

paper:https://arxiv.org/abs/2206.03687
代码:https://github.com/zhiyuanyou/UniAD
异常检测已经取得了非常突出的进展。考虑到异常的多样性,通常的异常检测方案是首先拟合出正常样本的分布,之后检测该分布之外的离群点作为异常。因此,异常检测需要学习出一个非常紧凑的正常样本的边界 (下图a)。出于这种目的,当前所有的异常检测方法都只能用一个模型解决一个类别 (下图c)。但是,这种“一个模型只处理一个类别”的separate setting是十分耗费储存空间的,并且无法处理正常样本具有一定多样性的场景 (比如,一种物体有多种正常的型号)。
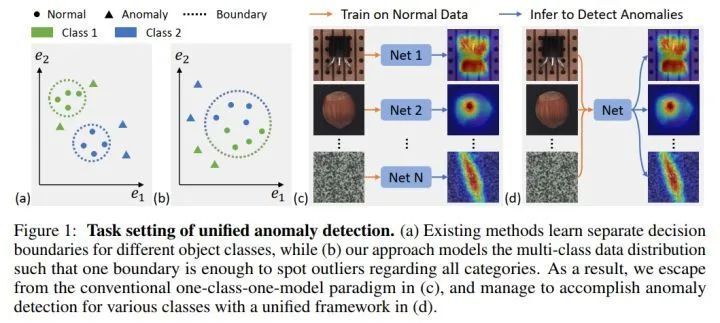
我们致力于解决一个更困难的unified setting,那就是用一个模型解决所有类别的异常检测 (上图d)。这就需要所有类别共享相同的分类边界 (上图b),因此,如何拟合出多类正常样本的分布是十分重要的。
基于重构的方法是一种常用的异常检测方法。这种方法在正常样本上训练一个重构模型,并假设重构只能在正常样本上成功,对于异常样本将会具有较大的重构误差。因此,重构误差可以作为异常评分。但是,基于重构的方法会遇到“恒等映射”的问题。所谓“恒等映射”指的是,虽然重构模型是在正常样本上训练的,其遇到异常样本同样会重构成功。这使得正常样本和异常样本的重构误差都很小,难以被区分开来。更重要的是,相比于传统的separate setting,在unified setting下,正常样本的分布更加复杂,这加剧了“恒等映射”的问题 (详见paper的实验及分析)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢