
【论文标题】Large Language Models Can Self-Improve
【作者团队】Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han
【发表时间】2022/10/25
【机 构】UIUC、谷歌
【论文链接】https://arxiv.org/pdf/2210.11610v2.pdf
大语言模型(LLMs)在各种任务中都取得了出色的表现,然而对LLM进行微调需要大量的监督信息。另一方面,人类可以在没有外部输入的情况下通过自我思考来提高推理能力。对此,本文证明了LLM也能够在只有未标记的数据集的情况下进行自我改进,使用预训练大模型,利用思维链提示和自洽性,为无标签的问题生成高置信度的理性增强答案,并使用这些自生成的数据作为标签输出来微调LLM。本文的方法提高了540B参数的LLM的一般推理能力,在达到了最先进的水平的同时不需要任何真实标签。本文也进行了消融研究,并表明推理部分的微调对于自我改进至关重要。
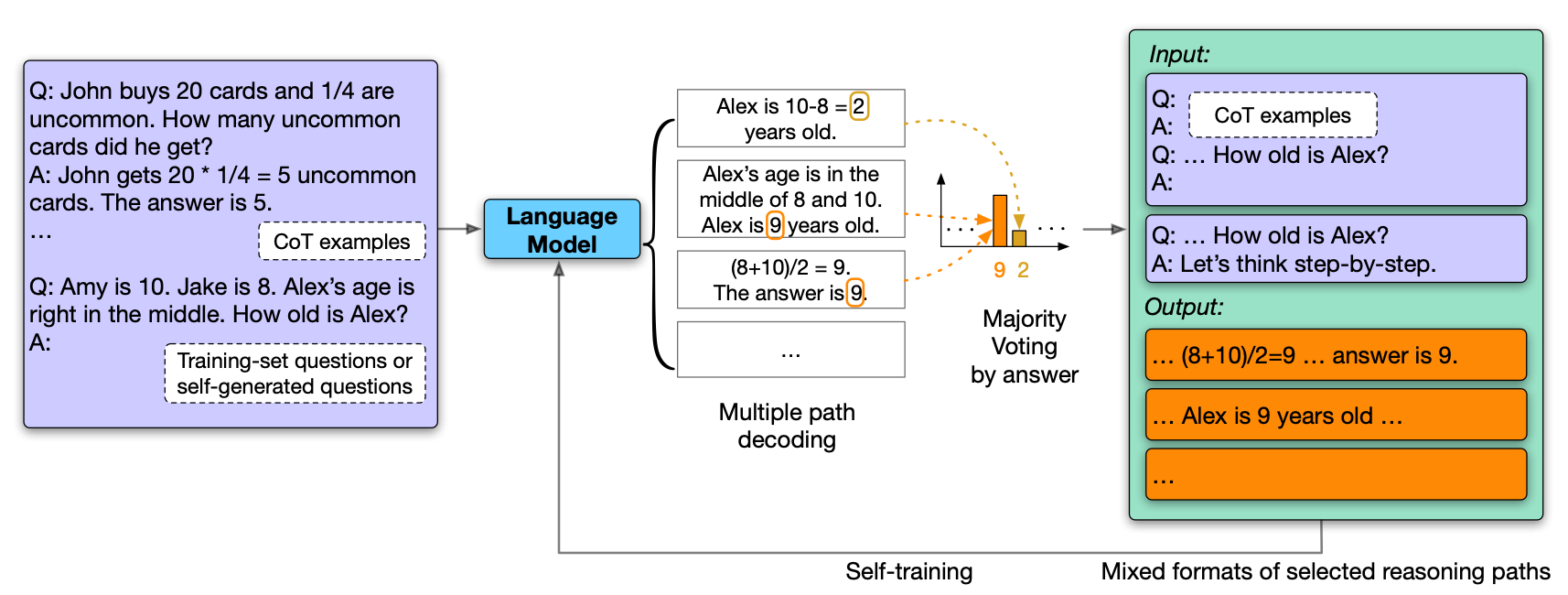
上图展示了本文的方法LMSI(Language Model Self-Improved)的框架以及思维链(CoT)的例子。基于预训练大模型,只有问题的数据集和少数CoT,语言模型应用多路径解码为每个问题生成多个CoT推理路径和答案,通过多数投票(自洽性)选出最自洽的高置信度的答案,这个CoT推理路径会被混合格式的提示和答案所增强,并使用这些自生成的推理-答案数据作为最终的训练样本反馈给模型进行微调,在没有监督数据的基础上对模型进行自我改进。

上图展示了给定问题的3个自生成的CoT推理路径的例子,输出1和3是基于多数人投票的最一致的推理路径,并作为自训练数据保存。
另外本文也研究了在问题或CoT例子的数量有限时,如何自生成更多的训练问题以及例子提示。本文使用一个简单而有效的方法来为领域内的问题生成不同的问题。具体来说,随机选择几个现有的问题,以随机顺序串联起来作为输入提示,并让语言模型生成连续的序列作为新的问题。本文重复这个过程以获得一大批新问题,然后使用自洽性评估,只保留那些有高置信答案的问题,然后,这些问题被用作自生成的训练问题。

上图展示了推理路径被增强为四种格式的训练数据的例子,目的为防止语言模型过拟合特定的提示或答案,包括不同的提示(输入)和答案(输出)。
在第一种格式中,思维链的例子被预置到新问题中,而语言模型的输出被训练成与过滤后的CoT推理路径相同。
在第二种格式中,使用问题的例子和它们的直接答案作为标准提示,而语言模型的输出也应该只包含直接答案。
第三和第四种格式与第一和第二种格式类似,只是没有给出问题-答案的例子,这样模型就会通过上下文学会自己思考。在第三种格式中,本文希望模型在不预留包含CoT推理的例子的情况下输出CoT推理,在输入序列的末尾附加 "让本文一步一步地思考",以引导语言模型生成一步一步的CoT推理路径。
最终,混合格式的训练样本被用来微调预先训练好的语言模型 。
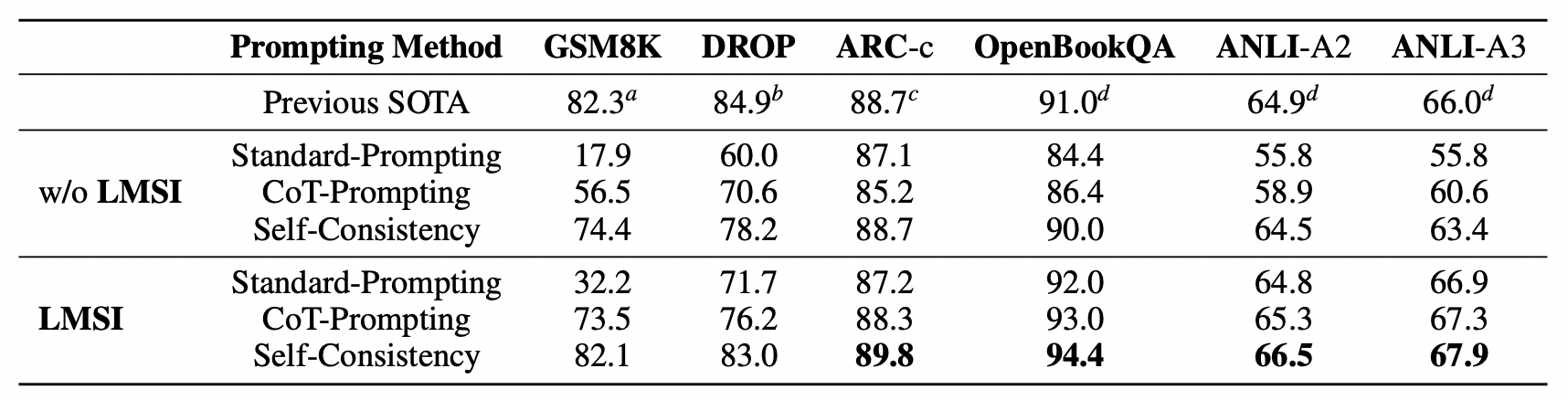
上图展示了在PaLM-540B模型上使用与否LMSI进行微调的结果,本文比较了标准-提示,CoT-提示,和多路径投票自洽性三种提示方法。可以观察到,在LMSI之后,所有三种提示方法的性能都有明显的改进。在自洽性的比较中,LMSI实现了在GSM8K上+7.7%,在DROP上+4.8%,在OpenBookQA上+4.4%,在ANLI-A3上+4.5%。这表明,本文提出的方法是相当有效的。此外,LMSI的单路径CoT-提示性能接近甚至优于没有LMSI的模型的多路径自洽性性能,表明LMSI真正帮助语言模型从多个的推理路径中学习。
本文还将本文的结果与以前的SOTA进行了比较,本文方法在ARC-c、OpenBookQA、ANLI-A2和ANLI-A3上,LMSI超过了以前的SOTA。在GSM8K数据集上,LMSI接近DiVeRSe方法,对比的方法使用了不同的提示和投票来组合100条输出路径。相反,本文只用了32个输出路径,用于自生成训练样本和与LMSI的自洽性。在DROP数据集上,LMSI接近于OPERA方法,后者使用真实标签进行训练,而本文的方法只利用了训练集中的问题,没有使用真实标签。
创新点
- 通过利用CoT推理和自洽性,一个大型语言模型可以通过采用没有真实输出的数据集进行自我改进,达到有竞争力的域内多任务效果以及域外泛化。
- 本文对微调后的训练样本格式和采样温度进行了详细的消融研究,并确定了大语言模型最成功的自我改进的关键设计。
- 本文研究了另外两种自我改进的方法,即模型从有限的输入问题中生成附加的问题,以及自己生成少量的CoT提示模板。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢