

论文标题:
Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis
收录会议:
EMNLP 2022
论文链接:
https://arxiv.org/abs/2210.09803
代码链接:
https://github.com/XMUDM/SentiWSP
导读
本文提出了 SentiWSP,一种基于多层级的情感感知预训练模型,能够在多个情感分析下游任务上微调取得竞争性的性能。该模型通过巧妙的设计词级别和句子级别的预训练任务,使得模型可以更好地在两个层级捕捉到句子的情感信息。
当前,预训练模型例如 GPT,BERT,RoBERTa,通过在大规模无标注语料上预训练之后,可以在很多下游任务上微调取得很好的性能,其中也包含典型的文本分类任务,即情感分析任务。
近两年一些在在情感领域做的一些预训练模型的工作能够在情感分析的下游任务上微调取得很好的性能,例如 SentiBERT,SentiLARE,SENTIX 等,往往都是在词级级别构建情感相关的预训练任务,通过在 BERT的MLM(Mask language model)任务中引入情感词,词性,或者词性语法树之类的词级别情感知识。它们通常忽略了对于句子层面的预训练任务的设计。
然而,通过 MLM 任务上的改进在词级别学习文本中的情感信息往往局限于被少量 mask 的词本身,并且因为情感分析正是从整个句子层面考虑的对文本整体情感倾向的分析。因此本文:
- 如何从词级别学习词语中更丰富的情感信息
- 如何从句子级别构造更加有效的预训练任务提升模型对于文本的整体情感信息的捕捉
是主要的挑战。
方法
SentiWSP 分别从词级别和句子级别分别设计了相关的预训练任务来提升模型对于文本情感信息的捕捉,在词级别使用情感词替换检测任务,通过生成器和判别器联合训练,增强判别器对于文本中情感信息的学习。然后,通过设计的对比学习框架来提升经过词级别训练之后的判别器对于整个句子情感层面的信息捕捉能力。接下来介绍我们设计的预训练任务的细节。
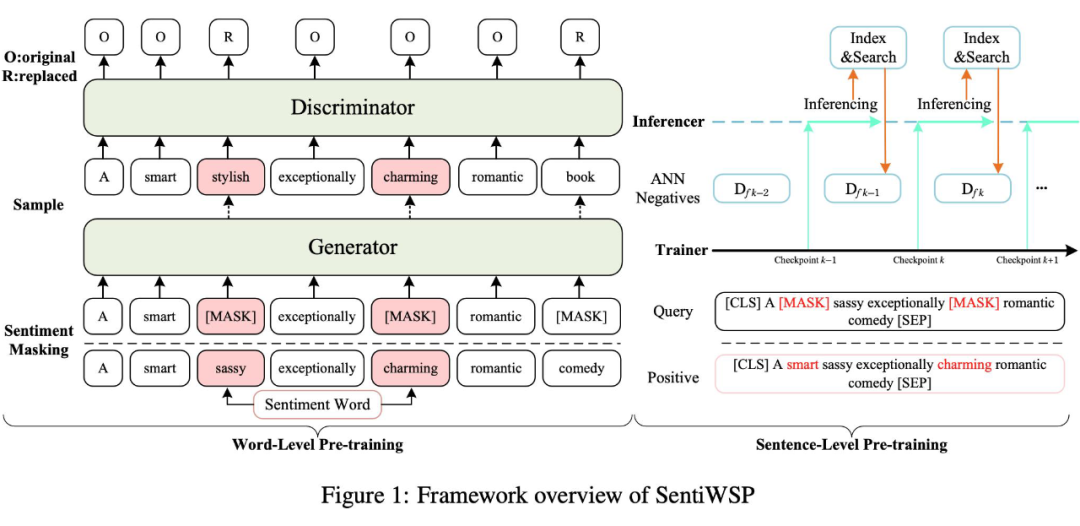
2.1 词级别预训练
对于给定的文本句子,我们首先会使用情感词典对句子中出现的情感词进行标记,分别对于情感词和全部词做一定的遮盖,对于情感词的遮盖概率是pw,遮盖之后的句子输入到生成器进行替换,替换的过程是我们会在生成器对遮盖的词生成的概率分布中做采样进行替换,然后将替换之后的句子输入到判别器做每一个词的判别,判别是否被替换。
例如图 1 当中的左边,我们对句子中的情感词 “sassy”,“charming” 以及普通词 “comedy” 进行了遮盖,然后这些词被生成器进行了替换,替换之后的句子输入到判别器进行每个位置的判别,判别是否被替换。
这个过程中生成器和判别器是联合训练的,生成器的 loss 依然是用原句的 MLM loss,用的是被 mask 掉词的句子smark 的每个遮盖掉词位置的表示即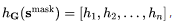 ,以及词的原始嵌入e来计算恢复原有的词的 loss:
,以及词的原始嵌入e来计算恢复原有的词的 loss:
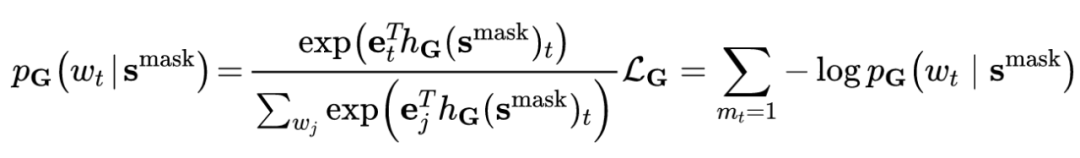
我们对生成的概率分布pG进行随机采样之后的词来对被遮盖的词进行替换,被替换之后的句子srep通过和原句对比即可得到每个词位置是否被替换的标签,我们通过用这个是否被替换的 0-1 标签来监督训练判别器:
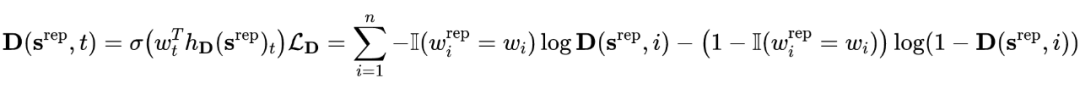 最终,词级别预训练的 loss 是两者相加:
最终,词级别预训练的 loss 是两者相加:
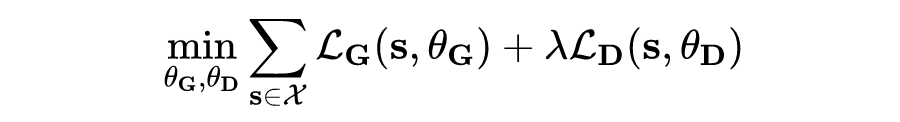
在这个过程中,随着生成器越来越强,替换的词对于判别器而言会形成越来越难的挑战,因此也会让判别器学的越来越好。
2.2 句子级别预训练
经过词级别的训练之后,我们要对判别器进行进一步的句子级别的预训练,我们首先对文本句子当中的情感词进行ps概率的遮盖构造成查询,正例是原句,如图1的右边部分,也可以看到我们构造的 query 和 postive。
我们首先对模型进行使用 in-batch warm-up 的对比学习,使得模型具备简单的从句子层面学习的能力:
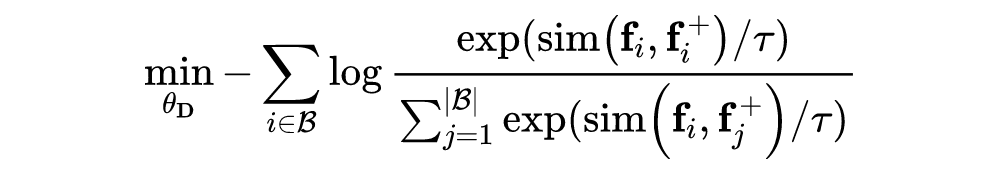
即对于当前的查询fi的正例是fi+,而同一个 batch 的其余样本是负例。
因为 in-batch 内的样本对于模型来说已经形成不了更多的考验,因此我们设计了一个基于 ANN 检索的难负样本挖掘,在 cross-batch 中选择更具有难度的难负样本来对模型进行进一步的学习。
如图 1 右边部分右上角所示,我们使用异步刷新机制的难负样本挖掘,首先使用 warm-up 之后的模型作为 checkpoint 0 模型,并之后通过使用上一个 checkpoint 模型对当前的文档库进行推理,并构建索引,使用 ANN 向量检索出每一个查询的 top n 个最近邻的句子,然后从中采样 k 个句子作为当前 query 的难负样本,即不断的更新难负样本来训练当前的 checkpoint 模型,依次迭代。
随着模型的逐渐学习,我们会更新当前所有 query 的难负样本,然后训练下一个 checkpoint 模型,以此迭代,这一部分的优化目标是将正例拉近,负例拉远:
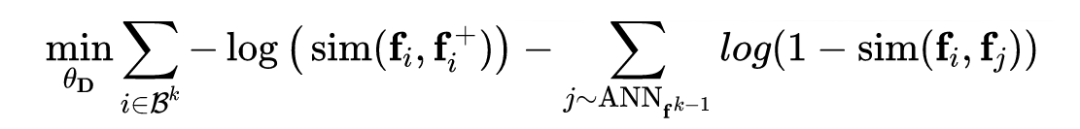
实验
我们通过在 wikipedia 的语料上预训练我们的模型,我们加载 ELECTRA 的模型作为我们的初始参数。然后我们在一些下游任务上面微调验证我们模型对于情感分析任务的有效性。
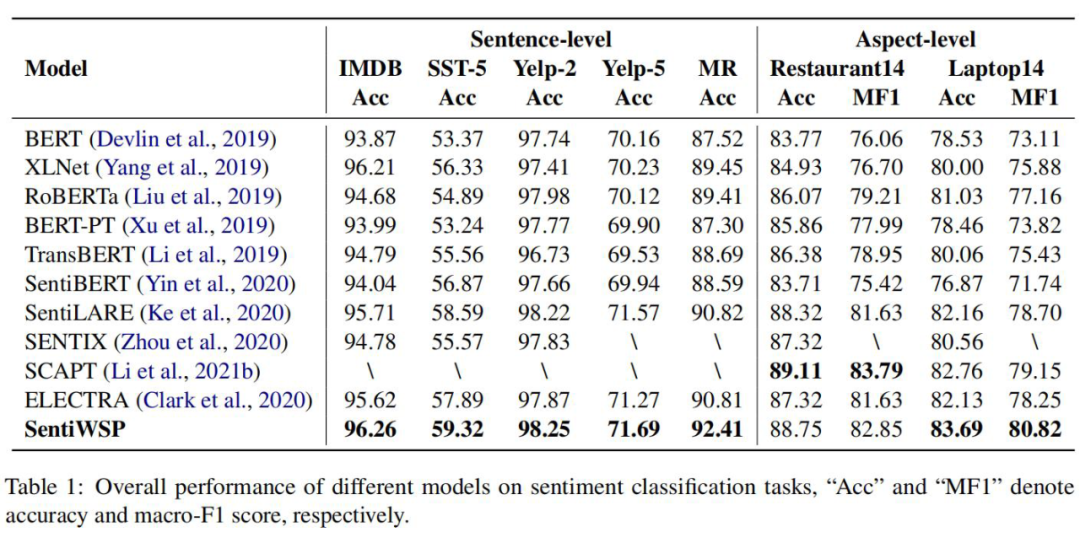
主实验部分,我们对经过我们预训练之后的模型在 5 个最常用的开源句子级别情感分类的数据集 SST,IMDB,MR,Yelp-2/5 和方面级情感分类 Semeval2014 数据集两个子集 Resaurant 14 和 Laptop14 上面做微调进行实验:
对比基线得到的效果如下:
- 对比近两年的一些情感领域的预训练工作以及通用的预训练模型的效果,我们的模型在句子级别数据集上面都有着最好的性能。
- 在方面级情感分析的数据集上,我们的总体效果达到了最优,在其中一个子集即 Restaurant14 上略逊于 SCAPT 这篇专门针对方面级情感分析所做的工作。
对于 ELECTRA,我们在所有数据集上都有着效果上的提升,这证明了我们预训练任务的有效性。
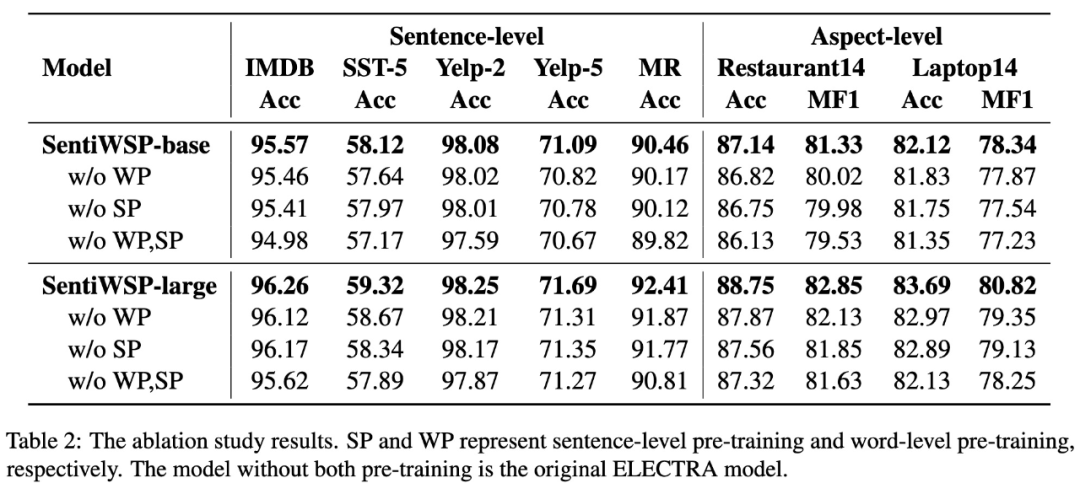
对于我们提出的两个预训练任务,我们进行了消融实验分析。发现我们提出的预训练任务在不同规模的模型上都有着很好的性能。base 版本是 12 层 768 隐层而 large 是 24 层 1024 隐藏层大小的模型。
从消融实验表 2 的结果我们发现:
- 使用词级别和句子级别的预训练任务之后模型在所有情感分类下游任务上都得到了提升,对与不同大小的模型而言结论相同
- 词级别和句子级别的预训练任务都很重要,并且在不同的数据集上面表现并不相同。
- 使用我们的预训练任务训练的 base 版本的模型甚至优于一些通用预训练模型的 large 版本,例如 BERT,RoBERTa。
同时我们也做了一些相关的参数实验验证不同实验设置下我们提出的预训练任务的有效性。
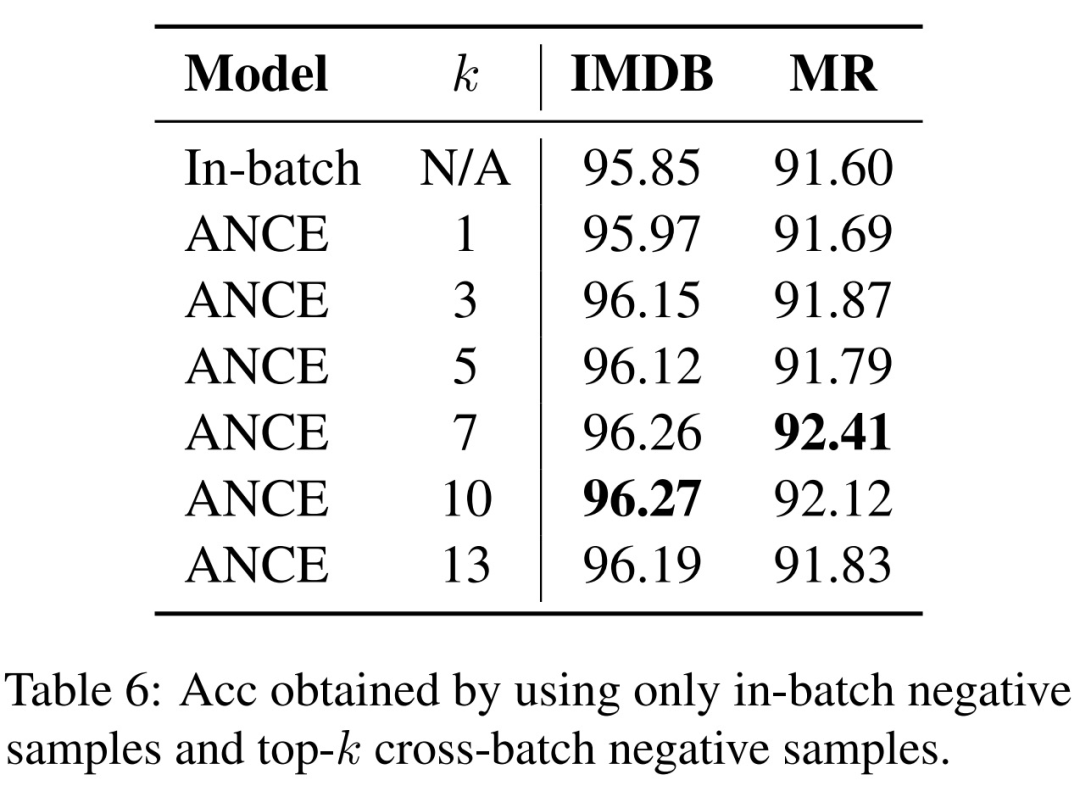
我们在 IMDB 和 MR 上验证了我们提出的 cross-batch 难负样本的效果,对比仅仅使用 in-batch 内负样本训练同样步数的模型,我们增加的难负样本可以带来更好的效果,并且随着难负样本选择数量的增加,效果逐渐上升,后续下降的潜在原因是难负样本个数过多会使模型面临的挑战过难。
在论文中我们还分别验证了情感词遮盖的比例在词级别预训练和句子级别预训练任务中的一些性能,具体细节可以参考我们的论文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢