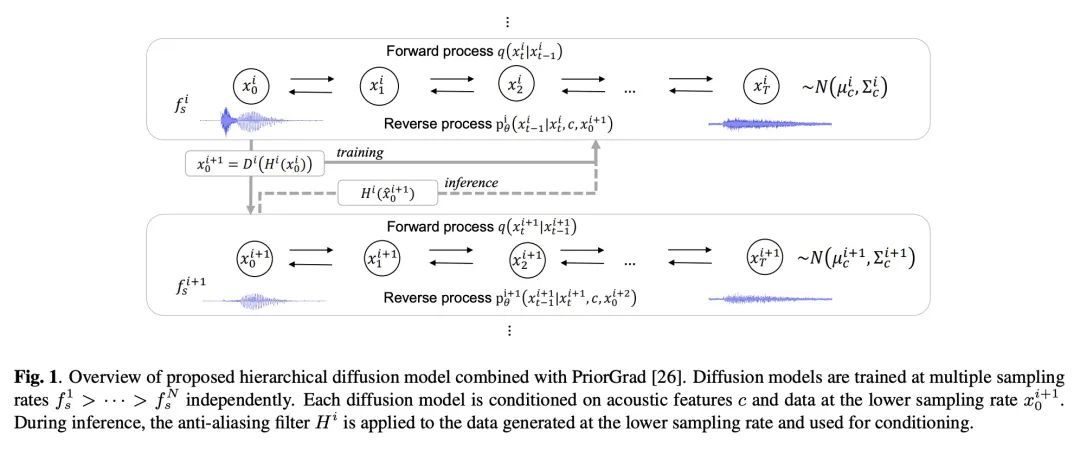
[AS] Hierarchical Diffusion Models for Singing Voice Neural Vocoder
面向歌唱语音神经声码器的分层扩散模型
N Takahashi, M Kumar, Singh, Y Mitsufuji
[Sony Group Corporation]
https://arxiv.org/abs/2210.07508


[LG] Structure-based drug design with geometric deep learning
基于几何深度学习的基于结构药物设计
C Isert, K Atz, G Schneider
[ETH Zurich]
https://arxiv.org/abs/2210.11250

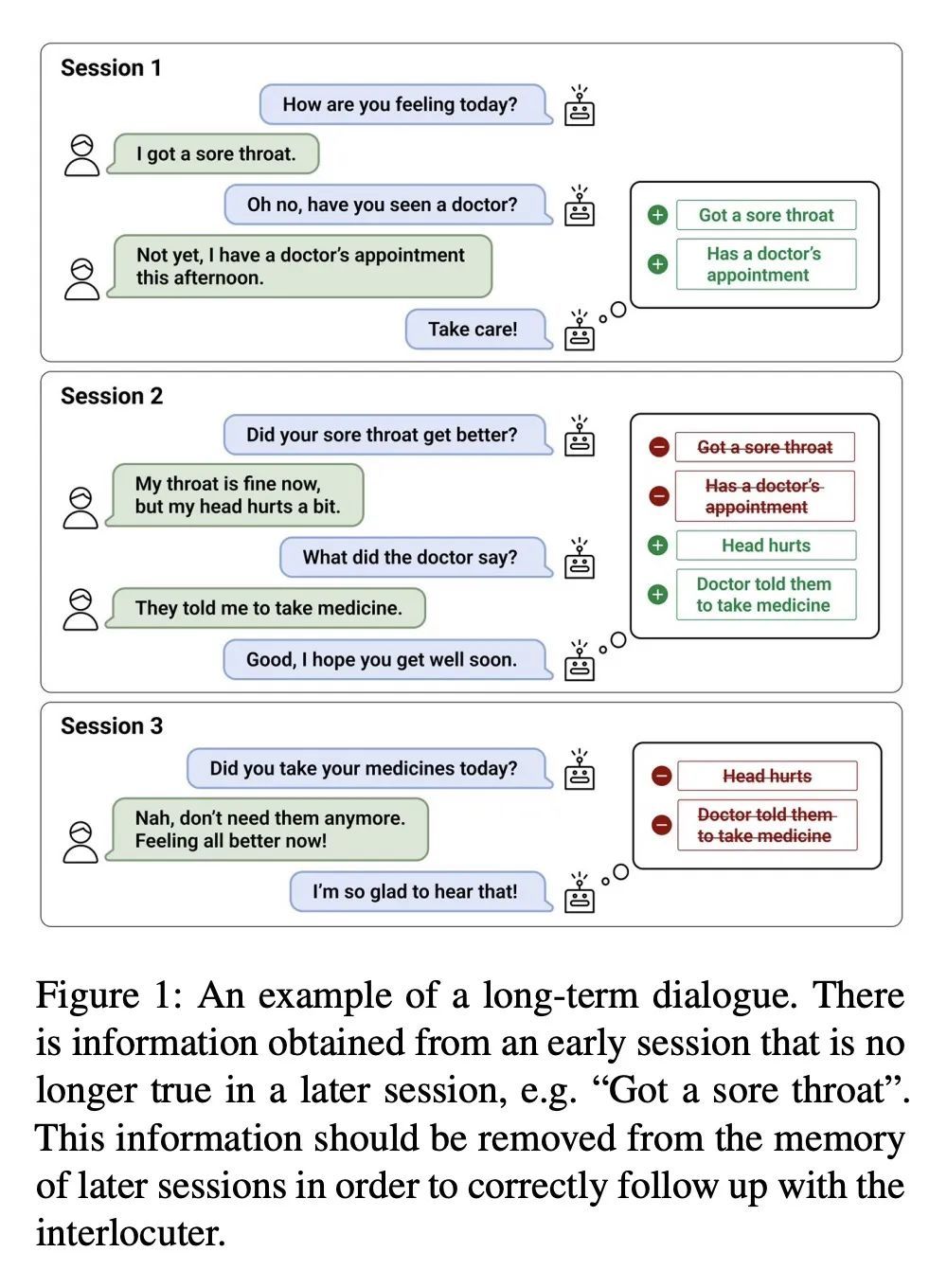
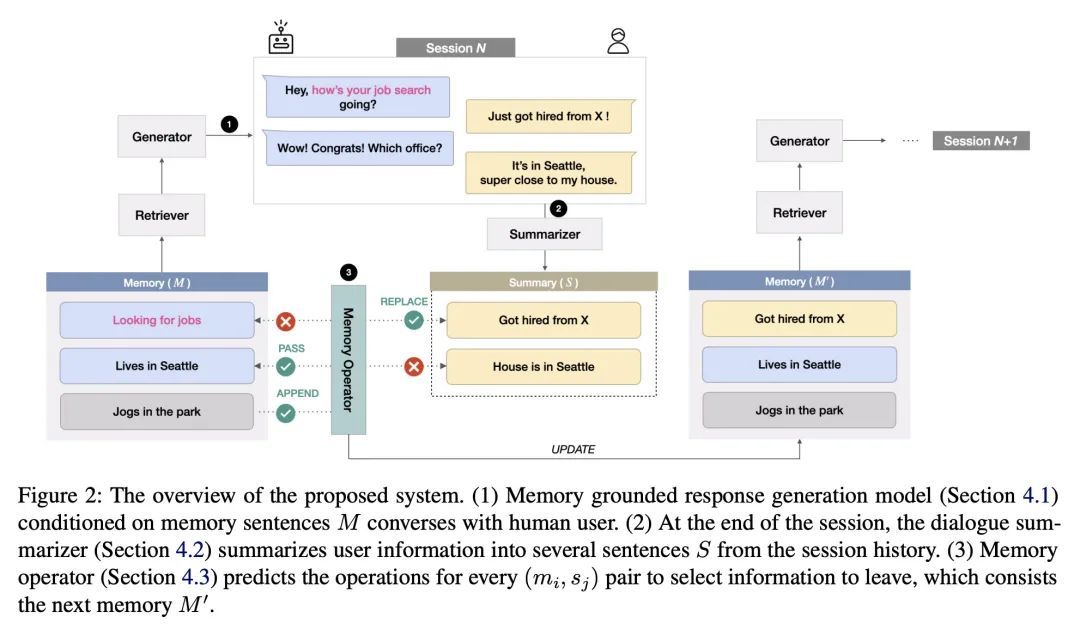
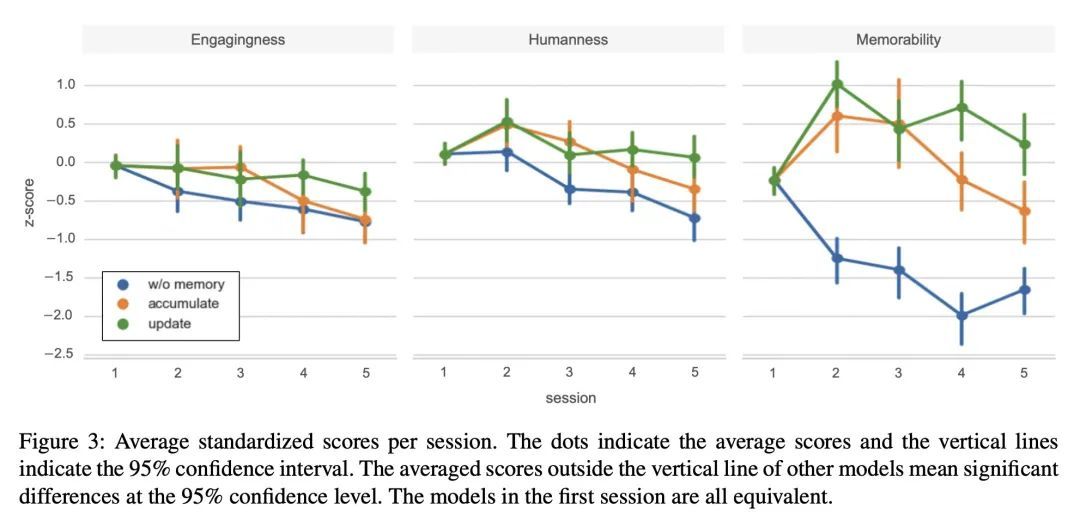
[CL] Keep Me Updated! Memory Management in Long-term Conversations
保持更新!长期对话的记忆管理
S Bae, D Kwak, S Kang, M Y Lee, S Kim, Y Jeong, H Kim, S Lee, W Park, N Sung
[NAVER CLOVA]
https://arxiv.org/abs/2210.08750

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢