
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
论文名称:Token Merging: Your ViT But Faster
论文地址:https://arxiv.org/pdf/2210.09461.pdf
1 背景和动机
与卷积神经网络 (CNN) 相比,视觉 Transformer 模型 (ViT) 有一系列优良的性质,比如:
- Transformer 模型的 Attention 模块和 MLP 模块主要有矩阵乘法这种可以加速的操作构成。
- Transformer 支持一些性能强大的自监督学习任务 (掩码图像建模 MAE 等等)。
- Transformer 适配多种模态的输入数据 (图片,文本,音频等)。
- Transformer 对于超大规模数据集 (ImageNet-22K) 的泛化性好,预训练之后的模型在下游任务中 (比如 ImageNet-1K 图像分类任务) 表现卓越。
但是在资源受限的边缘设备 (如手机和无人机) 上实际运行 Transformer 不太友好,因为 Transformer 模型又相对较大的延时。一种常见的加速视觉 Transformer 模型的方法是对 token (图片 Patch) 进行剪枝。比如 DynamicViT[1],AdaViT[2],A-ViT[3],SPViT[4]等。这些 token Pruning 方法虽然在精度方面能够实现不错的效果,但是 token 剪枝的缺点有:
- 需要额外的训练过程,对资源不友好。
- token 剪枝限制了模型的实用性,当 token 数量随着输入的变化而发生变化时,无法进行批处理 (Batch Inference)。为了解决这个问题,大多数 token 剪枝的工作借助了 Mask,对冗余的 token 进行遮挡。但是这样的做法并没有真正剪去这些冗余的 token,使得这些方法并不能在实际业务中真正加速。
- token 剪枝带来的信息损失限制了可以允许剪枝的 token 数量。
另一种加速 ViT 的做法是对 token (图片 Patch) 进行融合。比如 Token Pooling[5],Token Learner[6]。和本文方法最接近的 Token Pooling 使用了一个缓慢的基于 k-means 的方法,但是速度较慢,不适用于现成的模型。
本文希望做一个无需训练并且兼顾性能-速度权衡的 token 融合方法。因为其无需训练的优良属性,对于大模型将会非常友好。在训练过程中使用 ToMe,可以观察到训练速度增长,总训练时间缩短了一半。
2 Token Merging 的基本思路
Token Merging 的基本思路是在一个 ViT 模型中间插入一些 token merging 的模块, 希望把这些模块植入 ViT 以后, 训练和推理的速度都有提升。基本作法是在每一个层之后减少 个 token, 那么一个有 层的 Transformer 模型从头到尾减少的 token 数量就是 。这个 值越高, 减少的 token 数量就越多, 但是精度也会越差。而且值得注意的是, 无论一张输入图片有多少个 tokens, 都会减少 个 token, 而不是像上文的 token 剪枝算法那样使得 token 的数量动态变化。为什么这么设计呢? 原因就是如上文所述当 token 数量随着输入的变化而发生变化时, 无法进行批处理 (Batch Inference), 使得这些方法并不能在实际业务中真正加速。
如下图1所示是 Token Merging 的示意图,ToMe 的位置被插在 Attention 模块和 MLP 模块之间,因为作者希望借助 Attention 中的特征帮助决定该去融合哪些 tokens。
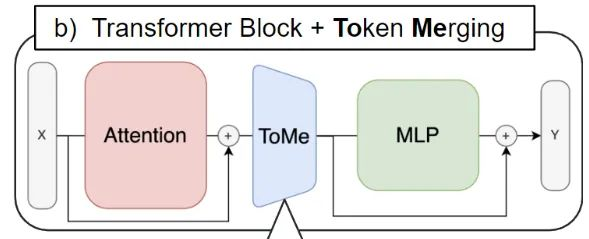
图1:Token Merging 的位置
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢