

论文链接:
https://arxiv.org/abs/2210.10775
代码链接:
https://github.com/AIR-DISCOVER/TOIST
导读
目前的开集场景理解算法可以有效地对名词指称的对象进行目标检测或实例分割,但如何理解动词指称仍是一片蓝海。因此,本文研究了面向特定任务的目标检测及实例分割问题,旨在从一幅图片中找出最适用于某一以动词描述的动作任务的物体。比如,您告诉机器人去寻找一个可以“用来挖洞”的东西,此算法就能帮您挑选一个最合适的。
为了解决这个问题,本文提出了TOIST,利用注意力机制自然地对多个可选物体之间的偏好关系进行建模,并提出了一种全新的名词-代词蒸馏框架。现在有很多成功的大规模视觉-语言预训练模型,但是他们只关注名词。本方法将名词指称模型中的知识蒸馏到代词媒介上,从而取得更好的动词理解效果。
贡献
基于大规模视觉-语言预训练模型[1-3],名词指称理解模型取得了巨大的进步。如图1左上角所示,这些算法以名词作为输入,生成目标框或实例掩码。然而,在智能服务机器人等现实应用程序中,系统输入通常以动词短语的形式出现,现代视觉-语言模型能否有效理解动词指称仍未被探索。
为此,我们关注面向任务的检测问题。如图1右上角所示,算法框出桌上的餐叉,因为它们适合用来涂抹黄油的任务。为了提供更精细的定位,我们进一步将问题拓展到实例分割(图1底部),以服务于下游机器人交互应用。
名词指称理解数据集旨在减少歧义[4],而面向任务的检测或分割的一个有趣而具有挑战性的特点是我们必须面对甚至利用这种歧义。如图1底部所示,当我们想要站在某个物体上时,椅子是更好的选择,因为沙发比较软,桌子比较重因而难以移动。而当需要舒适地坐着时,沙发显然是最好的选择。总之,能够满足动词要求的物体是不确定的,算法需要建模物体间的偏好关系。
现有方法[5]采用两阶段流程:首先检测出所有物体,而后对物体进行排序。而我们基于Transformer架构提出了TOIST模型,利用注意力机制,在检测物体的同时自然地建模了候选对象之间的相对偏好关系。
由于Transformer需要大量数据训练[6-7],而获取大规模具有偏好关系的动词指称数据比较困难,我们进一步探索了利用名词指称模型中的知识的可能。具体而言,我们提出了从名词到代词的蒸馏框架,利用代词作为媒介,从通过聚类得到的名词特征原型中蒸馏知识,从而提升模型对动词的理解能力。
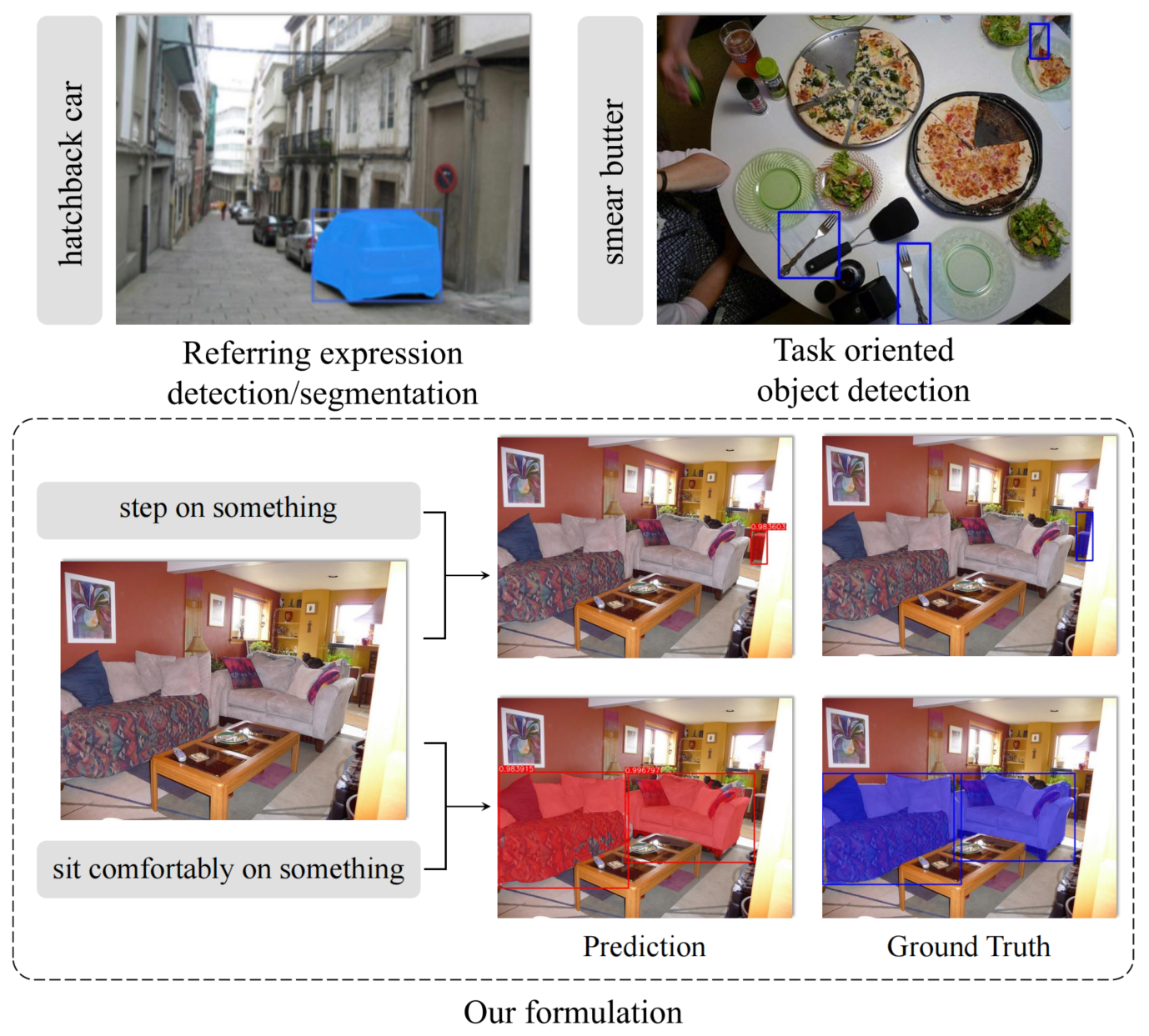
图1:问题形式示意
方法
TOIST模型架构
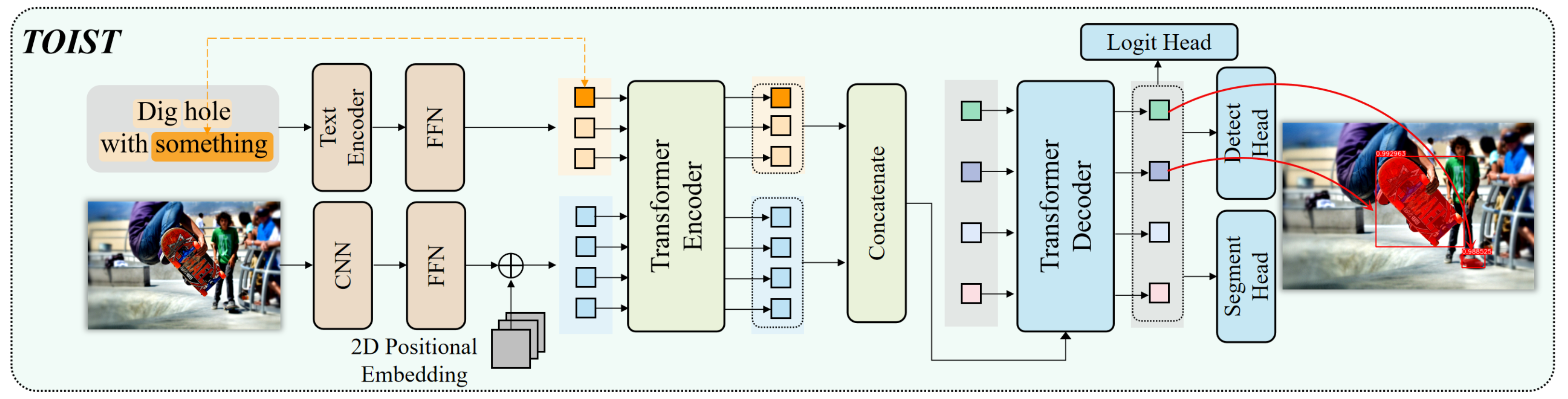
图2:TOIST框架图
所提出的网络总体框架如图2所示。输入为一张彩色图片 \( \mathbf{X}_v \in \mathbb{R}^{3 \times \rm{H_{0}} \times \rm{W_{0}}} \) 和一段文本 \( \mathbf{X}_l \) 。\( \mathbf{X}_l \) 描述了一个特定任务。网络输出为目标框\( \mathbf{B}_{\rm{pred}} = [{\hat b}_{1}, \ldots, {\hat b}_{n_{\rm{pred}}}] \in [0,1]^{n_{\rm{pred}} \times 4} \)、实例掩码 \( \mathbf{M}_{\rm{pred}} = [{\hat m}_{1}, \ldots, {\hat m}_{n_{\rm{pred}}}] \in \mathbb{R}^{n_{\rm{pred}} \times \rm{H_{0}} \times \rm{W_{0}}} \)、偏好程度 \( \mathbf{S}_{\rm{pred}} = [{\hat s}_{1}, \ldots, {\hat s}_{n_{\rm{pred}}}] \in [0,1]^{n_{\rm{pred}}} \)。网络的预测过程刻画了对能够承担特定任务的物体的检测,同时建模了不同物体之间的偏好关系。
对于特定任务如“dig hole”,文本输入\( \mathbf{X}_l \) 可以为动词-名词形式如“dig hole with skateboard”,其中“skateboard”为目标物体的类型,也可以为动词-代词形式如“dig hole with something”。前者在模型推理阶段破坏了目标不可知性,但可用于在所提出的名词-代词蒸馏框架下提升后者。对于单一的TOIST模型,我们采用动词-代词形式的 \( \mathbf{X}_l \)。
如图2底部所示,TOIST包含三个主要模块。多模态编码器(棕色)从图像输入 \( \mathbf{X}_v \) 和文本输入 \( \mathbf{X}_l \) 中提取token特征。Transformer编码器(绿色)聚合两种模态的特征。Transformer解码器(蓝色)预测出最适合给定任务的物体。其中logit head输出 \( n_{\rm{pred}} \) 个物体的logits分布\( \mathbf{G}_{\rm{pred}} = [\hat{\mathbf{g}}_{1}, \ldots, \hat{\mathbf{g}}_{n_{\rm{pred}}}] \in \mathbb{R}^{{n_{\rm{pred}}} \times n_{\rm{max}}} \) , \( {\hat{\mathbf{g}}_{i}} = [\hat g_1^i, \ldots, \hat g_{n_{\rm{max}}}^i] \)。 \( [\hat g_1^i, \ldots, \hat g_{n_l}^i] \)分别对应 nl 个输入的文本token,衡量了物体和各个文本token相匹配的概率。最后一维 \( \hat g_{n_{\rm{max}}}^i \)代表“不是物体”的logit。我们将预测出的每个物体的偏好程度 \( {\hat s}_{i} \) 定义为\( {\hat s}_{i} = 1 - \frac{\exp \left(\hat g_{n_{\rm{max}}}^i\right)}{\sum_{j=1}^{n_{\rm{max}}} \exp \left(\hat g_{j}^i\right)} \)。
训练过程中,我们使用L1、GIoU[8],Dice/F-1[9]、Focal[10],soft-token、contrastive alignment[11]等损失函数来分别监督目标检测、分割、分类(建立物体和词语间的对应关系):
\( \mathcal{L}_{\rm{TOIST}} = \lambda_1 \mathcal{L}_{\rm{l1}} + \lambda_2 \mathcal{L}_{\rm{giou}} + \lambda_3 \mathcal{L}_{\rm{dice}} + \lambda_4 \mathcal{L}_{\rm{cross}} + \lambda_5 \mathcal{L}_{\rm{token}} + \lambda_6 \mathcal{L}_{\rm{align}}. \)
名词-代词蒸馏框架
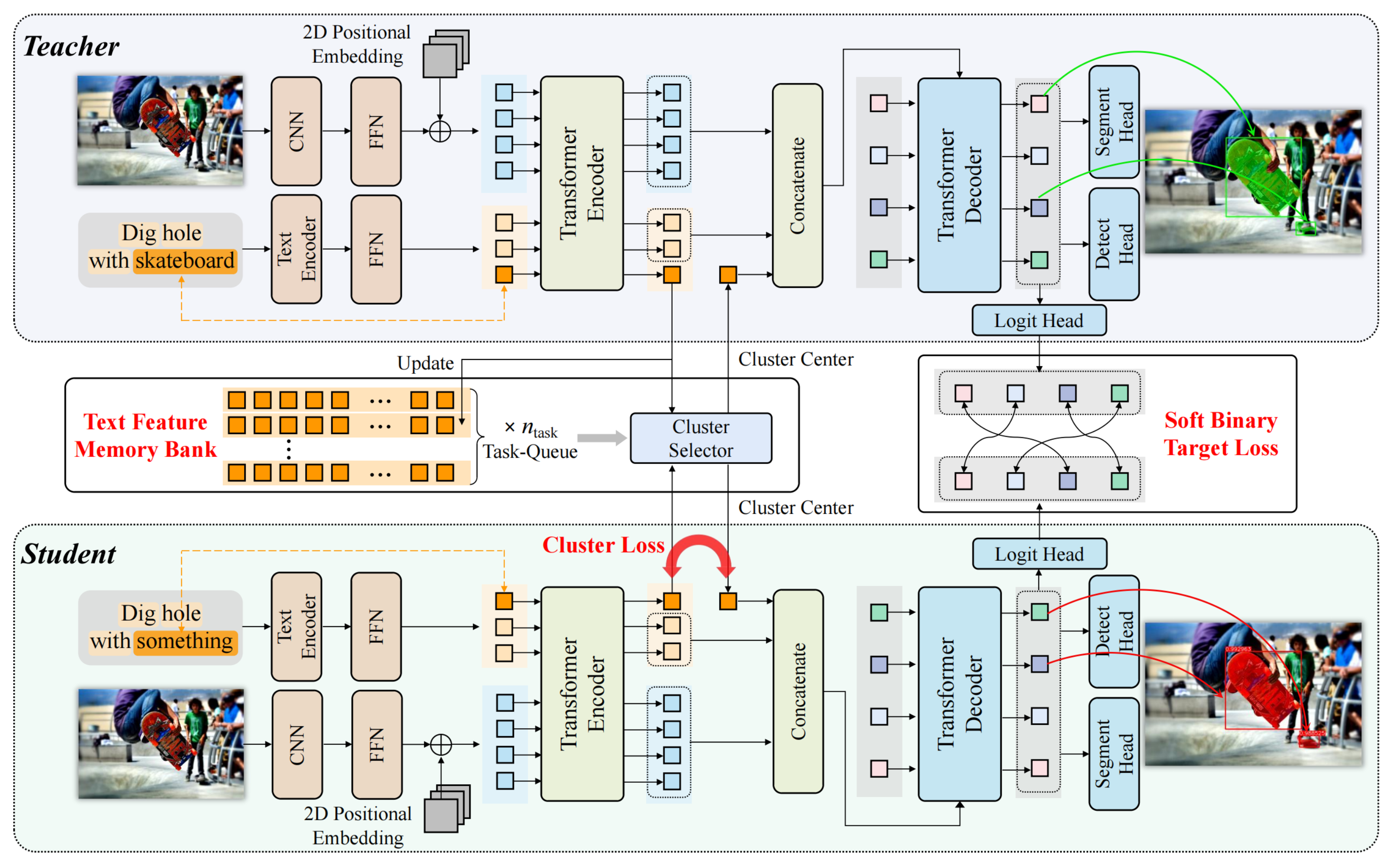
图3:带有名词-代词蒸馏的TOIST的总体框架图
我们同时训练两个TOIST模型,教师模型和学生模型的文本输入分别为动词-名词形式、动词-代词形式。名词-代词蒸馏包括两部分:聚类蒸馏和偏好蒸馏。
聚类蒸馏。我们建立了一个存储名词特征的文本特征库,每个特定任务对应一个队列。在训练过程中,将教师模型处理后的名词对应的特征更新到对应任务的特征队列中。更新后的特征队列通过K-means聚类得到K个聚类中心。而后将学生模型中代词对应的特征\( {l_{\rm{pron}}^{\rm{tr}}} \)替换为该特征距离最近的聚类中心\( {l_{c_s}^{j}} \) 。并使用L2损失拉近两者的距离:
\( \mathcal{L}_{\rm{cluster}} = \| {l_{\rm{pron}}^{\rm{tr}}} - {l_{c_s}^{j}} \|_2. \)
在推理阶段,学生模型直接利用最终的文本特征库生成聚类中心以替换代词特征。
偏好蒸馏。我们对模型预测的候选对象的偏好程度信息进行蒸馏。利用logit head预测的logit值,首先定义候选对象被最终选中与否的概率分布为 \( \mathbf{p} = [p^{\rm{pos}}, p^{\rm{neg}}] \in \mathbb{R}^{1\times2} \) 。其中
\( p^{\rm{pos}}=\frac{\sum_{j=1}^{n_{\rm{max}}-1} \exp \left(\hat g_{j}\right)}{\sum_{j=1}^{n_{\rm{max}}} \exp \left(\hat g_{j}\right)}, p^{\rm{neg}}=\frac{\exp \left(\hat g_{n_{\rm{max}}}\right)}{\sum_{j=1}^{n_{\rm{max}}} \exp \left(\hat g_{j}\right)} \)
对于教师模型和学生模型对同一个样本分别预测的所有对象 \( \mathbf{P}_t = [\mathbf{p}_{t_1}, \ldots, \mathbf{p}_{t_{n_{\rm{pred}}}}] \)和 \( \mathbf{P}_s = [\mathbf{p}_{s_1}, \ldots, \mathbf{p}_{s_{n_{\rm{pred}}}}] \),我们利用匈牙利算法找到一个双边匹配关系 \( \sigma \in \mathfrak{S}_{{n_{\rm{pred}}}} \),使整体相似程度最高。而后利用KL-散度使对应对象间的被选中概率分布趋于一致:
\( \mathcal{L}_{\rm{KL}}(\mathbf{p}_{t_i}, \mathbf{p}_{s_{\sigma(i)}}) =\mathbf{KL}\left(\mathbf{p}_{t_i} \| \mathbf{p}_{s_{\sigma(i)}}\right) = p_{t_i}^{\rm{pos}} \log \left(\frac {p_{t_i}^{\rm{pos}}} {p_{s_{\sigma(i)}}^{\rm{pos}}}\right) + p_{t_i}^{\rm{neg}} \log \left(\frac {p_{t_i}^{\rm{neg}}} {p_{s_{\sigma(i)}}^{\rm{neg}}}\right). \)
\( \mathcal{L}_{\rm{binary}} = \sum_{i}^{{n_{\rm{pred}}}} \mathcal{L}_{\rm{KL}}(\mathbf{p}_{t_i}, \mathbf{p}_{s_{\hat \sigma(i)}}). \)
从而实现对偏好程度的蒸馏。
实验
我们在COCO-Tasks数据集[5]上进行了实验。
结果表明,与现有方法相比,名词-代词蒸馏框架下的TOIST模型取得了SOTA结果,证明了该方法在面向任务的实例分割问题上的有效性。
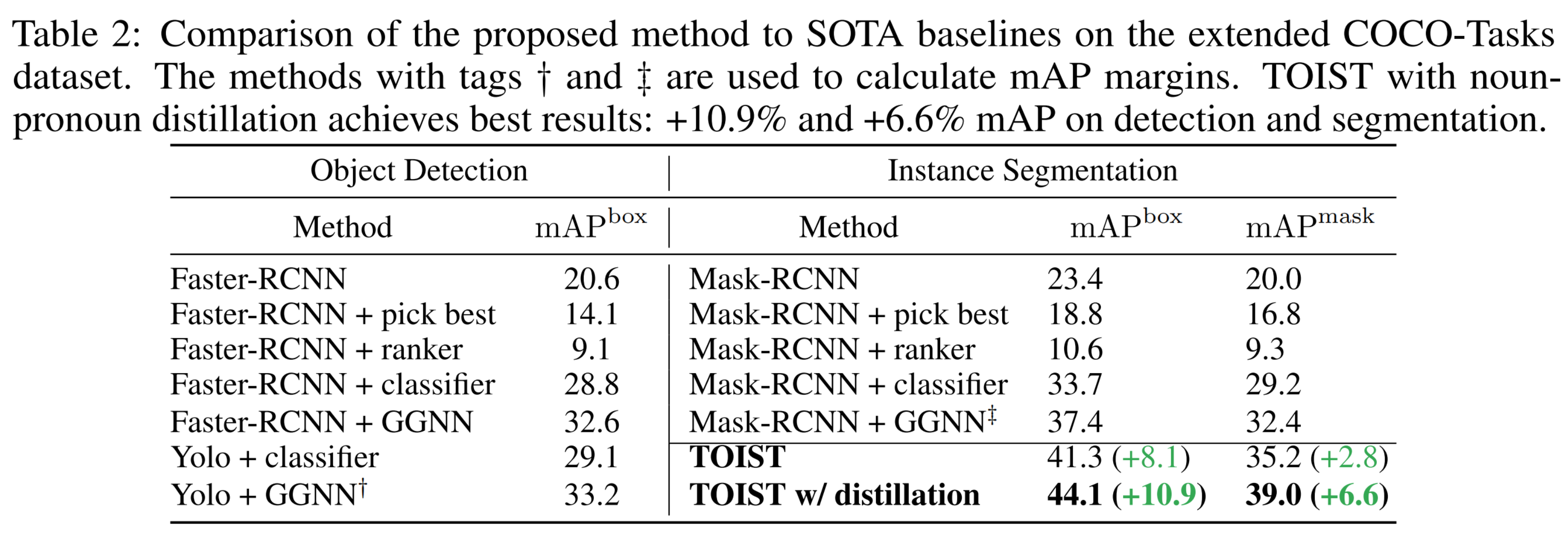
图4:TOIST模型在COCO-Tasks上的可视化结果

从可视化结果(图4)中可以看到,TOIST甚至给出了一些比真实标签更准确的预测。如(b)中,没用物体被标注,但TOIST敏锐地检测到两个水瓶可以完成这项任务;(c)中,TOIST预测出比真实标签更准确的分割结果。
我们进一步从三个方面分析我们的架构设计。
注意力机制。为了证明TOIST中的注意力机制可以自然地建模偏好关系,我们训练了两个TOIST模型,唯一的区别在于其中一个模型在解码器中不包含自注意力层。如图5所示,从解码器各层的预测结果来看,随着解码器层数的增加,目标候选对象之间的偏好关系逐渐通过自注意力提取出来。
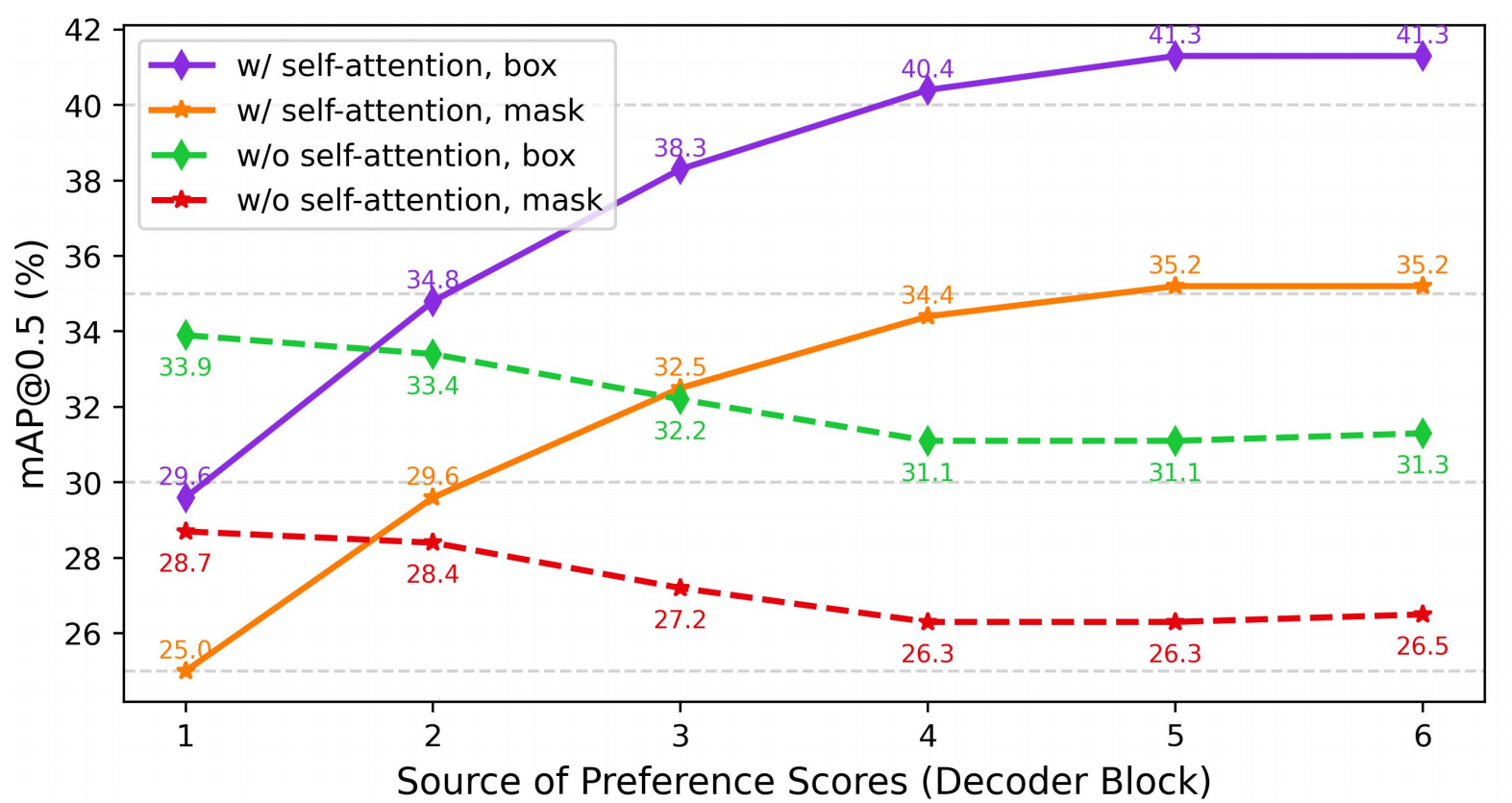
图5:注意力机制的影响
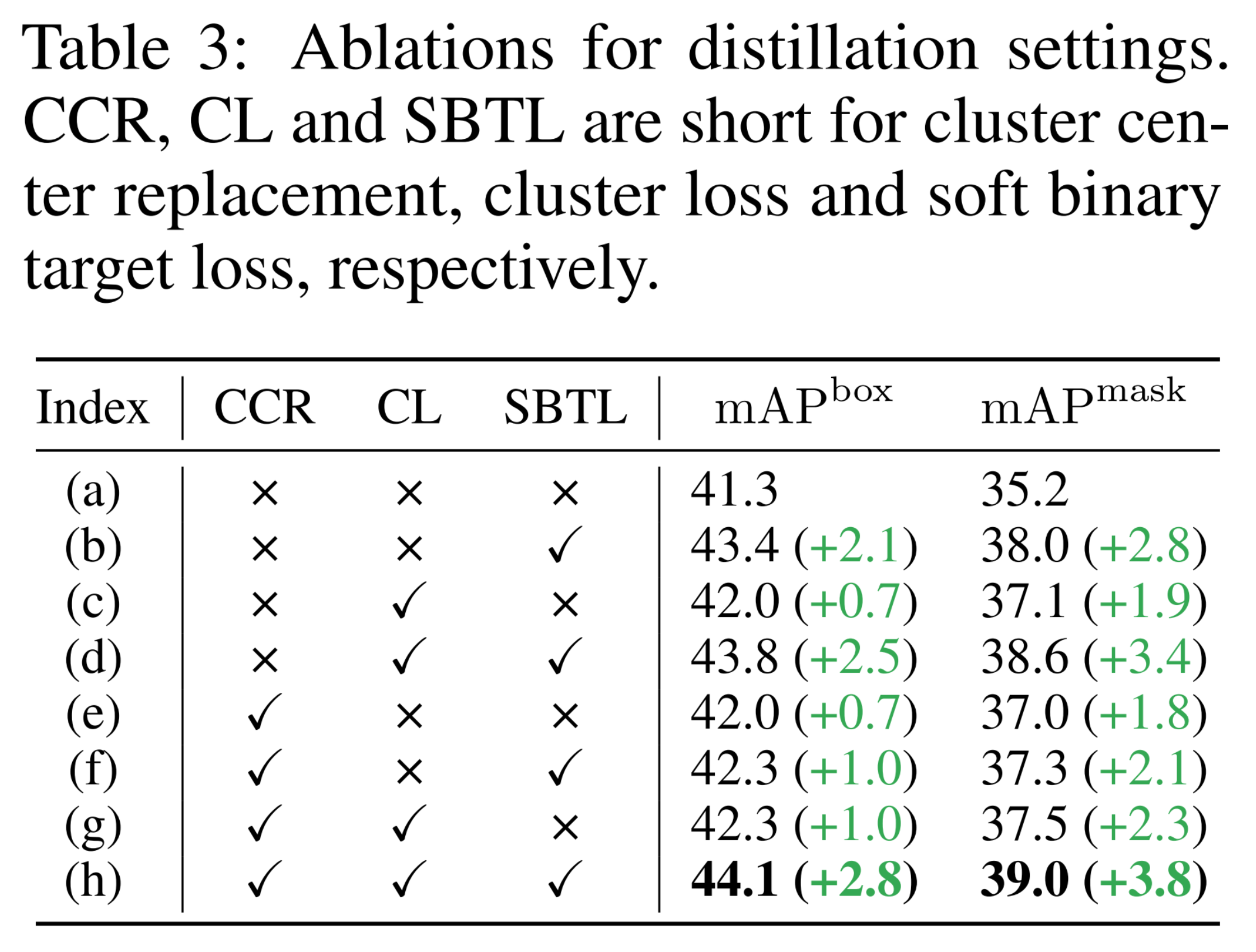
聚类蒸馏。关于蒸馏方法的消融实现表明聚类蒸馏可以提升学生TOIST模型的性能(CCR、CL相关两列)。从图6中,我们还可以看到,它能够使学生模型减少动词-代词指称的歧义(第一行),并能更好地对目标框中的像素进行分割(第二行)。

图6:预测结果和代词的注意力图的可视化
偏好蒸馏。图7展示了偏好蒸馏发挥作用的三种场景。(1)它使假阳性候选对象(棒球)的偏好程度低于筛选阈值(0.9)。(2)将假阴性对象(中间的餐勺)的偏好程度提升到筛选阈值以上。(3)将假阳性对象(餐叉)的偏好程度更新为低于真阳性对象(餐刀)的偏好程度(0.9822 > 0.9808 → 0.9495 < 0.9680)。

图7:偏好蒸馏明显有效的三种情况的例子
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢