
今天介绍下面这篇工作。做的内容是最近大火的图像文本联合预训练(Vision-Language pretraining)在医疗领域的应用。这篇文章的亮点主要是:
1. 探索了如何处理 False Negative 样本对预训练的影响;
2. 探索了怎么样在样本有限的情况下,最大化的扩充正负样本对来提高多模态预训练的 data efficiency。

论文链接:
代码链接:
针对上面的这两个问题,我们希望能够解耦(decouple)图片和文本的配对关系,转而用一个人工构建的弱标签系统作为匹配图片和文本的工具。见下图。
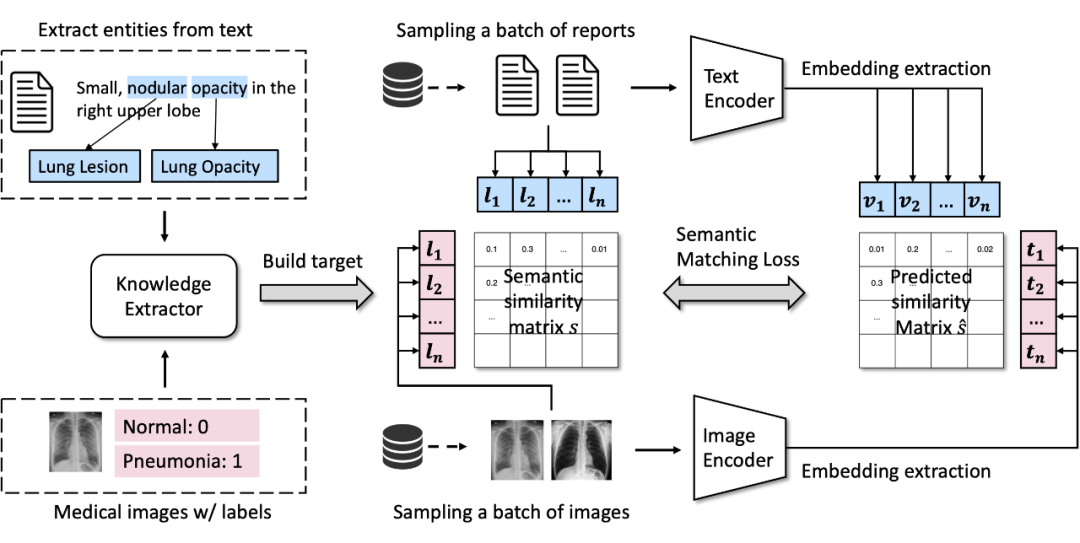
▲ MedCLIP的基本架构
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢