
作者:Yihan Wang, Si Si, Daliang Li, 等
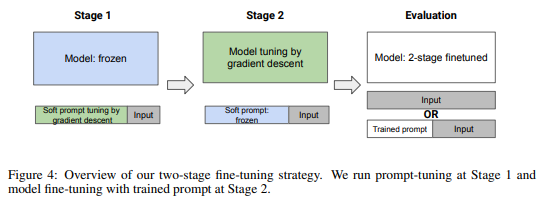
简介:本文研究利用Prompt技术保留预训练模型的上下文能力。预训练的大型语言模型 (LLM) 是强大的上下文学习器,能够在不更改模型参数的情况下执行少量学习。然而,正如本文所展示的,在任何特定任务上微调 LLM 通常会破坏其上下文能力。作者发现了这种损失的一个重要原因:格式专业化,其中模型过度拟合微调任务的格式并且无法输出超出该格式的任何内容。作者进一步表明,格式专业化发生在微调的开始。为了解决这个问题,作者提出了使用模型调整(ProMoT)进行提示调整,这是一个简单而有效的两阶段微调框架,可以保留预训练模型的上下文能力。ProMoT 首先为微调目标任务训练一个软提示,然后在附加此软提示的情况下对模型本身进行微调。ProMoT 将特定于任务的格式卸载到软提示中,在执行其他上下文任务时可以将其删除。作者使用 ProMoT 在自然语言推理 (NLI) 和英法翻译方面对 mT5 XXL 进行微调,并评估生成的模型在 8 种不同 NLP 任务上的上下文能力。与普通微调相比,ProMoT 在微调任务上实现了相似的性能,但对上下文学习性能的全面降低要少得多。更重要的是,ProMoT 在具有不同格式的任务上表现出显着的泛化能力,例如对 NLI 二进制分类任务的微调提高了模型在上下文中进行总结的能力(与预训练模型相比,Rouge-2 得分为 +0.53),使 ProMoT 成为一种很有前途的方法,可以将基础和推理等通用功能构建到具有小而高质量数据集的 LLM 中。当扩展到顺序或多任务训练时,ProMoT 可以实现更好的域外泛化性能。
论文下载:https://arxiv.org/pdf/2211.00635.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢