
作者:Avinash Madasu, Shashank Srivastava
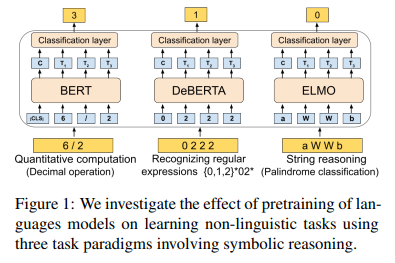
简介:本文研究探索预训练语言模型的非语言归纳偏差。大型语言模型 (LM) 已迅速成为自然语言处理的支柱。众所周知,这些模型可以通过对大量文本的训练获得丰富的语言知识。在本文中,作者研究了文本预训练是否也赋予这些模型以有助于非语言推理的“归纳偏差”。在一组 19 个不同的非语言任务上,涉及定量计算、识别正则表达式和对字符串进行推理。作者发现预训练模型明显优于可比较的非预训练神经模型。在使用较少参数训练非预训练模型以考虑模型正则化效果的实验中,这也是如此。作者通过来自不同域和出处的文本预训练模型,进一步探索文本域对 LM 的影响。作者的实验出人意料地表明:即使在对多语言文本或计算机代码进行预训练,甚至对从合成语言生成的文本进行预训练时,预训练的积极效果也会持续存在。作者的研究结果表明:语言模型的预训练和归纳学习能力之间存在迄今为止尚未探索的深层联系。
论文下载:https://arxiv.org/pdf/2210.12302.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢