

本文简要介绍ECCV 2022录用论文“GLASS: Global to Local Attention for Scene-Text Spotting”的主要工作。这篇文章针对场景文字端到端识别任务,提出了一个从全局到局部的注意力模块。这个模块结合了全局特征(从共享的主干网络中提取的特征)和局部特征(从原图中裁剪下来的图片,然后再送入一个识别的主干网络提取的特征)融合到一起再进行识别,极大提升了模型的性能。同时文章还提出了一个新的损失函数来提升模型对旋转文本识别的能力。在多个公开数据集上,该论文提出的模型都取得了很好的效果。论文提出的模型也可以用到现在有的框架上。
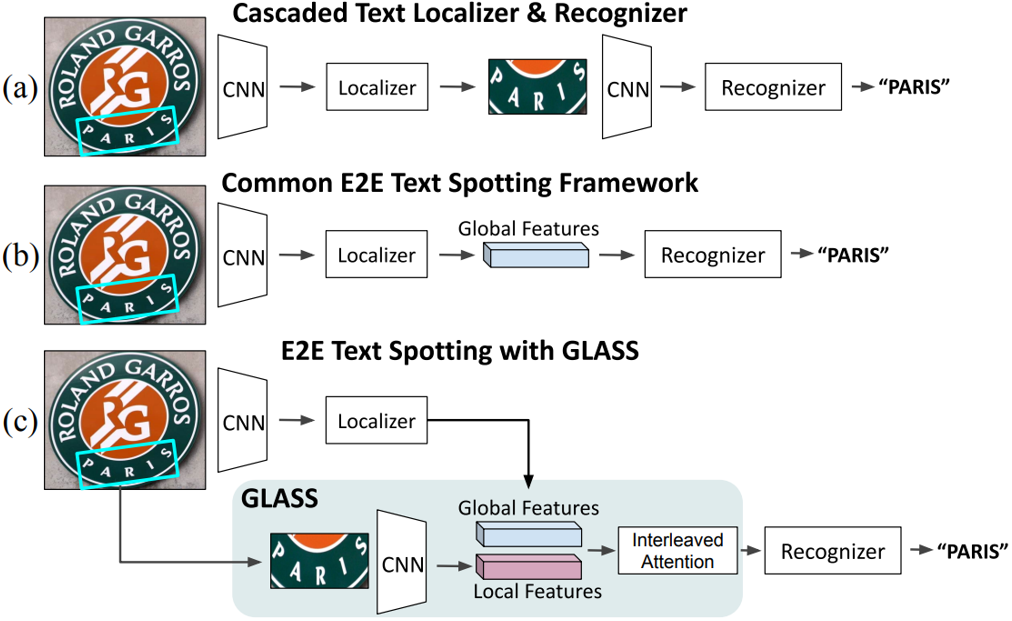
图1. 场景文字端到端识别方法总览。(a)两阶段检测识别。一个独立的文本检测器后面跟着一个独立的识别器。两者是单独训练的。(b) 端到端文字识别。检测与识别协同优化。(c)论文提出的模块同时结合了(a)和(b)的优势。特征图使用交错注意进行融合,提高了对缩放和旋转的鲁棒性,以及整体性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢