


本文简要介绍ACM MM 2022录用论文“Decoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter”的主要工作。该工作对于文本端到端检测和识别问题,提出了SRSTS方法,该方法创新性地提出基于采样的识别策略,利用采样点的特征进行识别任务,避免了传统端到端方法使用检测框提取特征的操作。因而检测和识别可以完全解耦。该方法的优势在于:(1)削弱了文本检测和识别的关联性,避免了从检测到识别的误差传递。(2)基于采样的识别策略使得即使在检测不准确时,识别模块仍然有能力输出正确结果。
一、背景
场景文本的端到端检测识别任务旨在定位及识别自然场景图片中的文本实例。由于自然场景中的文本形状、字体及风格迥异,该任务仍然充满挑战性。目前的端到端方法大体上可以分为:双阶段方法以及单阶段方法。双阶段方法常常先做文本定位,利用文本框裁剪出文本实例的局部特征,最后利用局部特征进行识别。这种方法具有两个局限:(1)文本识别的表现高度依赖于识别的精度,会造成从检测到识别的误差传递;(2)特征裁剪操作可能会带来背景噪音的干扰,以及由池化或插值操作带来的信息损失。现有的单阶段方法较少,且均有一定的局限性,如:需要字符级的标注、推理时间长以及性能不理想等。
针对上述的问题,本文提出了一个仅需要单词级别标注的单阶段端到端方法,将检测和识别进行解耦,从而可以并行地进行文本检测和文本识别,并借助于锚点将检测与识别结果相关联。实验证明该方法在ICDAR 2015和Total-Text数据集上均可以达到State-of-the-art的端到端识别效果。受益于并行的框架设计,该方法在时效性上也明显优于其他方法。
二、方法简述
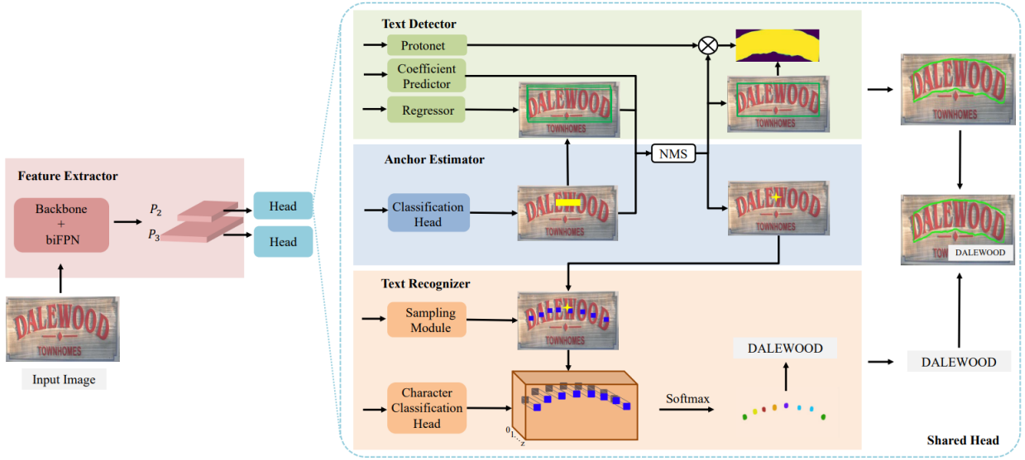 图1 SRSTS的模型框架图
图1 SRSTS的模型框架图SRSTS的模型整体框如图所示,包括四个部分:特征提取器、锚(Anchor )估计器、文本检测器以及文本识别器。
特征提取器:SRSTS的特征提取器借鉴了BiFPN[1]的框架,ResNet 50作为下采样路径,产生多尺度的特征图,上采样路径则将不同尺寸的特征图进行融合,最终输出尺寸为原始输入图像的1/4×1/4以及1/8×1/8两个尺寸的特征图。
锚估计器:本部分用于预测每个潜在文本实例的正锚点(Positive Anchor Points),在后处理时,正锚点将作为文本检测和文本识别的参考位置。锚估计器会产生置信度图,该图上每个像素点的值即为该点作为正锚点的概率。为了提高定位的准确度,文本实例按照尺寸大小分配到不同尺寸的置信度图上,由于文本实例的高度通常决定了文本包含的字符大小,标签分配参考的是文本的高度。
文本检测器:当提供了锚定位点后,文本检测器便可输出文本实例的多边形外包。这里的文本检测器采用实例分割方法YOLACT[2],该方法对于每个锚点会输出其对应文本实例的水平框、以及实例分割所需的Prototype和相应的系数,最后在正锚点的指导下,在文本水平框内将Prototype和系数线性组合便能够得到具体的文本Mask。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢