
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:假性相关存在情况下的特征学习研究、掩码引导的扩散语义图像编辑、代码语言模型是少样本常识学习器、场景描述到描绘任务的欠规定性、基于递归网络的端到端算法合成、掩码图像建模统一视角、Habitat-Matterport 3D语义数据集、翻转学习让语言模型成为更强大的零样本学习器、用于训练下一代图像-文本模型的开放大规模数据集
1、[LG] On Feature Learning in the Presence of Spurious Correlations
P Izmailov, P Kirichenko, N Gruver, A G Wilson
[New York University]
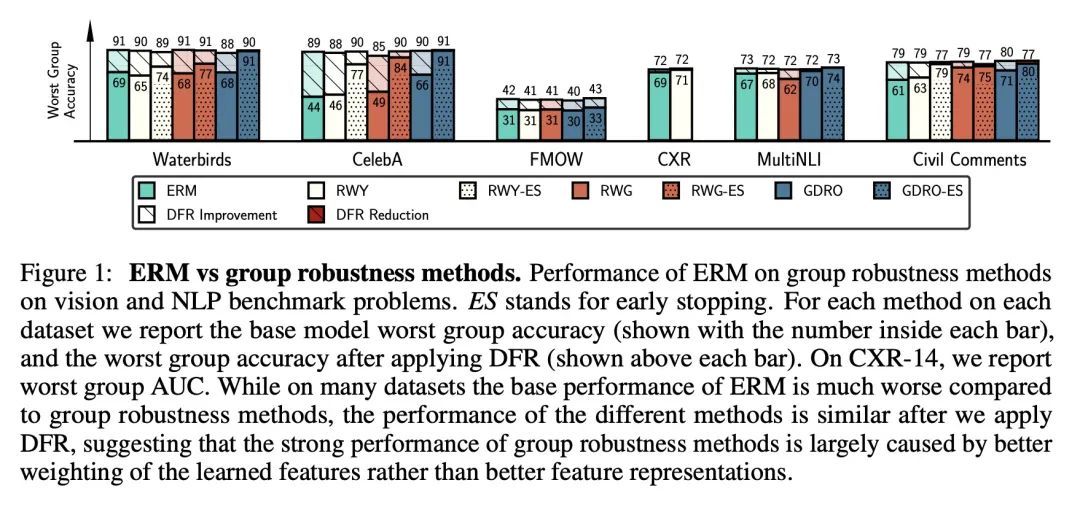
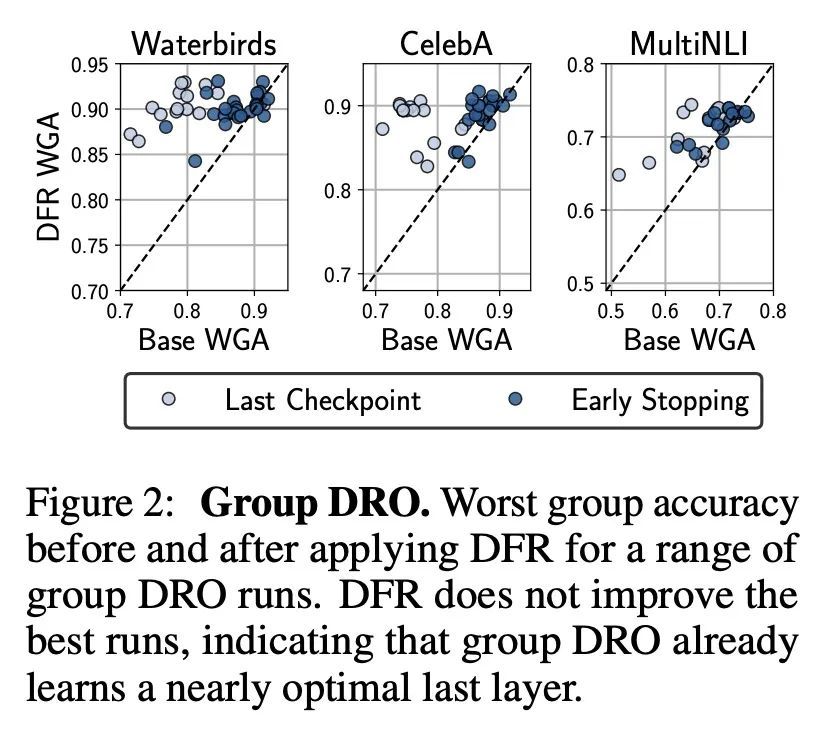
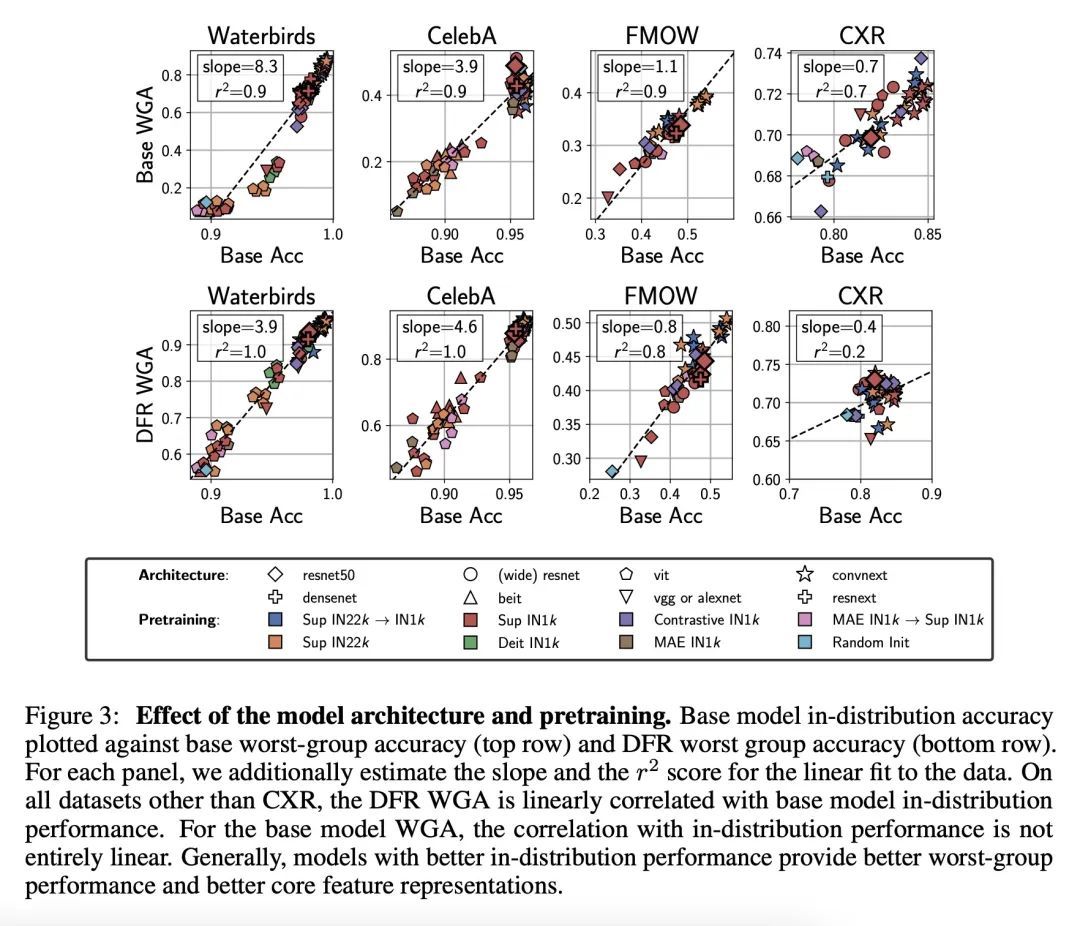
假性相关存在情况下的特征学习研究。众所周知,深度分类器依赖于假性特征——在训练数据上与目标相关,但与学习问题本身并不相关的模式,例如在对前景进行分类时的图像背景。本文评估了关于核心(非虚假)特征的信息量,这些信息可以从通过标准经验风险最小化(ERM)和专门的群鲁棒性训练学到的表示中解码。在最近关于深度特征重加权(DFR)的工作基础上,本文通过用保留集对模型最后一层进行重训练来评估特征表示,并打破假性关联。在多个视觉和NLP问题上,通过简单的ERM学习的特征与通过专门的群鲁棒性方法学习的特征具有很强的竞争力,这些方法旨在减少假性相关的影响。此外,本文还发现,所学特征表示的质量在很大程度上受到训练方法以外的设计决策的影响,如模型结构和预训练策略。强大的正则化对于学习高质量的特征表示是没有必要的。利用以上分析结果,本文大大改进了文献中关于流行的Waterbirds、CelebA发色预测和WILDS-FMOW问题的最佳结果,分别取得了97%、92%和50%的最差组准确率。
Deep classifiers are known to rely on spurious features – patterns which are correlated with the target on the training data but not inherently relevant to the learning problem, such as the image backgrounds when classifying the foregrounds. In this paper we evaluate the amount of information about the core (non-spurious) features that can be decoded from the representations learned by standard empirical risk minimization (ERM) and specialized group robustness training. Following recent work on Deep Feature Reweighting (DFR), we evaluate the feature representations by re-training the last layer of the model on a held-out set where the spurious correlation is broken. On multiple vision and NLP problems, we show that the features learned by simple ERM are highly competitive with the features learned by specialized group robustness methods targeted at reducing the effect of spurious correlations. Moreover, we show that the quality of learned feature representations is greatly affected by the design decisions beyond the training method, such as the model architecture and pre-training strategy. On the other hand, we find that strong regularization is not necessary for learning high quality feature representations. Finally, using insights from our analysis, we significantly improve upon the best results reported in the literature on the popular Waterbirds, CelebA hair color prediction and WILDS-FMOW problems, achieving 97%, 92% and 50% worst-group accuracies, respectively.
https://arxiv.org/abs/2210.11369

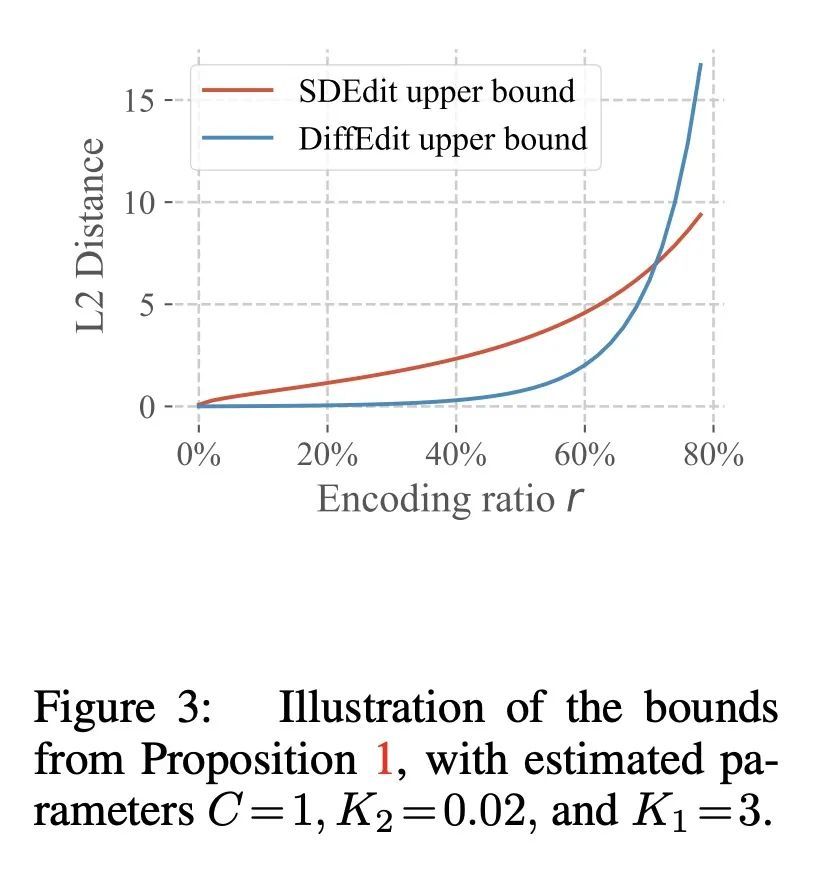
2、[CV] DiffEdit: Diffusion-based semantic image editing with mask guidance
G Couairon, J Verbeek, H Schwenk, M Cord
[Meta AI & Sorbonne Universite]
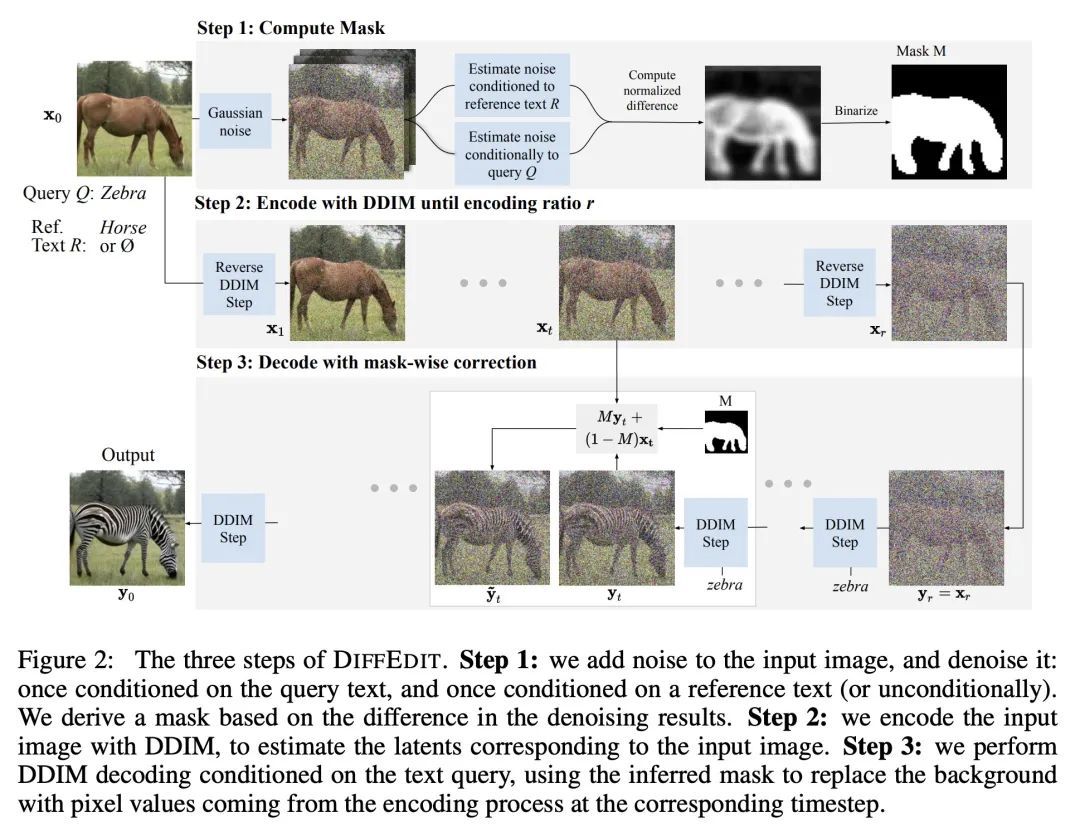
DiffEdit:掩码引导的扩散语义图像编辑。图像生成最近有了巨大的进步,扩散模型可以为大量的文本提示合成令人信服的图像。本文提出DiffEdit,一种利用文本条件扩散模型来完成语义图像编辑任务的方法,其目标是根据文本查询来编辑图像。语义图像编辑是图像生成的延伸,其额外的约束条件是生成的图像应尽可能地与给定的输入图像相似。目前基于扩散模型的编辑方法通常需要提供一个掩码,通过将其视为一个有条件的绘画任务而使任务变得更加容易。相比之下,本文的主要贡献是能自动生成一个掩码,突出输入图像中需要编辑的区域,通过对比不同文本提示条件下的扩散模型的预测。依靠潜在推理来保留这些感兴趣区域的内容,并显示出与基于掩码的扩散的良好协同作用。DiffEdit在ImageNet上实现了最先进的编辑性能。用COCO数据集的图像以及基于文本生成的图像,在更具挑战性的环境中评估了语义图像编辑。
Image generation has recently seen tremendous advances, with diffusion models allowing to synthesize convincing images for a large variety of text prompts. In this article, we propose DiffEdit, a method to take advantage of text-conditioned diffusion models for the task of semantic image editing, where the goal is to edit an image based on a text query. Semantic image editing is an extension of image generation, with the additional constraint that the generated image should be as similar as possible to a given input image. Current editing methods based on diffusion models usually require to provide a mask, making the task much easier by treating it as a conditional inpainting task. In contrast, our main contribution is able to automatically generate a mask highlighting regions of the input image that need to be edited, by contrasting predictions of a diffusion model conditioned on different text prompts. Moreover, we rely on latent inference to preserve content in those regions of interest and show excellent synergies with mask-based diffusion. DiffEdit achieves state-of-the-art editing performance on ImageNet. In addition, we evaluate semantic image editing in more challenging settings, using images from the COCO dataset as well as text-based generated images.
https://arxiv.org/abs/2210.11427


3、[CL] Language Models of Code are Few-Shot Commonsense LearnersA Madaan, S Zhou, U Alon, Y Yang, G Neubig [CMU]
代码语言模型是少样本常识学习器。本文讨论了结构化常识推理的一般任务:给定一个自然语言输入,目标是生成一个图,如事件——或推理图。为了采用大型语言模型(LM)来完成这项任务,现有的方法将输出图"序列化"为节点和边的平面列表。虽然可行,但这些序列化的图与语言模型预训练的自然语言语料有很大偏差,阻碍了LM正确地生成它们。本文表明,当把结构化常识推理任务作为代码生成任务时,预训练的代码语言模型比自然语言的语言模型更适合结构化常识推理,即使下游任务根本不涉及源代码。在三个不同的结构化常识推理任务中展示了所提出的方法。在所有这些自然语言任务中,使用所提出方法,代码生成的语言模型(CODEX)在少样本情况下优于在目标任务上进行了微调的自然语言的语言模型(例如T5)和其他强大的语言模型如GPT-3。
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event -- or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches ``serialize'' the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the few-shot setting.
https://arxiv.org/abs/2210.07128




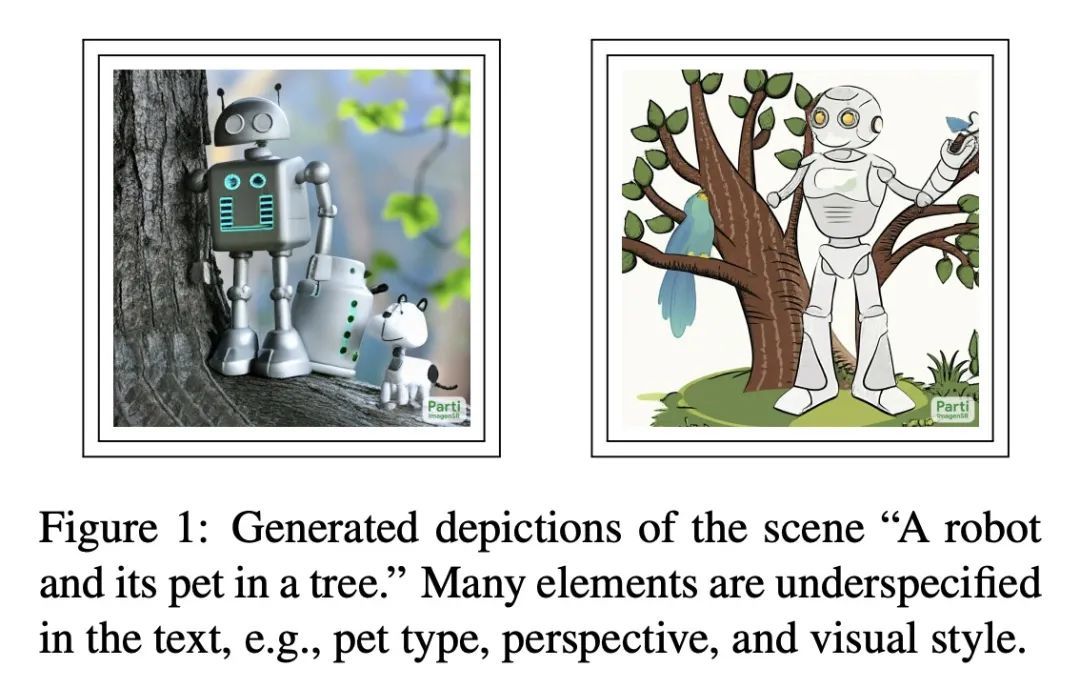
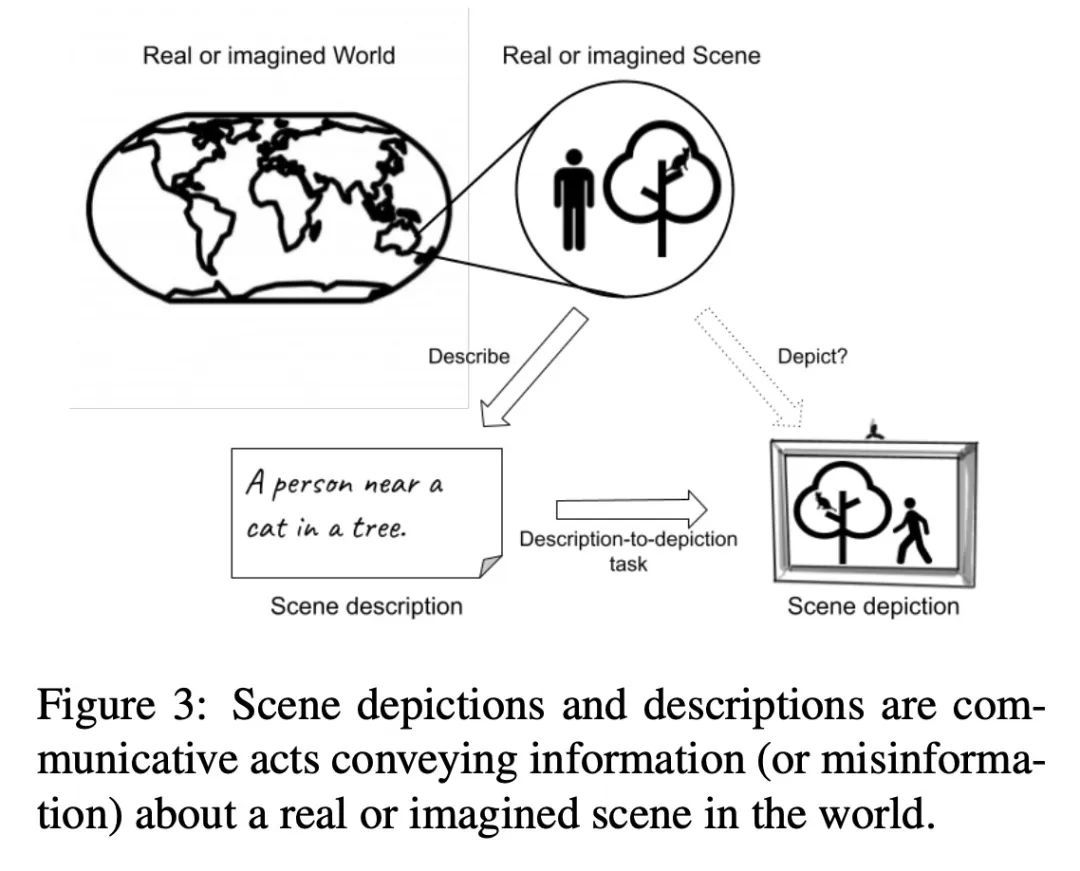
4、[CV] Underspecification in Scene Description-to-Depiction Tasks
B Hutchinson, J Baldridge, V Prabhakaran
[Google Research]
场景描述到描绘任务的欠规定性。有关隐含性、模糊性和不明确性的问题对于理解多模态图像+文本系统的任务有效性和伦理问题至关重要,但迄今为止却很少得到关注。本文描绘了一个概念框架来解决该问题,重点是那些从场景描述中生成描述场景的图像的系统。本文通过该框架说明了文本和图像是如何以不同的方式传达意义的。概述了一系列关于文本和视觉模糊性的核心挑战,以及可能被模糊和不明确的元素所放大的风险。本文提出并讨论了应对这些挑战的策略,包括生成视觉上模糊的图像,以及生成一组不同的图像。
Questions regarding implicitness, ambiguity and underspecification are crucial for understanding the task validity and ethical concerns of multimodal image+text systems, yet have received little attention to date. This position paper maps out a conceptual framework to address this gap, focusing on systems which generate images depicting scenes from scene descriptions. In doing so, we account for how texts and images convey meaning differently. We outline a set of core challenges concerning textual and visual ambiguity, as well as risks that may be amplified by ambiguous and underspecified elements. We propose and discuss strategies for addressing these challenges, including generating visually ambiguous images, and generating a set of diverse images.
https://arxiv.org/abs/2210.05815

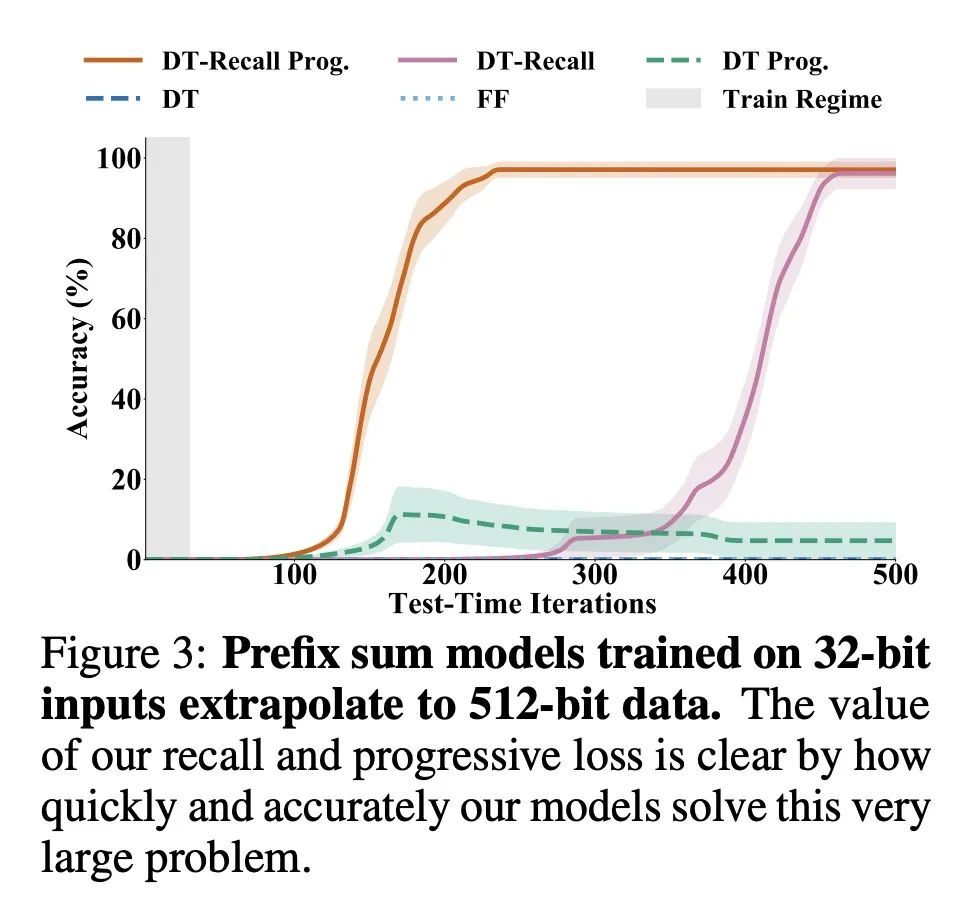
5、[LG] End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking
A Bansal, A Schwarzschild, E Borgnia...
[University of Maryland & University of Chicago & New York University]
基于递归网络的端到端算法合成:避免过思考的逻辑推断。机器学习系统在模式匹配任务上表现良好,但它们进行算法或逻辑推理的能力却没有得到很好的理解。一个重要的推理能力是算法外推,即只在小的/简单的推理问题上训练的模型可以在测试时为大的/复杂的问题合成出复杂的策略。算法外推可以通过循环系统实现,通过多次迭代以解决困难的推理问题。本文观察到,这种方法无法扩展到高度复杂的问题,因为在多次迭代时,行为会退化——将这种问题称为"过思考"。本文提出一种召回架构,将问题实例的明确副本保留在记忆中,这样它就不会被遗忘。本文还采用了一个渐进式的训练程序,防止模型学习特定于迭代次数的行为,而是推动它学习可以无限期重复的行为。这些创新防止了过思考的问题,并使递归系统能够解决极其困难的推断任务。
Machine learning systems perform well on pattern matching tasks, but their ability to perform algorithmic or logical reasoning is not well understood. One important reasoning capability is algorithmic extrapolation, in which models trained only on small/simple reasoning problems can synthesize complex strategies for large/complex problems at test time. Algorithmic extrapolation can be achieved through recurrent systems, which can be iterated many times to solve difficult reasoning problems. We observe that this approach fails to scale to highly complex problems because behavior degenerates when many iterations are applied -- an issue we refer to as "overthinking." We propose a recall architecture that keeps an explicit copy of the problem instance in memory so that it cannot be forgotten. We also employ a progressive training routine that prevents the model from learning behaviors that are specific to iteration number and instead pushes it to learn behaviors that can be repeated indefinitely. These innovations prevent the overthinking problem, and enable recurrent systems to solve extremely hard extrapolation tasks.
https://arxiv.org/abs/2202.05826



另外几篇值得关注的论文:
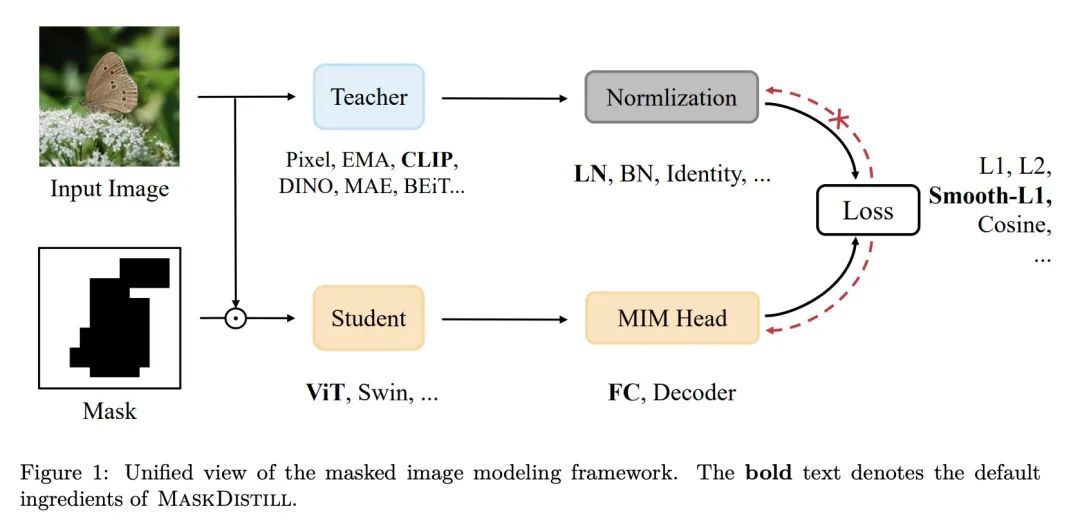
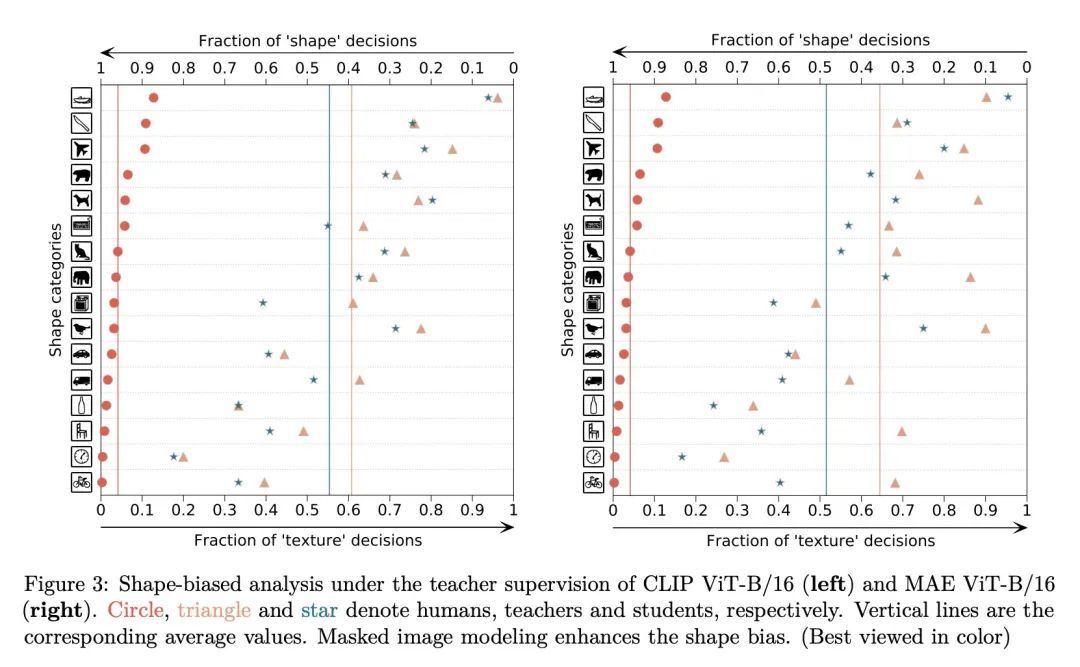
[CV] A Unified View of Masked Image Modeling
掩码图像建模统一视角
Z Peng, L Dong, H Bao, Q Ye, F Wei
[University of Chinese Academy of Sciences & Microsoft Research]
https://arxiv.org/abs/2210.10615


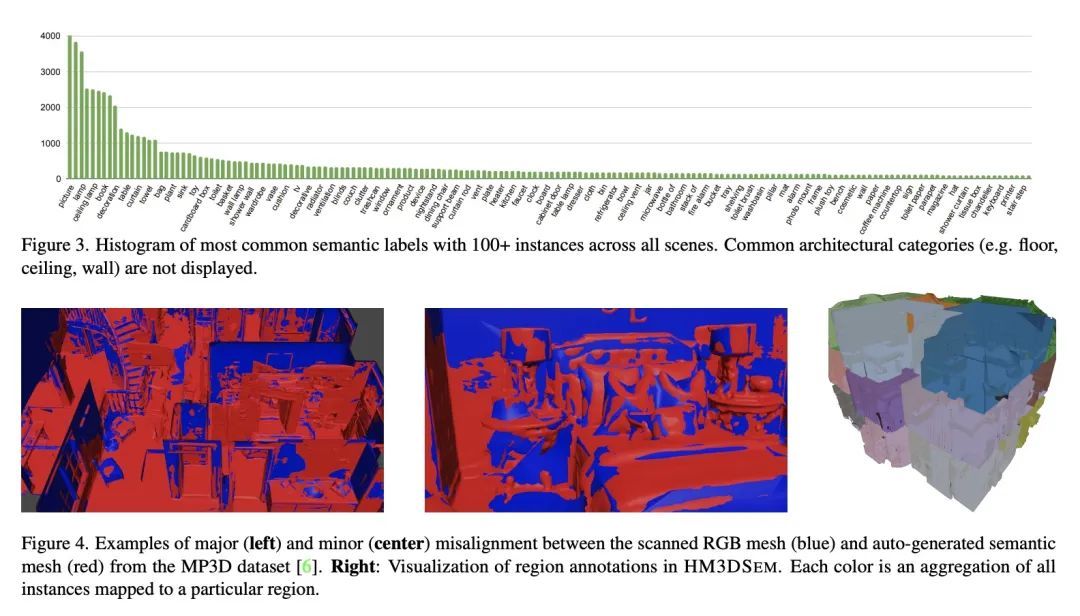
[CV] Habitat-Matterport 3D Semantics Dataset
Habitat-Matterport 3D语义数据集
K Yadav, R Ramrakhya, S K Ramakrishnan...
[Meta AI & Georgia Tech & UT Austin & Cornell University & Simon Fraser University & CMU]
https://arxiv.org/abs/2210.05633



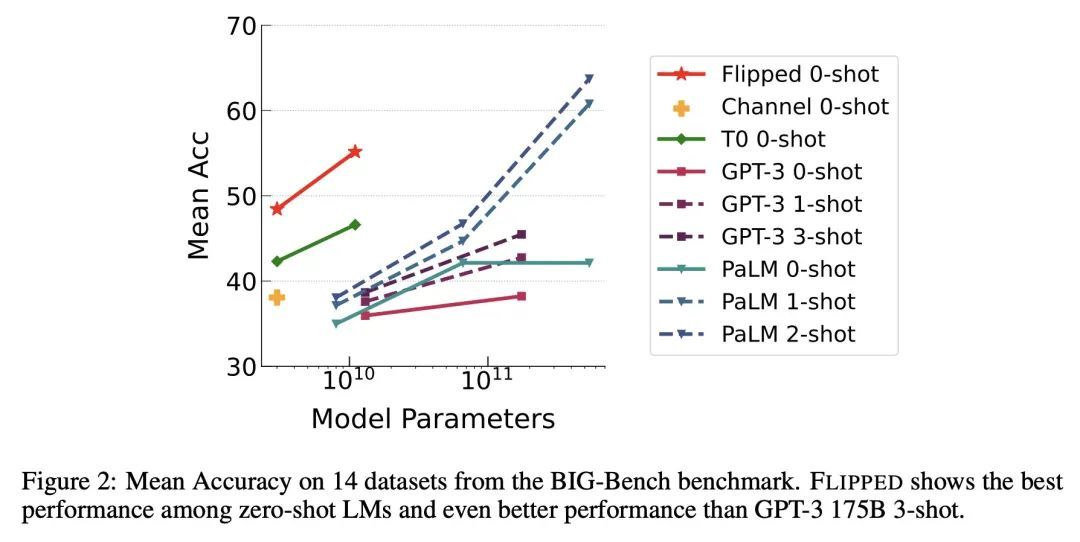
[CL] Guess the Instruction! Flipped Learning Makes Language Models Stronger Zero-Shot Learners
翻转学习让语言模型成为更强大的零样本学习器
S Ye, D Kim, J Jang, J Shin, M Seo
[KAIST & LG AI Research]
https://arxiv.org/abs/2210.02969


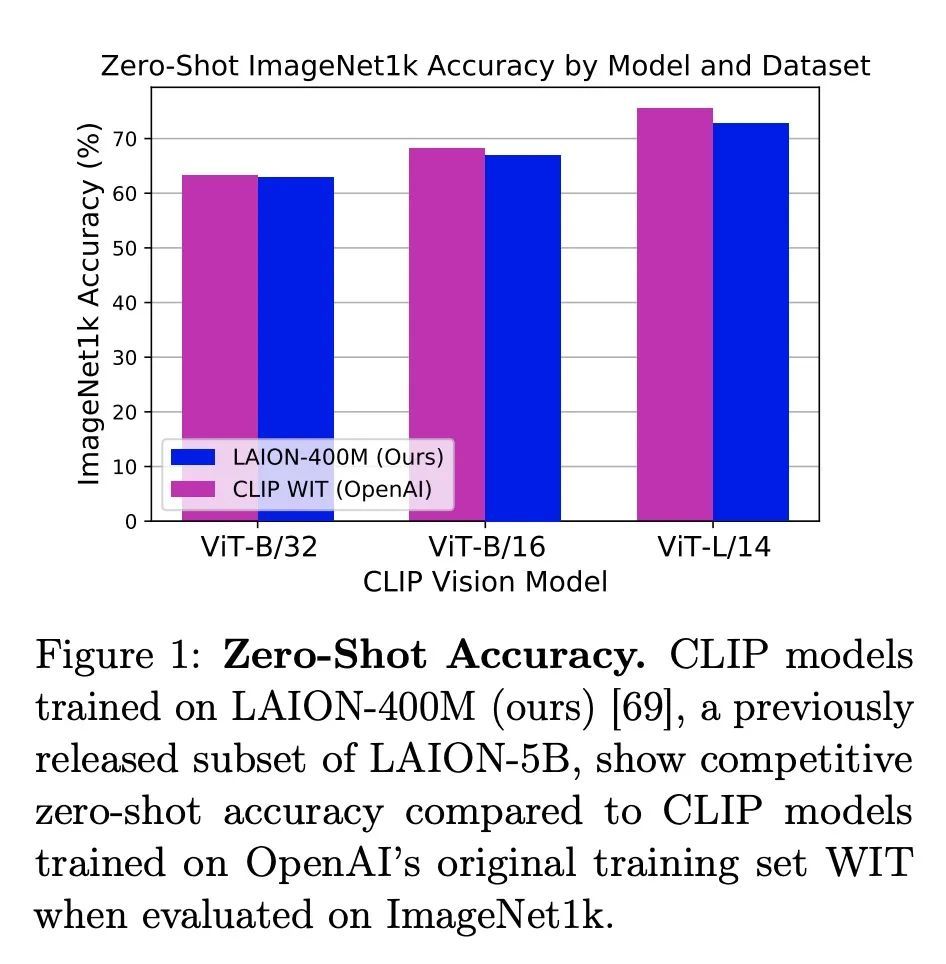
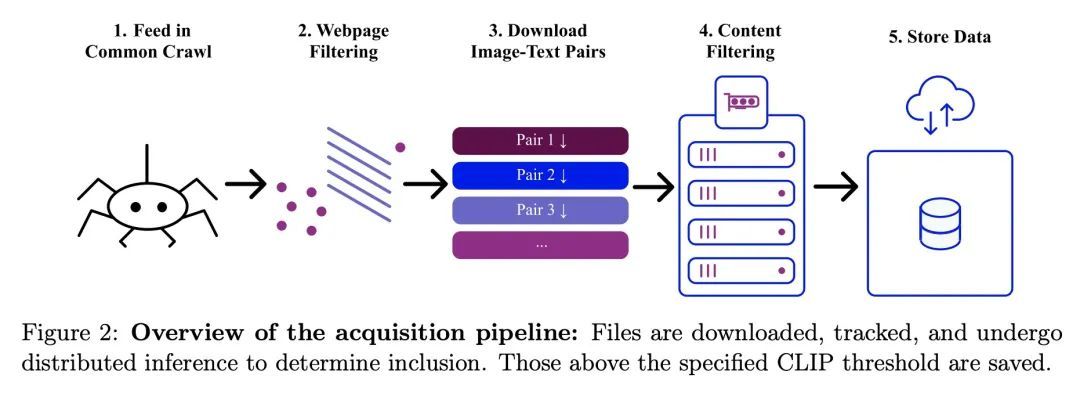
[CV] LAION-5B: An open large-scale dataset for training next generation image-text models
LAION-5B:用于训练下一代图像-文本模型的开放大规模数据集
C Schuhmann, R Beaumont, R Vencu, C Gordon, R Wightman, M Cherti...
[LAION & UC Berkeley & University of Washington]
https://arxiv.org/abs/2210.08402


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢