
今天新出了一篇很有意思的文章,来自香港大学、牛津大学、字节跳动的研究人员对合成数据是否对图像分类有帮助进行了细致研究,相信结论会给我们一些启发。
作者信息:

论文地址:
https://arxiv.org/pdf/2210.07574.pdf
代码地址:
https://github.com/CVMI-Lab/SyntheticData
(尚未开源)
相信对于数据增强的概念,大家都并不陌生,对图像进行几何变换(旋转、裁剪、翻转),对比度拉伸,甚至图像的混合,已被证明对图像分类有帮助。
但作者此处研究的是对近年来大火的图像生成模型得到的合成数据,这个领域发展很快,出现了很多生成质量很高的基于文本生成图像的优秀方法,比如扩散模型等,除了生成数据量可以无限,这种生成模型也可以在语义层次方便的增加合成数据的多样性。
作者通过三个角度来研究基于“文本-图像”这种生成方法得到的合成数据是否对图像分类有帮助,包含对零样本图像分类、少样本图像分类、迁移学习。
零样本(zero-shot)图像分类,训练集不含要分类的类别,但有新类别的描述,以下表格是作者在17个数据集上的测试结果(具体实验方法可以查看原文):
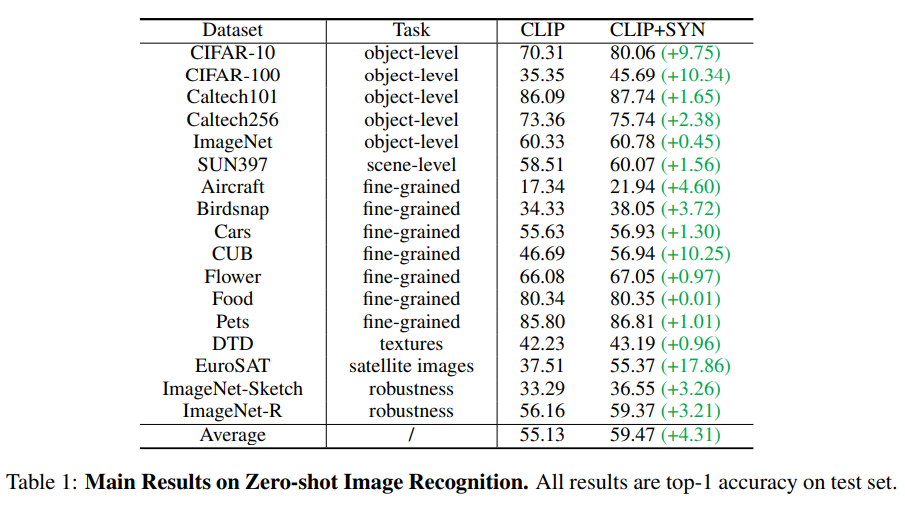
可以发现性能获得了大幅提升,top-1精度平均提升了4.31% !
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢