
作者:An Yang, Junshu Pan, Junyang Lin,等
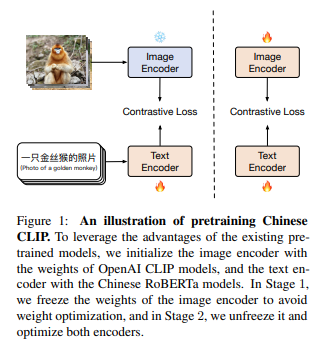
简介:本文研究视频语言预训练对比学习的中文模型与数据集。CLIP(Radford et al., 2021)的巨大成功促进了视觉语言预训练对比学习的研究和应用。然而,虽然公开可用的 CLIP 模型大多是在英文数据上预训练的,但很难搜索在中文数据上预训练的 CLIP。作者认为对中国 CLIP 进行预训练对于研究和工业来说是必不可少的,原因如下:首先,这可以有利于汉语的视觉语言检索,从而促进语言特定的多模态表示学习。其次,中文网站的图片分布要与英文网站的图片分布不同。在这项工作中,作者构建了一个大规模的中文图文对数据集,其中大部分数据是从公开可用的数据集中检索的,作者在新数据集上预训练中文 CLIP 模型。作者开发了 5 个不同大小的中文 CLIP 模型,参数从 77 到 9.58 亿不等。此外,作者提出了一种两阶段预训练方法,其中模型首先在图像编码器冻结的情况下进行训练,然后在优化所有参数的情况下进行训练,以实现增强的模型性能。综合实验表明:中文 CLIP 在 MUGE、Flickr30K-CN 和 COCO-CN 的零样本学习和微调设置中可以达到最先进的性能,并且能够在零样本中实现有竞争力的性能基于 ELEVATER 基准(Li et al., 2022)评估的拍摄图像分类。此外,通过消融研究,作者表明与其他选项相比:两阶段预训练方法是最有效的。
论文下载:https://arxiv.org/pdf/2211.01335.pdf
代码下载:https://github.com/OFA-Sys/Chinese-CLIP
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢