
多模态机器学习日前正越来越受研究者们的关注,21年,“Learning Transferable Visual Models From Natural Language Supervision”论文中提出的CLIP模型拥有强大的特征抽取能力,为后续的很多科研工作都提供了启发。时至今日,无论是传统的视觉任务,还是新颖的AI绘画,我们都能看到CLIP模型的身影。那么,本期就和译者一起来看一篇“CLIP from OpenAI: what is it and how you can try it out yourself”的博客,学习一下CLIP模型的基础原理和使用方法,相信一定也会为你带来灵感!
02 作者介绍
相信很多初次接触一个陌生领域的同学一定有过和我一样的困惑:“缺乏领域基础知识背景,导致论文读起来晦涩难懂”,“学习了模型理论后,不知去哪里寻找相关代码进行实践,加强认识”。译者考虑到本文读者更多的是NLP技术背景的学者和工程师,所以没有死板地逐字翻译。在文章的翻译过程中,译者添加了很多图像领域的基础知识,并对一些专业术语做了更通俗、详尽的解释。在文章的最后,博客作者分享了使用CLIP模型的简单代码,译者也验证了代码的有效性。如果读者们对CLIP模型感兴趣的话,在阅读完本文后不妨实践一下。
04 原博客译文
最近,Open AI提出了一个名为CLIP (opens new window)的模型并声称该模型可以大大缩小上述的这种差距。在Open AI撰写的论文中,讲述了该模型是如何以zero-shot(无样本学习,举个简单例子:这种学习希望模型在食物图像数据上进行学习,然后在卫星图像数据上依然有好的表现)的方式应用于各种类别的数据集。
本文,我将为大家解释CLIP模型取得如此突破的关键思想,并向您展示使用该模型的代码。
当训练一个传统的图像分类模型时,我们所使用的数据集是一堆已被标注具体类别的图像。在这样的一个数据集中,类别的数量是固定的,类别的内容也是不可改变的。例如,你训练了一个神经模型来区分猫和狗,那么你就不能使用该模型来区分猫和熊,也不能使用该模型来区分猫、狗、熊。如果你想赋予模型能识别新类别“熊”的能力,那么你必须在数据集中添加足够量的标注为熊的图像,并重新训练神经网络模型!
然而,如果有一个模型,它可以将图像和任意的文本联系起来,那么你只需要简单地提供包含新类别的文本描述就可以使用该模型来识别新类别。简单来说,如果模型预测出图像和包含新类别的文本描述关联程度很高,就说明该图像是新类别;而如果关联程度很低,就说明该图像不是新类别。那么为了成功实现这样的模型,神经网络模型必须有学习出良好视觉表示以及有效建模图文匹配程度的能力。
首先,让我们考虑一下我们的问题范围。为了将图像和文本联系起来,我们需要一个图像-文本对数据集。CLIP的作者们在论文中提到,他们从互联网上收集了4亿条图文对数据集。按照过去的方法为了实现图像分类,模型应该将图像作为输入,并预测文本(类别)作为输出。

如下图所示,对于预测出来的文本有多种不同的表示方法:
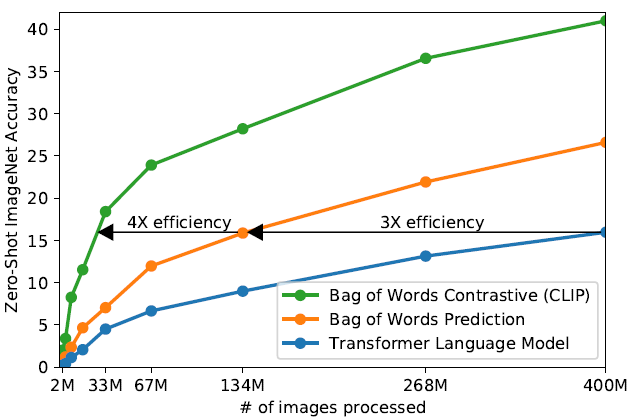
第一种是用正确的语序来预测文本,即分类器必须输出this is a photo of a cat这样的句子。第二种是根据词典来预测文本,即不考虑单词的顺序,那么如果分类器预测的结果为photo或者cat,它们都是正确的。Open AI在词典方法上做了改进,并且结果显示在ImageNet数据集的准确率结果上,CLIP以zero-shot的方式仅需1/4的数据就可以达到与以前的方法相媲美的性能。
CLIP对问题进行了重新的定义并使用对比预训练的方式,不再预测文本标签,取而代之的是预测图像与文本相匹配的可能性大小。
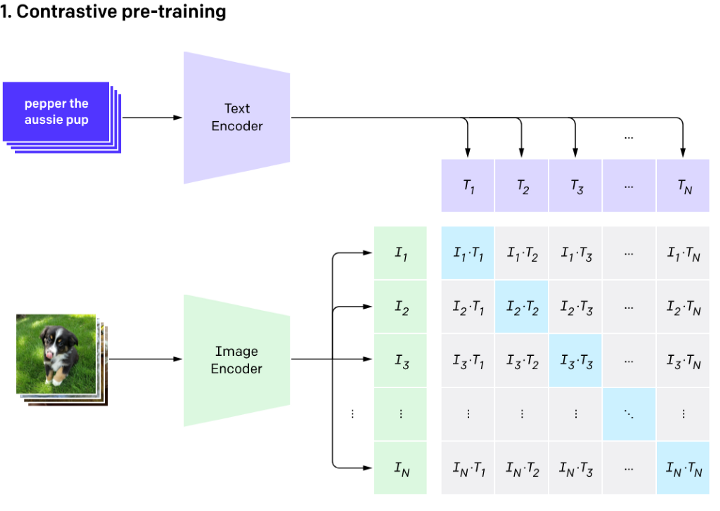
以一个batch size为N的输入为例,首先,N张图像和N个文本分别被各自模态的Encoder编码成高维向量。然后,用它们的向量表示建立一个相似度矩阵(图中,I*T表示两模态向量的内积)。值得注意的是,在训练过程中,矩阵对角线上的内积是匹配图文的内积(即当前batch内,文本T1和图像I1是匹配的图文对,而文本T1和图像I2是不匹配的图文对)。我们知道内积越大,相似度越高,因此匹配的图文对的相似度(内积)必须高于同一行/列中其他图文对的相似度(内积)才合理。于是,训练的目标可以看作是在进行对比,对比的目的是使同一行/列中匹配图文的内积尽可能大,不匹配图文的内积尽可能小。我们也可以用更通俗的方式来理解:每一行都是一个分类任务,给定一个输入图像I,预测匹配的那个文本是谁。同理,每一列都是一个分类任务:给定输入文本T,预测匹配的那张图像是谁。在训练期间,Open AI使用了非常大规模的batch size(32768),这可以充分发挥这种对比训练的潜力。
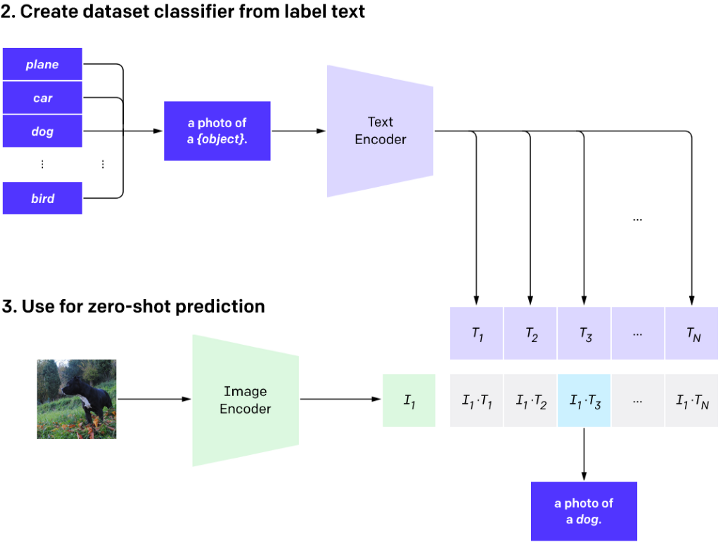
在推理过程中,使用者可以按照prompt(提示词)的格式自定义新文本。将新文本和图像送入CLIP模型后,通过内积值的大小来判断新文本和图像是否是匹配的。如下图所示,提示词是a photo of a {object}.,我们只需要将我们想判断的类别跟{object}进行替换即可。例如,我想判断这个图片是不是狗,我的新文本就是a photo of a dog.。
经典的分类训练只关心模型是否可以正确预测图像的分类标签。如果模型预测成功了狗,那么它不在乎图像是一张狗的照片,还是一张狗的素描。而CLIP模型在大规模数据集上完成的训练,这使得CLIP模型还学习到了图像的各方面信息。
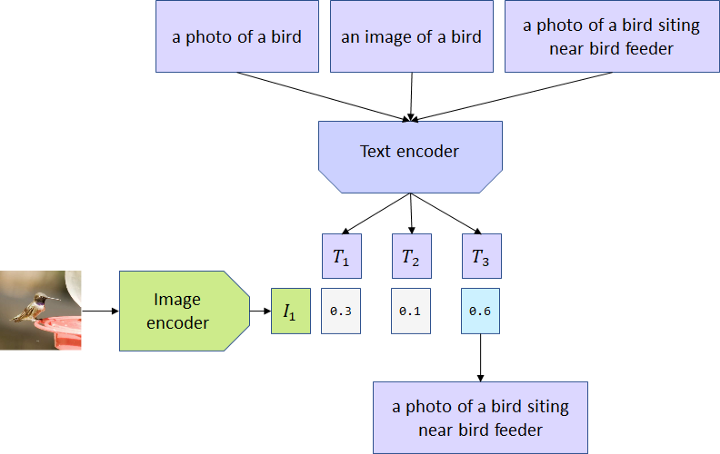
例如,CLIP模型对用于图像描述的单词很敏感。文本“a photo of a bird”、“a photo of a bird siting near bird feeder”或“an image of a bird”与相同的图像匹配产生的概率是不同的。
为了说明CLIP模型的潜力,我想展示一个真实的工程项目用例。这是我为客户所做的一个项目,一个图像相似度搜索引擎。在这个项目中,用户向模型提交一个图像,返回一个与所提交图像在视觉上相似的图像集合。在实际的使用过程中,用户提交的图像主要是PDF文档的页面,往往单独或混合包含着文本、表格、嵌入的照片、空页面、模式、图表和技术图纸。而用户想搜索到的图像只能是技术图纸。
以下是几个技术图纸示例:
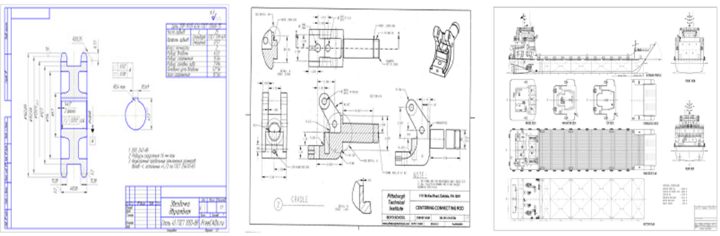
正所谓细节决定成败,在这个实例中,我们观测到每个图像的右下角都包含一个文本信息块。而且,所有来自相同单位的技术图纸都包含一个非常相似的文本块。因此,我们可以基于这个文本块来建模神经网络模型以实现图像搜索引擎。
我们首先使用SimCLR (opens new window)方法对ResNet-18模型进行训练。SimCLR是一种自监督的对比学习方法,可以在没有图像标签的情况下学习到良好的视觉表示。我们可以将视觉表示用于图像相似度判断,如果两个图像的视觉表示相似度高就可以说明这两个图像是相似。在这个项目中,ResNet-18模型在100K张图像上进行了训练。其中50%是技术图纸,剩下50%是其他各种类型的图像。
接下来,我将CLIP模型与SimCLR方法训练的ResNet-18模型进行了对比。我发现,CLIP模型以zero-shot方式得到的图像特征与专门在技术图纸数据上训练的ResNet-18模型得到的图像特征是有可媲美的表现的。考虑到技术图纸不是公开可用的数据集,这确实令人惊讶。我甚至无法解释为什么CLIP模型能够在技术图纸上表现得如此出色,难道这些技术图纸是训练数据集的一部分?
同时,这还展示了另一个结果:CLIP模型虽然没有以图像相似性来训练,但是它学习到得图像特征完全可以用于图像相似性匹配场景。
CLIP模型的作者对模型局限性持开放态度。CLIP模型在更抽象或更系统的任务(如计算物体数量)和更复杂的任务(如估计物体之间的相对距离上)都很吃力。在这样的数据集上,CLIP模型只比随机猜测略胜一筹。CLIP模型也在非常细粒度的分类任务上表现不佳,比如区分汽车型号、飞行器种类、花卉种类。
CLIP模型还存在着非常依赖训练数据量,训练成本昂贵的问题。如果预训练的CLIP模型对您所要解决的任务不起作用,那么训练您自己的CLIP模型几乎是不可行的。
虽然CLIP模型有非常好的泛化性能,可以很好地推广到许多图像分布上,但它仍然不能推广到真正的非分布数据。例如,CLIP模型以zero-shot的方式在MNIST数据集上的准确率为88%,一个简单的Logistic回归方法就可以优于CLIP模型。
最后,CLIP模型的分类器可能对文本描述中的措辞很敏感,这需要使用者反复试验,确定具体任务下表现良好的文本描述。
CLIP模型的训练方式打破了传统分类器的界限,并且预训练的CLIP模型可以在不需要额外训练集的情况下,以良好的性能完成各种计算机视觉任务(如分类、图像特征利用)。正如我在上述真实项目示例中所展示的,预训练的CLIP模型可以无需额外训练,可以快速帮助我们搭建项目。这个开发在数据科学工具中会非常受欢迎。
如果您觉得CLIP模型很有趣,我强烈建议您阅读原始论文,其中作者进行了许多不同的实验,并展示了CLIP模型如何在广泛的数据集上执行zero-shot分类。
我准备了一个Colab笔记本 (opens new window),展示了如何使用CLIP。在那里,你不仅会发现基本的程序代码,还会发现一些关于文本描述如何影响结果的见解。请一定要去看看!
这篇笔记本用了3个人的16张肖像照片来测试看看CLIP模型能不能区分这些人。当然,CLIP模型有这个能力!但是,正如CLIP模型的作者们在他们的论文 (opens new window)中指出的那样,在当前的开发状态下,CLIP模型可能不是执行此类任务的最佳候选,但它是查看模型如何工作,扩展思路的好选择。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢