
【标题】When to Update Your Model: Constrained Model-based Reinforcement Learning
【作者团队】Tianying Ji, Yu Luo, Fuchun Sun, Mingxuan Jing
【发表日期】2022.10.15
【论文链接】https://arxiv.org/pdf/2210.08349.pdf
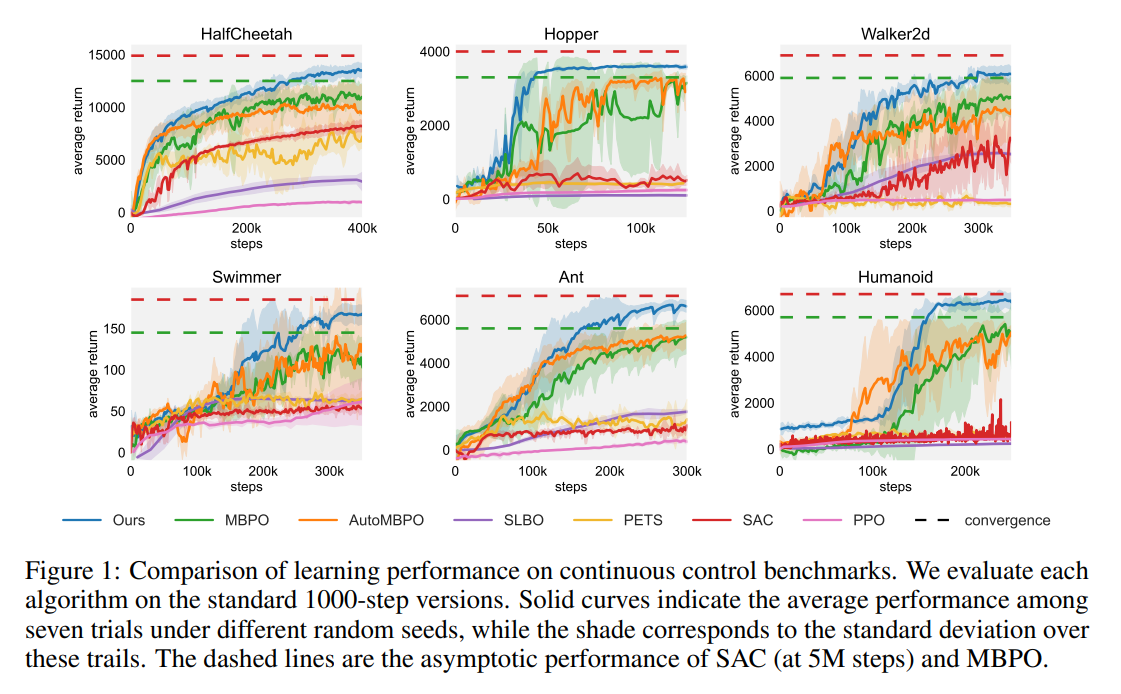
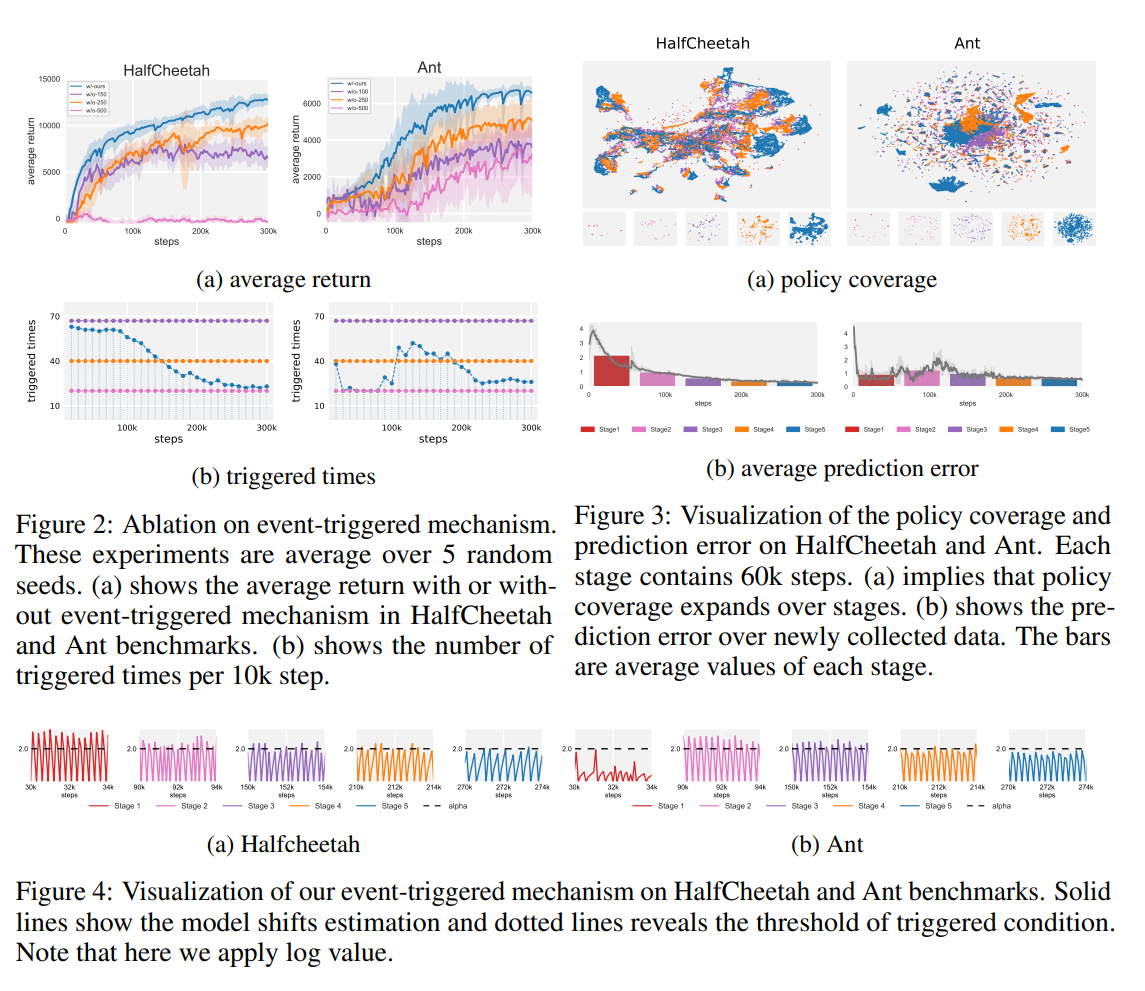
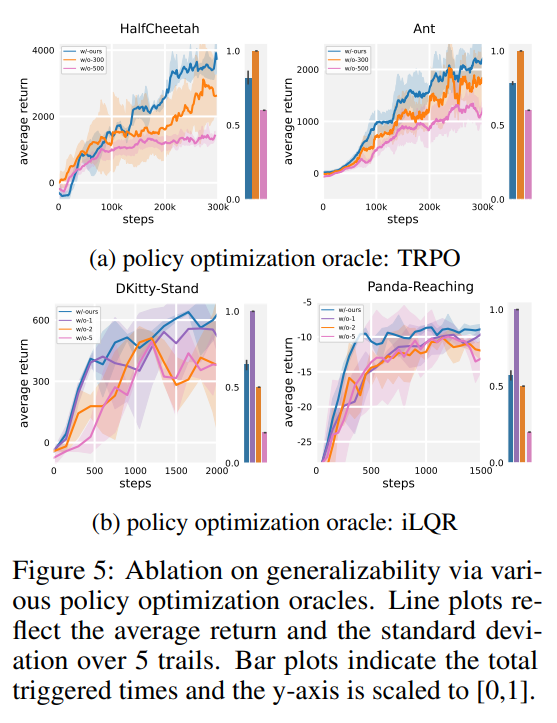
【推荐理由】设计和分析具有保证单调改进的基于模型的 RL (MBRL) 算法一直具有挑战性,这主要是由于策略优化和模型学习之间的相互依赖关系。 现有的差异界限通常忽略模型变化的影响,并且其相应的算法容易因模型的剧烈更新而降低性能。本文首先提出了一种新颖且通用的理论方案,用于保证 MBRL 的非递减性能。后续派生的界限揭示了模型转变和性能改进之间的关系。作者制定一个受约束的下界优化问题,以允许 MBRL 的单调性。 另一个例子表明,从动态变化的探索次数中学习模型有利于最终的回报。 受这些分析的启发,本文设计了一个简单但有效的算法 CMLO(约束模型转移下界优化),通过引入一个事件触发机制来灵活地确定何时更新模型。 实验表明,CMLO 超越了其他最先进的方法,并在采用各种策略优化方法时产生了提升。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢