
专利文件通常使用法律和高度技术性的语言,并且使用上下文相关的术语,这些术语的含义可能与口语用法有很大不同,甚至在不同的文件之间也十分不同。使用传统的专利搜索方法 (opens new window)(例如关键字搜索)搜索超过一亿个专利文档语料库的过程可能很繁琐,并且由于使用的语言广泛且不标准,会导致许多结果丢失。例如,“足球”可以描述为“球形娱乐装置”、“充气运动球”或“球类游戏用球”。此外,一些专利文档中使用的语言可能会使术语变得混淆,因此更强大的自然语言处理 (opens new window)(NLP)和语义相似性 (opens new window)理解可以让每个人都有机会进行彻底搜索。
由于使用了法律和技术术语,专利领域(以及更通用的技术文献,如科学出版物)对NLP建模提出了独特的挑战。虽然有多种常用的通用语义文本相似性 (opens new window)(STS)基准数据集(例如STS-B (opens new window)、SICK (opens new window)、MRPC (opens new window)、PIT (opens new window)),但据我们所知,目前还没有专注于专利和科学出版物中技术概念的数据集(与有些相关的BioASQ挑战 (opens new window)包含一个生物医学问答任务)。此外,随着专利库规模的持续增长 (opens new window)(全球每年发布数百万新专利),有必要为该领域开发更有用的NLP模型。
今天,我们宣布发布了专利短语相似度 (opens new window)数据集,这是一个新的人类评级上下文短语到短语的语义匹配数据集,以及相关的论文 (opens new window)在SIGIR PatentSemTech研讨会 (opens new window)上提交,该研讨会侧重于专利的技术术语。专利短语相似性数据集包含约50000个分级短语对,每个短语对都有一个联合专利分类 (opens new window)(CPC)的类作为上下文。除了通常包含在其他基准数据集中的相似性分数外,我们还包括类似于WordNet (opens new window)的粒度分级类,例如同义词、反义词、上义词 (opens new window)、下义词 (opens new window)、全名 (opens new window)、缩写词 (opens new window)和领域相关。该数据集(根据知识共享署名4.0国际许可证 (opens new window)发布)被Kaggle (opens new window)和USPTO (opens new window)用作美国专利短语匹配竞赛 (opens new window)的基准数据集,以更多关注于机器学习模型在技术文本上的性能。初步结果表明,在此新数据集上进行微调的模型性能大大优于未进行微调的常规预训练模型。
02 专利短语相似性数据集
为了更好地训练下一代最先进的模型,我们创建了专利短语相似性数据集,其中包括许多示例来解决以下问题:(1)短语消除歧义,(2)对抗性关键字匹配,以及(3)硬否定关键字(即不相关但从其他模型获得较高相似性分数的关键字)。一些关键字和短语可以有多种含义(例如,短语“mouse”可能指动物或计算机输入设备),因此我们通过在每对短语中包含CPC类来消除短语的歧义。此外,许多NLP模型(例如,单词袋模型 (opens new window))对包含匹配关键字但在其他方面不相关的短语的数据处理效果不佳(对手关键字,例如“容器部分”→ “厨房容器”、“偏移表”→ “表扇”)。专利短语相似性数据集旨在包含许多通过对抗性关键字匹配而不相关的匹配关键字的示例,从而使NLP模型能够提高其性能。
专利短语相似性数据集中的每个条目包含两个短语,锚和目标,上下文CPC类,评级类和相似性分数。数据集包含48548个条目和973个唯一锚定,分为训练集(75%)、验证集(5%)和测试集(20%)。拆分数据时,具有相同锚定的所有条目都将保留在同一集合中。共有106个不同上下文的CPC类,并且该训练集包含所有的上下文CPC类。
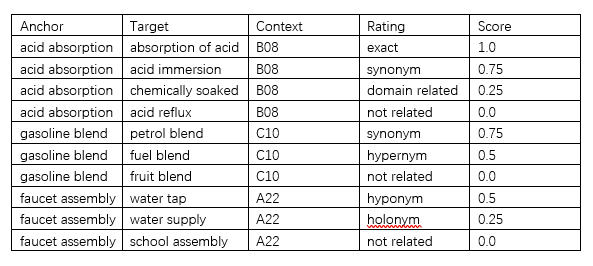
数据集的小样本,包含锚定短语和目标短语、上下文CPC类(B08:清洁,C10:石油、天然气、燃料、润滑油,A22:屠宰,加工肉类/家禽/鱼类)、评级类和相似性分数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢