

本文简要介绍发表在ECCV 2022上关于手写数学公式识别的论文《CoMER: Modeling Coverage for Transformer-based Handwritten Mathematical Expression Recognition》。该论文针对现有基于Transformer的数学公式识别方法中存在注意力覆盖不足的问题,提出了一种新的注意精炼模块(ARM),将RNN模型中广泛采用的覆盖注意力机制巧妙地应用在Transformer中,可以在不影响并行性的前提下,利用过去的对齐信息精炼注意权重。另外,文章通过提出自覆盖和交叉覆盖两种模块,利用来自当前层和前一层的过去对齐信息,从而更好地利用覆盖信息。相关代码已开源在https://github.com/Green-Wood/CoMER
一、研究背景
手写数学公式识别是将包含数学表达式的图像转换为结构表达式,例如LaTeX数学表达式或符号布局树的过程。手写数学表达式的识别已经带来了许多下游应用,如在线教育、自动评分和公式图像搜索。在在线教育场景下,手写数学表达式的识别率对提高学习效率和教学质量至关重要。
对比于传统的文本符号识别(Optical Character Recognition, OCR),公式识别具有更大的挑战性。公式识别不仅需要从图像中识别不同书写风格的符号,还需要建模符号和上下文之间的关系。例如,在LaTeX中,模型需要生成“^”、“_”、“{”和“}”来描述二维图像中符号之间的位置和层次关系。编码器-解码器架构由于可以编码器部分进行特征提取,在解码器部分进行语言建模,而在手写数学公式识别任务(Handwritten Mathematical Expression Recognition, HMER)中被广泛使用。
虽然Transformer在自然语言处理领域已经成为了基础模型,但其在HMER任务上的性能相较于循环神经网络(Recurrent Neural Network, RNN)还不能令人满意。作者观察到现有的Transformer与RNN一样会受到缺少覆盖注意力机制的影响,即“过解析”——图像的某些部分被不必要地多次解析,以及“欠解析”——有些区域未被解析。RNN解码器使用覆盖注意机制来缓解这一问题。然而,Transformer解码器所采用的点积注意力没有这样的覆盖机制,作者认为这是限制其性能的关键因素。
不同于RNN,Transformer中每一步的计算是相互独立的。虽然这种特性提高了Transformer中的并行性,但也使得在Transformer解码器中直接使用以前工作中的覆盖机制变得困难。为了解决上述问题,作者提出了一种利用Transformer解码器中覆盖信息的新模型,称为CoMER。受RNN中覆盖机制的启发,作者希望Transformer将更多的注意力分配到尚未解析的区域。具体地说,作者提出了一种新颖的注意精炼模块(Attention Refinement Module, ARM),它可以在不影响并行性的前提下,根据过去的对齐信息对注意权重进行精炼。同时为了充分利用来自不同层的过去对齐信息,作者提出了自覆盖和交叉覆盖,分别利用来自当前层和前一层的过去对齐信息。作者进一步证明,在HMER任务中,CoMER的性能优于标准Transformer解码器和RNN解码器。
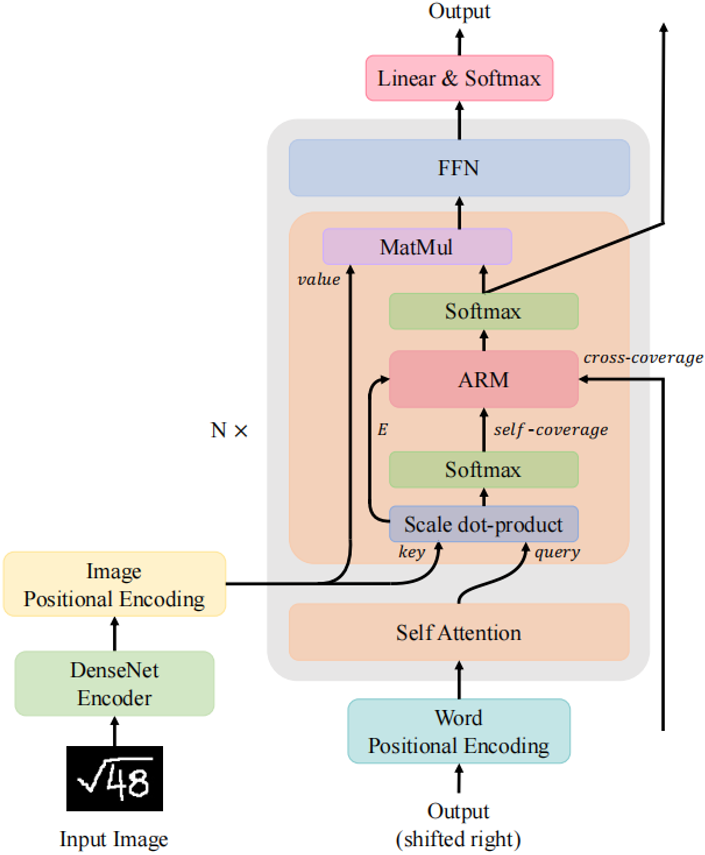
图1 本文提出的具有注意力精炼模块的Transformer模型
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢