
文章来源:知乎https://zhuanlan.zhihu.com/p/575573336
论文链接:https://arxiv.org/abs/2203.12602
代码链接:https://github.com/MCG-NJU/VideoMAE
本文将介绍我们最近被NeurIPS 2022收录的工作 VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training。这项工作由南京大学媒体计算组和腾讯AI Lab联合完成。
这个工作的主要贡献包含以下三个方面:
-
我们第一个提出了基于ViT的掩码和重建的视频自监督预训练框架VideoMAE。即使在较小规模的视频数据集上进行自监督预训练,VideoMAE仍能取得非常优异的表现。为 了解决由时序冗余性 (temporal redundancy) 和时序相关性(temporal correlation) 导致的“信息泄漏”问题,我们提出了带有极高掩码率的管道式掩码(tube masking with an extremely high ratio)。实验表明,这种设计是VideoMAE 最终能够取得SOTA效果的关键。同时,由于VideoMAE的非对称编码器-解码器架构,大大降低了预训练过程的计算消耗,极大得节省了预训练过程的时间。
-
VideoMAE 将NLP和图像领域中的经验成功在视频理解领域进行了自然但有价值的推广,验证了简单的基于掩码和重建的代理任务可以为视频自监督预训练提供一种简单但又非常有效的解决方案。使用 VideoMAE 进行自监督预训练后的 ViT 模型,在视频理解领域的下游任务(如动作识别,动作检测)上的性能明显优于从头训练(train from scratch)或对比学习方法(contrastive learning) 。
-
实验过程中还有两处有意思的发现,可能被之前NLP和图像理解中的研究工作忽视了:· VideoMAE是一种数据高效的学习器。即使在只有 3 千个左右的视频数据集HMDB51上,VideoMAE也能够完成自监督预训练,并且在下游分类任务上可以取得远超过其他方法的结果。· 对于视频自监督预训练,当预训练数据集与下游任务数据集之间存在明显领域差异(domain gap)的时候,视频数据的质量可能比数量更加重要。
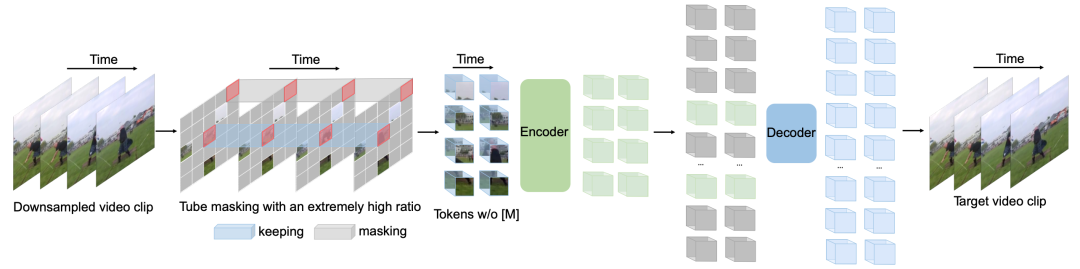
VideoMAE的整体框架
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢