
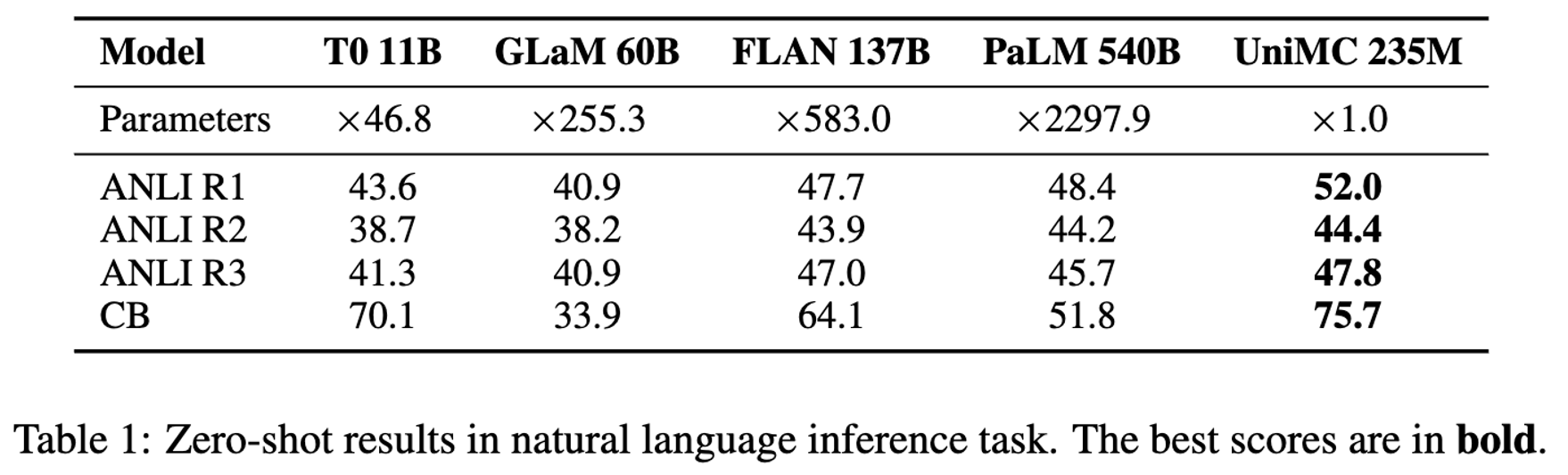
自从 GPT-3 问世,展现出千亿级模型的强大实力以来,NLP 任务面临着规模、样本、Fine-tuning 性能的不可能三角。如何在保证 10 亿参数以下的语言模型可以达到 SOTA 的 Few-Shot (甚至是 Zero-shot)还有 Fine-tuning 的性能?一定要上千亿的参数并且忍受不稳定的 prompt 提示才可以解决 zero-shot 场景吗?本文中,IDEA 研究院封神榜团队介绍了一种新的「表现型」UniMC,仅有 2 亿参数即可达到 Zero-shot 的 SOTA。相关工作已经被 EMNLP 2022 接收。
最近封神榜团队被 EMNLP 2022 收录的论文:《Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective》则打破了这一「魔咒」,提供了一个灵活高效的解决思路。我们的论文提出的 UniMC 在拥有模型参数量很小(仅仅是亿级)和 SOTA 的 Fine-tuning 能力的前提下,同时还能拥有(与 5400 亿的 PaLM 相当的) SOTA 的 Few/Zero-Shot 性能。
模型结构
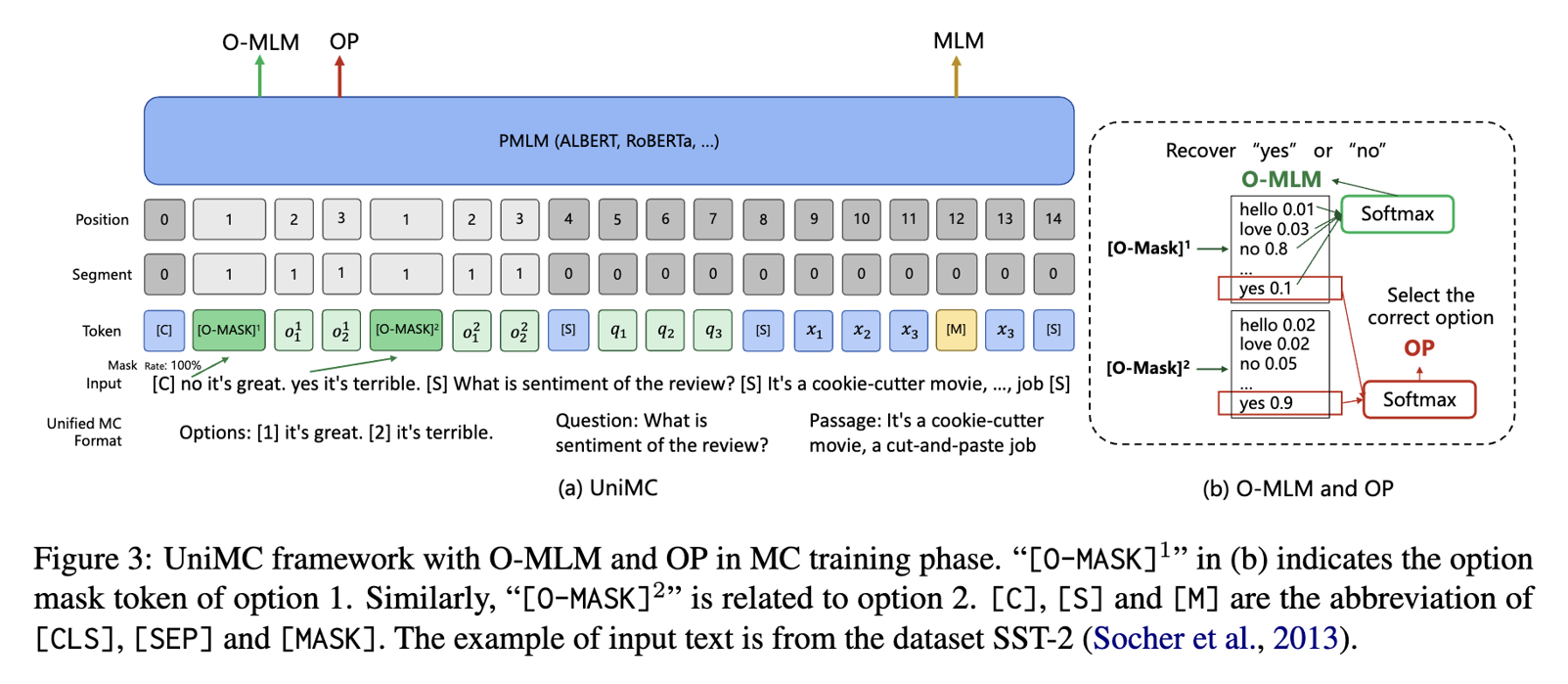
UniMC 的结构如下图所示,它采用类似于 BERT 的自编码结构。主要流程为,我们先统一好不同任务的输入,并且限制好输入信息之间的流通性,经过 PMLM 之后,利用 O-MLM、OP 和 MLM 进行 MC training,最后使用 O-MLM 和 OP 进行 zero-shot 预测。接下来我将一步一步地拆解我们的方案。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢