
近日,在斯坦福大学、华盛顿大学、Allen AI 和 UMass 联合发起的机器阅读理解(QuAC1)比赛上,京东 AI 研究院语音语言实验室提出的 EL-QA 模型(Single Model)登顶 QuAC Leaderboard,全部三项指标均获得第一名。
其中,在 F1-Measure(又称为 F1-Score) 指标上达到 74.6,大幅拉近了机器与人类在该任务上的水平差距。这也意味着以零售、物流、金融、客服等优质场景为依托的京东 AI 研究院,在机器阅读理解能力上取得了突飞猛进的成果。
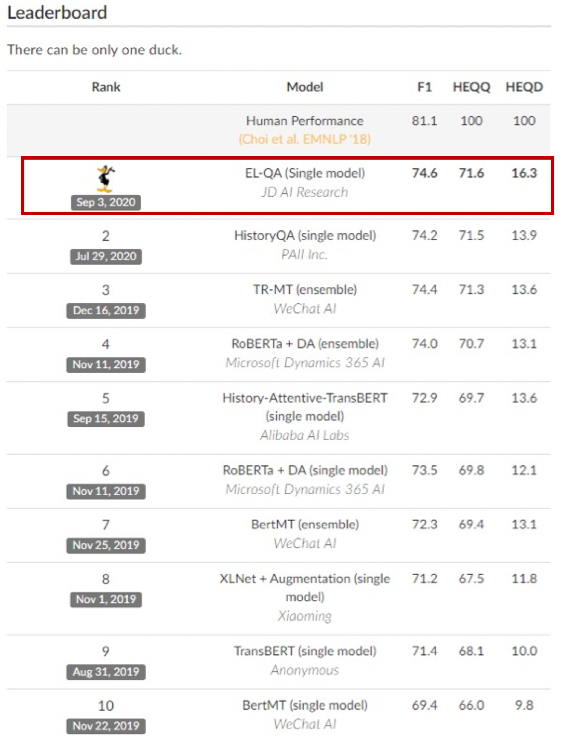
目前,QuAC 是人机多轮对话交互领域复杂度最高的数据集,要求模型具备强大的上下文语义理解、指代推理、省略语义恢复和知识推理等能力,这也吸引了全球顶级科研院所和企业研究机构参加。从结果来看,QuAC 具有较高的难度,在这个数据集上目前的最佳 AI 模型的性能距离人类表现仍有一定差距,表明在这个问题上技术还有进步的空间。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢