
人工智能一个重要的目标是开发泛化能力强的模型。在自然语言处理(NLP)领域中,预训练语言模型在这方面取得了重大进展。这类模型往往通过微调来适应新的任务。
近日,来自谷歌的研究者分析了多种指令微调方法,包括扩展对指令微调的影响。实验表明,指令微调确实可以根据任务数量和模型大小实现良好的扩展,最大到 5400 亿参数的模型都能明显受益,未来的研究应该进一步扩大任务的数量和模型的大小。此外,该研究还分析了微调对模型执行推理能力的影响,结果都是很吸引人的。
由此产生的 Flan-T5 对 1800 余种语言任务进行了指令微调,明显提高了提示和多步推理能力,30 亿参数跑基准就能超过 GPT-3 的 1750 亿参数。
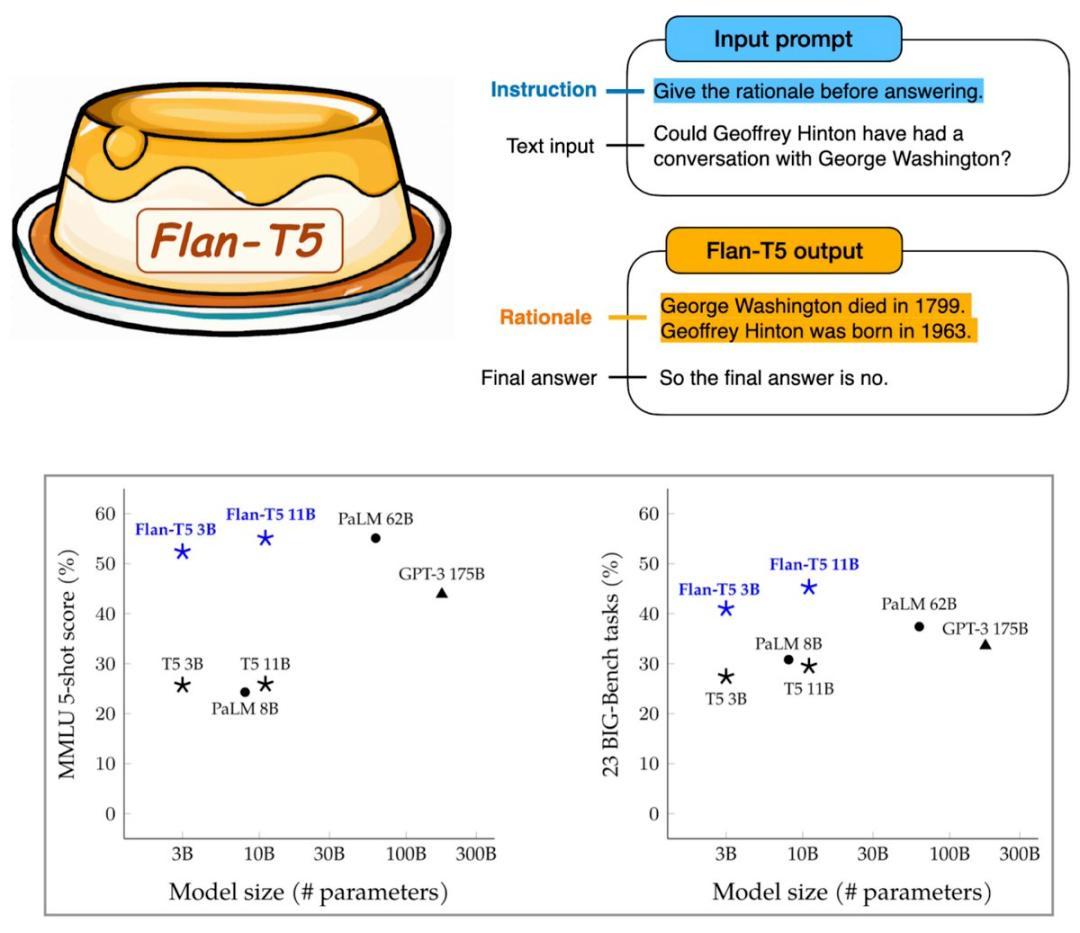
看起来谷歌又为大模型找到了一个能力提升的方向。不过这一研究不仅引来了机器学习社区的欢迎,也有 Gary Marcus 的吐槽:

谷歌的模型为什么把谷歌自己的著名科学家 Geoffrey Hinton 的出生日期搞错了?人家明明是 1947 年出生的老前辈。
论文作者之一的谷歌大脑首席科学家 Quoc Le 赶紧出来圆场:是临时工图片做错了,在论文里 Flan-T5 模型其实没有把 Geoff 的出生年月搞错,有图为证。

顺便说一句,出生于 1963 年的著名 AI 学者是 Jürgen Schmidhuber。
既然出错的不是 AI 模型,让我们看看谷歌的新方法究竟能够为预训练模型带来哪些改变吧。
论文:Scaling Instruction-Finetuned Language Models

- 论文地址:https://arxiv.org/abs/2210.11416(opens new window)
- 公开模型:https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢