
【标题】Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data
【作者团队】Allen Nie, Yannis Flet-Berliac, Deon R. Jordan
【发表日期】2022.10.16
【论文链接】https://arxiv.org/pdf/2210.08642.pdf
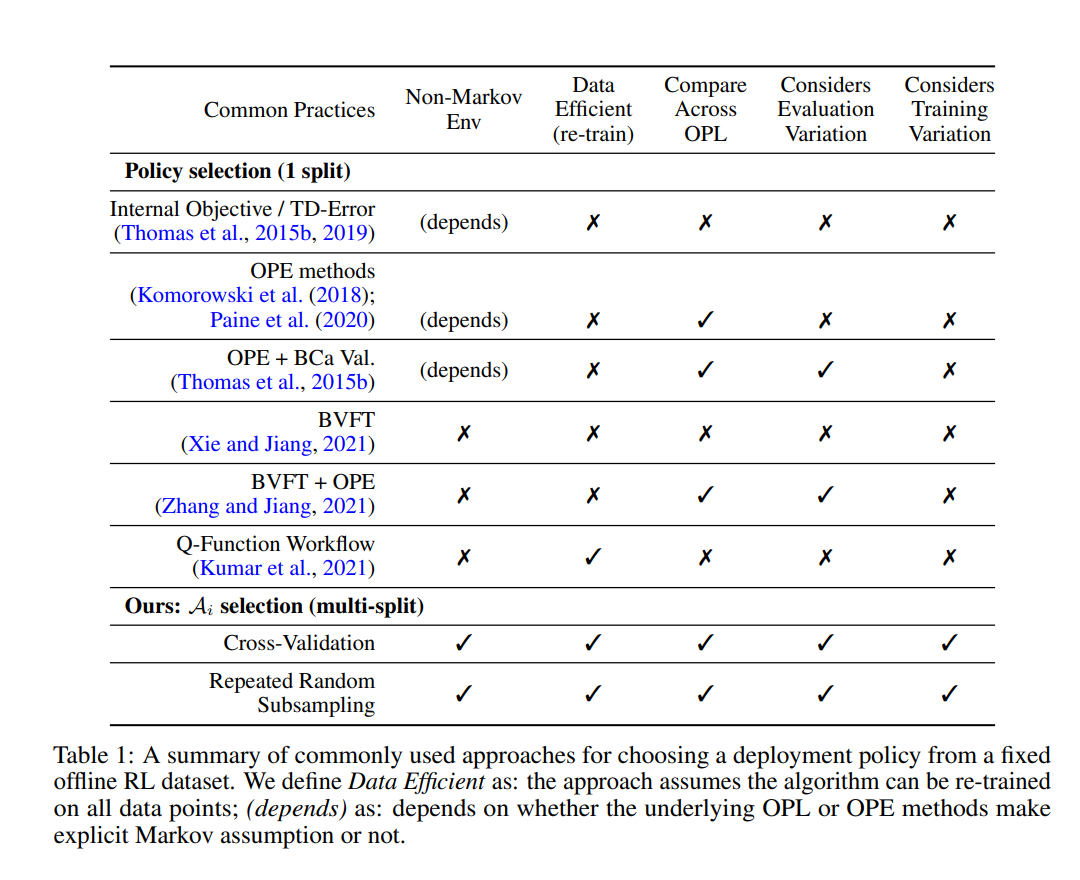
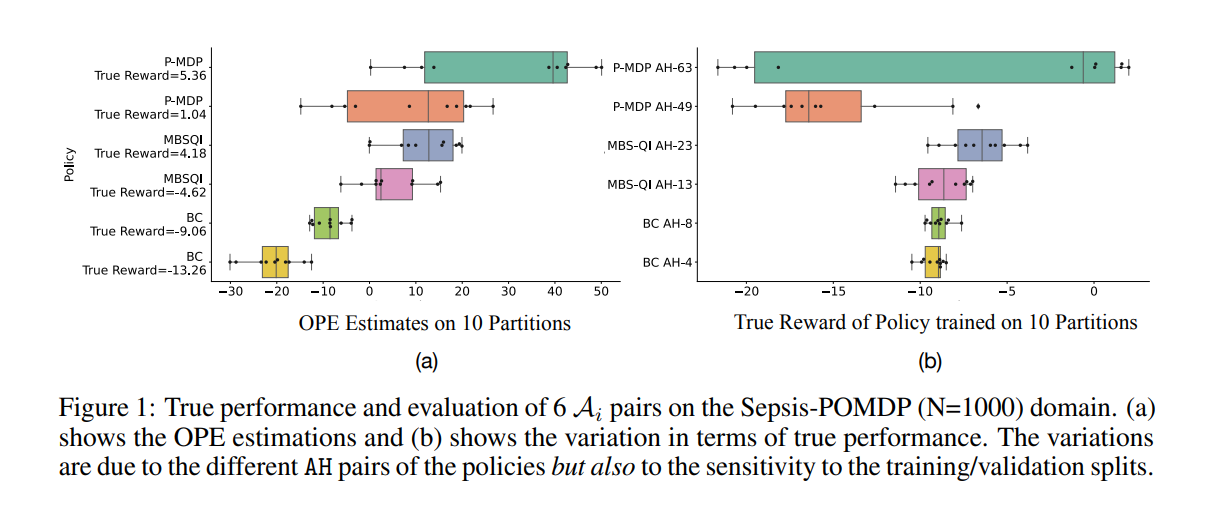
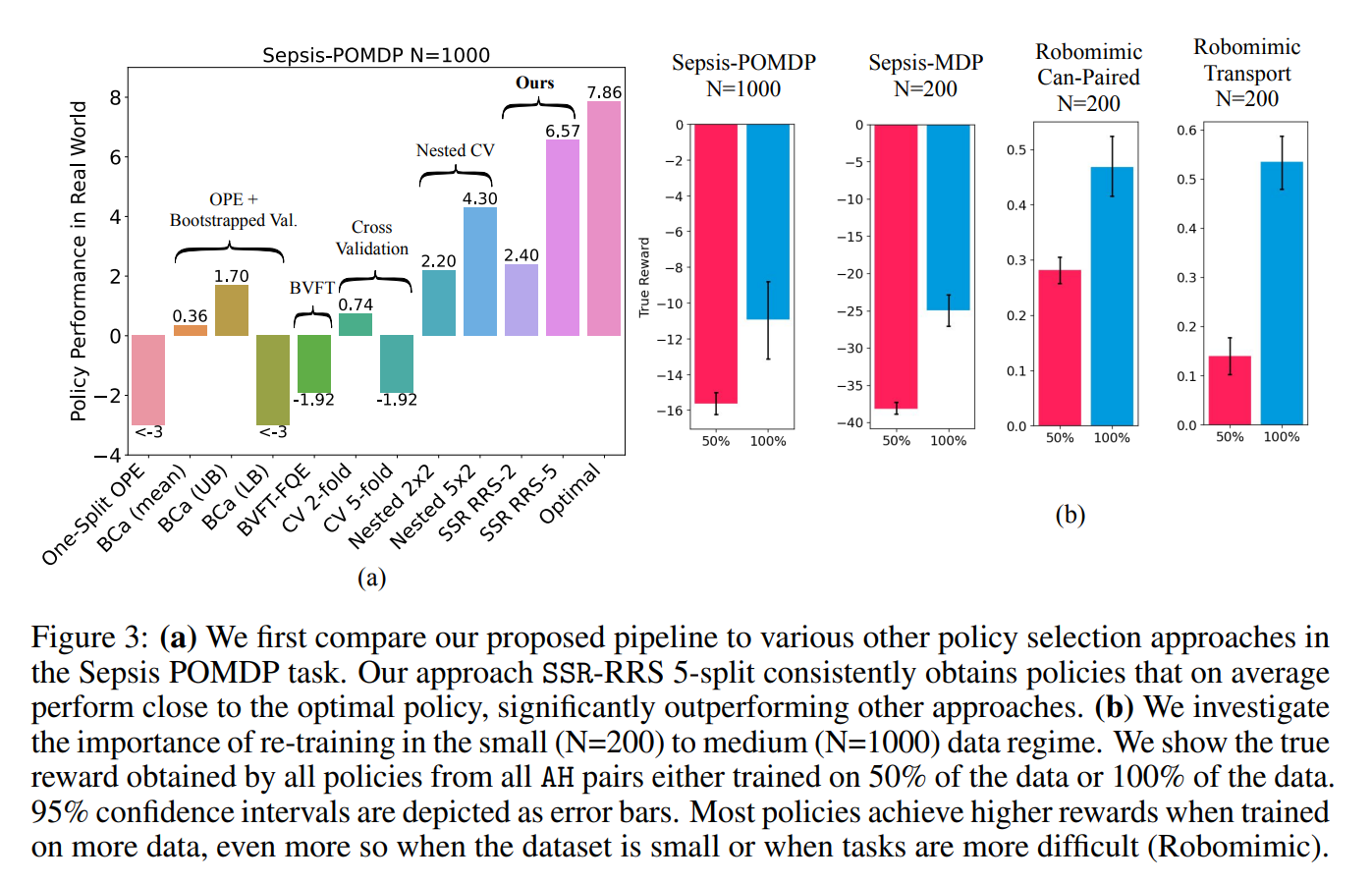
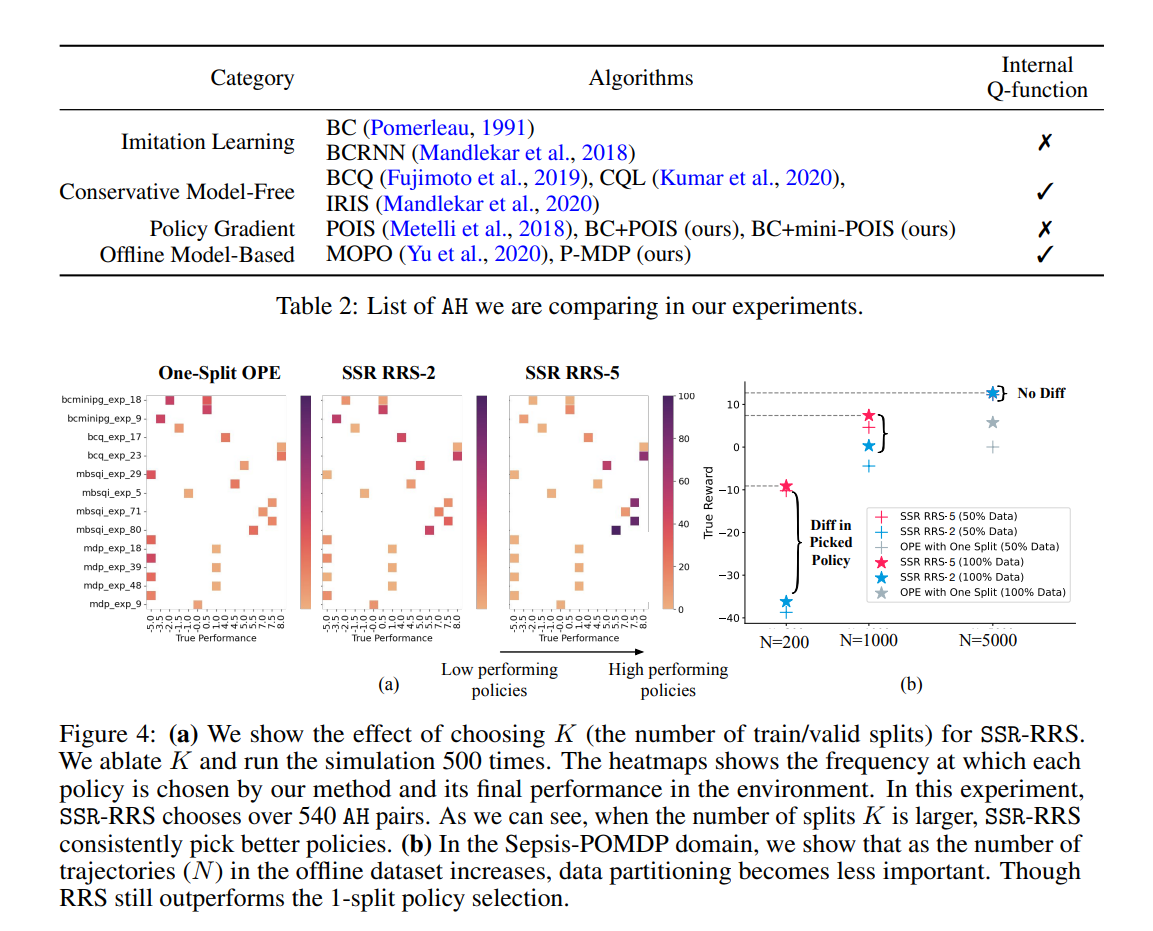
【推荐理由】离线强化学习 (RL) 可用于通过利用历史数据来提高未来的性能。离线 RL 存在许多不同的算法,这些算法及其超参数设置可以导致具有显着不同性能的决策策略。这提示需要管道,允许研究人员系统地为其设置超参数。在大多数现实世界的环境中,这个管道必须只涉及历史数据的使用。 受监督学习的统计模型选择方法的启发,本文引入了与任务和方法无关的管道,用于在提供的数据集大小有限时自动训练、比较、选择和部署最佳策略。 特别是,本文的方法强调了执行多个数据拆分以产生更可靠的算法超参数选择的重要性。实验表明,当数据集较小时,它会产生重大影响。 与替代方法相比,本文提出的管道从广泛的离线策略学习算法以及医疗保健、教育和机器人技术的各种模拟领域输出性能更高的部署策略。 这项工作有助于开发用于离线 RL 的自动算法超参数选择的通用元算法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢