
作者:Mozes van de Kar, Mengzhou Xia, Danqi Chen, Mikel Artetxe
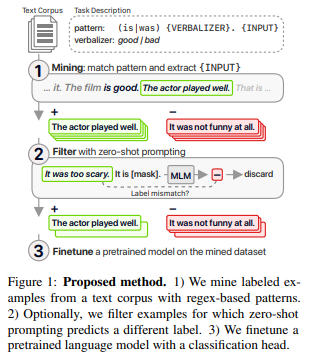
简介:本文研究在零样本场景中优于Prompt的基于挖掘的方法。像 BERT 这样的掩码语言模型,可以通过将下游任务重新定义,为文本填充来以零样本的方式执行文本分类。然而,这种方法对用于提示模型的模板高度敏感,而从业者在严格的零样本设置下设计它们时是盲目的。在本文中,作者提出了一种基于挖掘的替代方法来进行零样本学习。作者不使用Prompt语言模型,而是使用正则表达式从未标记的语料库中挖掘标记示例,可以选择通过Prompt进行过滤,并用于微调预训练模型。作者的方法比Prompt更灵活和可解释,并且在使用可比较的模板时在广泛的任务中更胜一筹。
论文下载:https://arxiv.org/pdf/2210.14803.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢