
深度学习的黑盒虽然免去了构造特征的麻烦,但也埋下了一个隐患。
其中一个典型的安全问题是后门学习,它可以通过恶意操纵训练数据或控制训练过程,在模型中插入难以察觉的后门。

目前后门学习的相关研究呈火热之势,但还没有完善的基准用来评估相关工作。
最近香港中文大学(深圳)吴保元教授课题组与西安交通大学沈超教授课题组联合发布了一个后门攻击与防御基准BackdoorBench。

论文链接:https://arxiv.org/abs/2206.12654
代码链接:https://github.com/SCLBD/backdoorbench
项目链接:https://backdoorbench.github.io
截至2022年10月22日,BackdoorBench已集成了9种攻击方法、12种防御方法、5种分析工具,leaderboard公布了8000组攻防结果。
该工作目前已被NeurIPS 2022 Datasets and Benchmarks Track接收。
简介
随着深度神经网络(DNNs)在许多场景中的广泛运用,DNN的安全问题已经引起了越来越多的关注。
如果用户从第三方平台下载未经验证的数据集/checkpoint来训练/微调自定义的模型,甚至将模型训练过程直接外包给第三方平台,后门攻击会对这类用户产生极大的威胁 。当后门模型输入正常样本时,会预测出正确的结果;但是一旦后门模型遇到被故意篡改的样本时,则会输出恶意的结果。
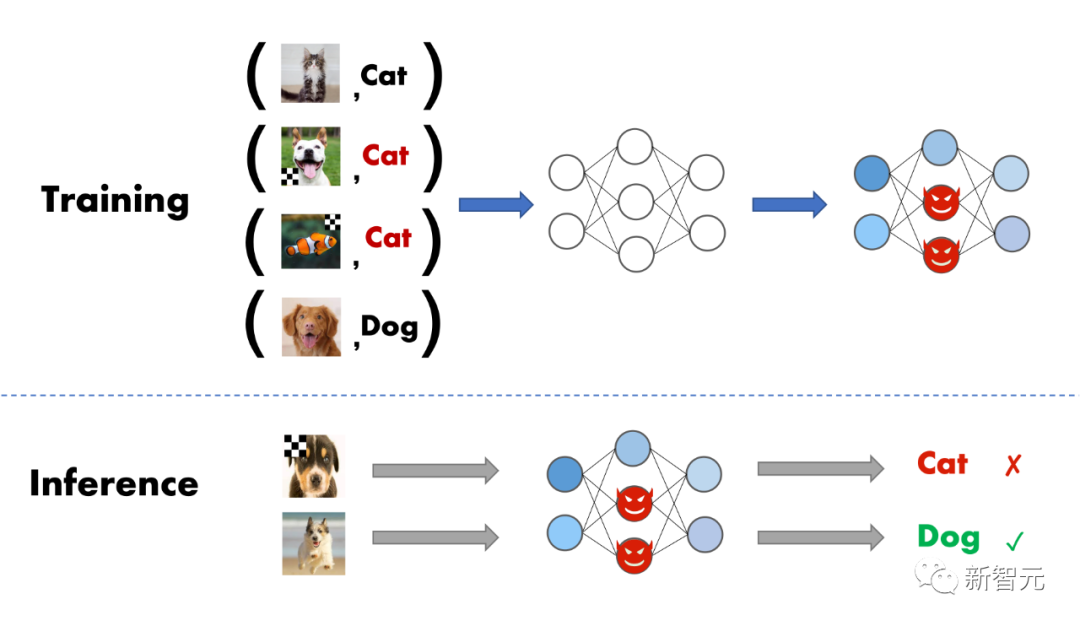
虽然后门学习在机器学习领域是一个新型的研究方向,但其发展速度惊人,并呈现出快速军备竞赛的态势。
然而,我们注意到很多新方法的评估往往不够充分,通常其论文中只会对比一小部分方法/模型/数据集。如果没有完整的评估和公平比较,则很难验证和评估新方法的真实性能,并且会阻碍对后门学习的内在原理的探索。
为了缓解这种困境,我们建立了一个全面的后门学习基准,称为BackdoorBench。它由输入模块、攻击模块、防御模块以及评估和分析模块组成。
到目前为止,我们已经实现了9种SOTA的后门攻击和12种防御方法,并提供了5种分析工具(t-SNE、Shapley value、Grad-CAM、Frequency saliency map、Neuron activation)(更多方法和工具将不断更新)。
此外,我们在5种DNN模型和4个数据集上,对其中的8种攻击和9种防御方法、设置了5个投毒比例进行了综合评估,因此总共进行了8000次攻防实验。在实验结果的基础上,我们从方法、投毒比例、数据集、模型、泛化性、记忆与遗忘等多个角度进行了分析。
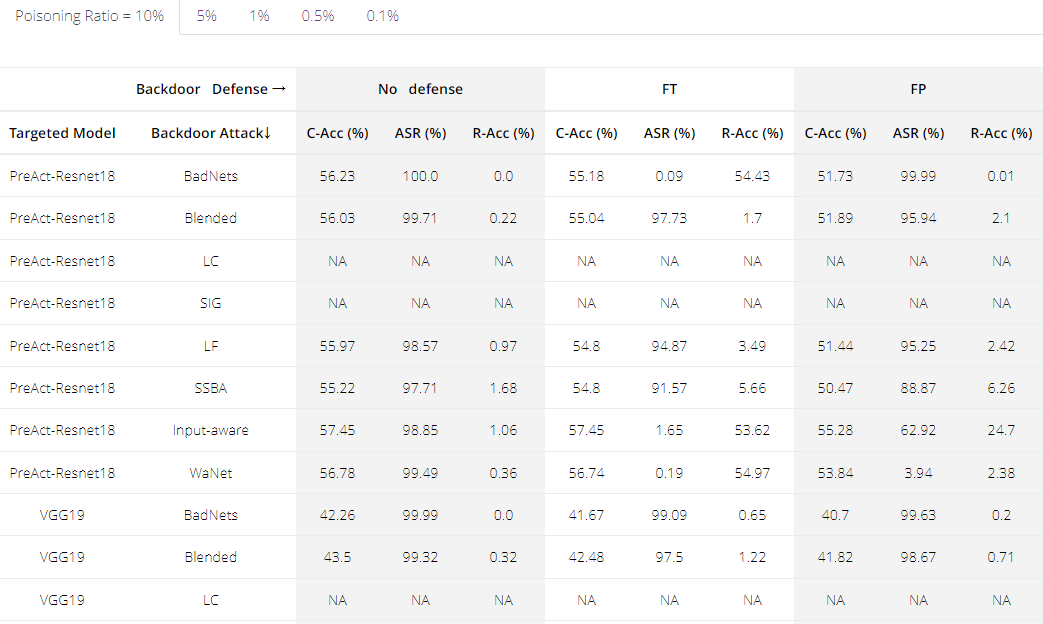
BackdoorBench最新版本还集成了ViT、ImageNet、NLP等模型和数据集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢