
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:用对抗策略打败专业级围棋AI、面向视觉表表示学习的简单高效可扩展的对比掩码自编码器、基于GPT-2 small间接目标识别回路的现实场景可解释性研究、基于语言模型的原子级蛋白质结构进化规模预测、基于噪声注入的CLIP图像描述纯文本训练、中间模型潜在价值分析、基于自纠正学习的序列生成、一种可解的神经缩放律模型、在大型语言模型微调中保留上下文学习能力
1、[LG] Adversarial Policies Beat Professional-Level Go AIs
T T Wang, A Gleave, N Belrose, T Tseng, J Miller, M D Dennis, Y Duan, V Pogrebniak, S Levine, S Russell
[MIT & UC Berkeley & FAR AI]
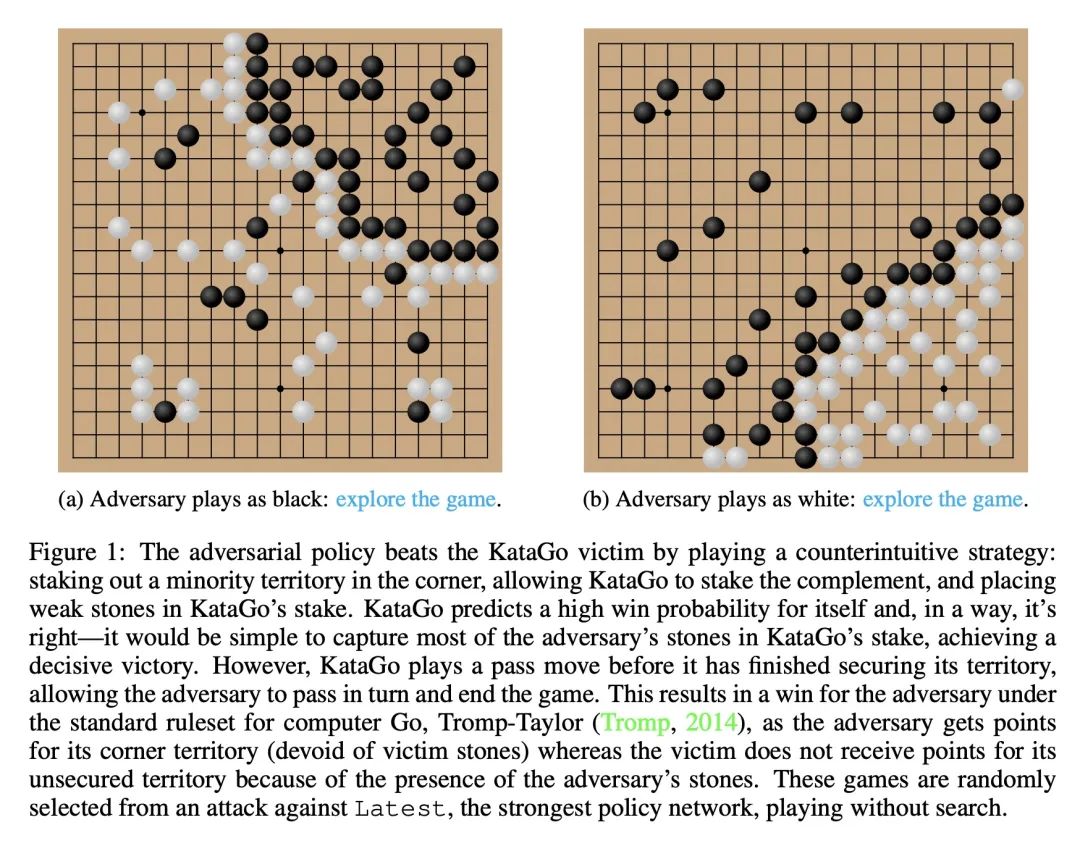
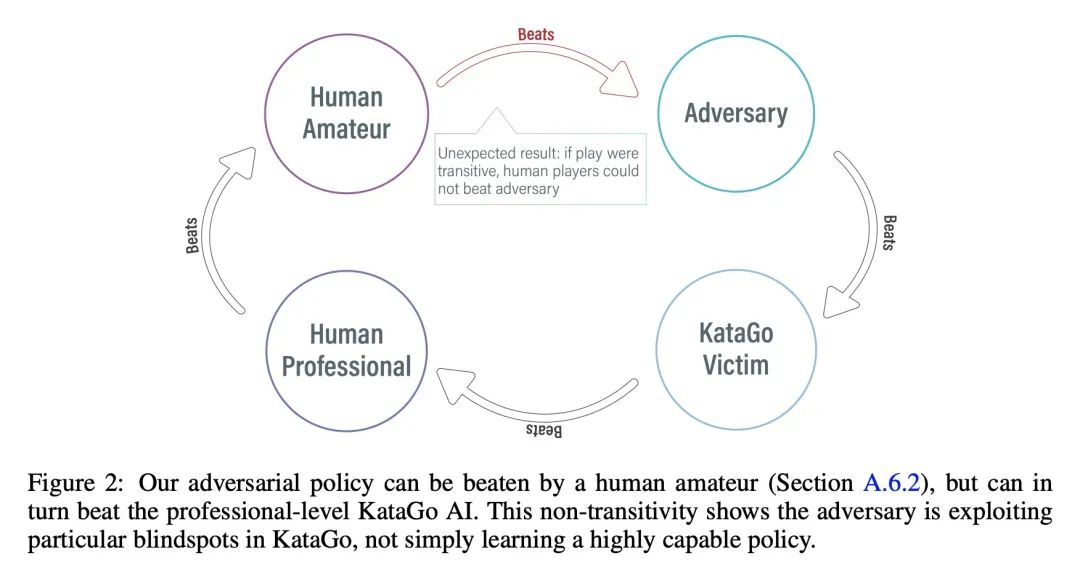
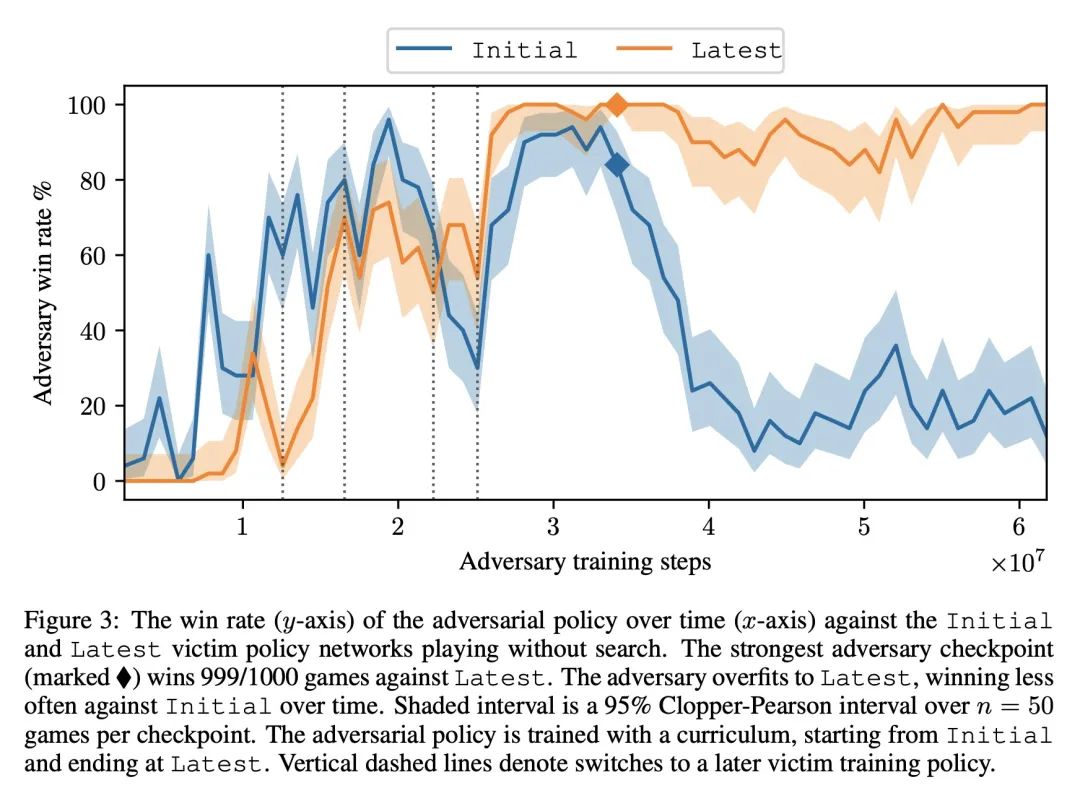
用对抗策略打败专业级围棋AI。本文通过训练一个对抗性策略来挑战最先进的围棋AI系统KataGo,该策略与冻结的KataGo victim对弈。该策略对不使用搜索的KataGo取得了超过99%的胜率,而当KataGo使用足够的搜索达到近超人类时,胜率也超过了50%。据本文所知,这是第一个成功的针对围棋AI的端到端挑战,其水平相当于人类顶尖高手的水平。值得注意的是,对抗器并没有通过学习比KataGo下得更好的围棋而获胜——事实上,对抗器很容易被人类业余爱好者击败。相反,对抗器是通过欺骗KataGo,使其在对对手有利的地方过早地结束对局而获胜的。本文结果表明,即使是专业级的AI系统也可能隐藏着令人惊讶的失败模式。
We attack the state-of-the-art Go-playing AI system, KataGo, by training an adversarial policy that plays against a frozen KataGo victim. Our attack achieves a >99% win-rate against KataGo without search, and a >50% win-rate when KataGo uses enough search to be near-superhuman. To the best of our knowledge, this is the first successful end-to-end attack against a Go AI playing at the level of a top human professional. Notably, the adversary does not win by learning to play Go better than KataGo -- in fact, the adversary is easily beaten by human amateurs. Instead, the adversary wins by tricking KataGo into ending the game prematurely at a point that is favorable to the adversary. Our results demonstrate that even professional-level AI systems may harbor surprising failure modes. See this https URL for example games.
https://arxiv.org/abs/2211.00241

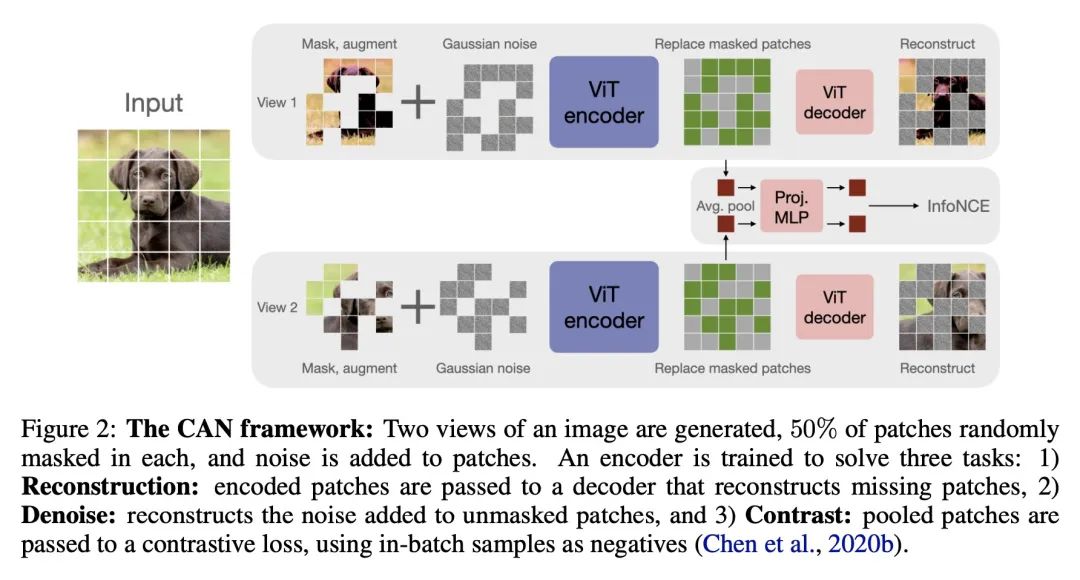
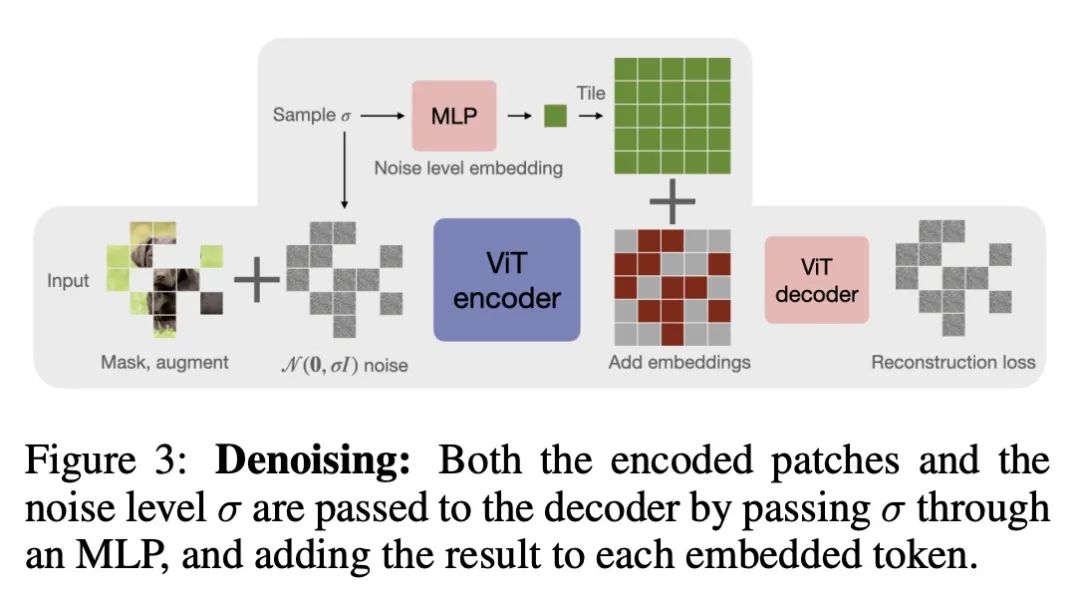
2、[CV] A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
S Mishra, J Robinson, H Chang, D Jacobs, A Sarna...
[University of Maryland & MIT CSAIL & Google Research]
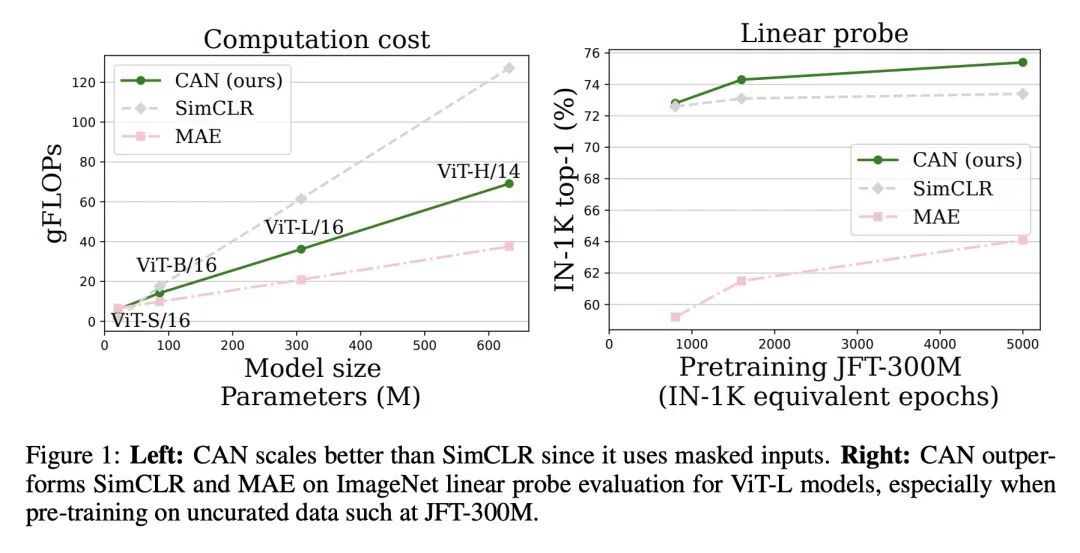
面向视觉表表示学习的简单高效可扩展的对比掩码自编码器。本文提出CAN,一种简单、高效、可扩展的视觉表示自监督学习方法。该框架是(C)对比学习、(A)掩码自编码器和扩散模型中使用的(N)噪声预测方法的最小化的、概念上简单的结合。这些学习机制是互补的:对比学习塑造了一批图像样本的嵌入空间;掩码自编码器侧重于重建单个图像样本的低频空间相关性;而噪声预测鼓励重建图像的高频成分。这种组合方法产生了一种鲁棒的、可扩展的和易于实施的算法。训练过程是对称的,两个视图中50%的图块被随机掩码,与之前的对比学习方法相比,产生了相当大的效率改进。广泛的实证研究表明,在迁移学习和鲁棒性任务上,CAN在线性和微调评估下都取得了强大的下游性能。在ImageNet上进行预训练时,CAN的表现优于MAE和SimCLR,但在JFT-300M等更大的未经整理的数据集上进行预训练时尤其有用:对于ImageNet上的线性探测,CAN达到75.4%,而SimCLR为73.4%,MAE为64.1%。所提出的ViT-L模型在ImageNet上的微调性能为86.1%,而SimCLR为85.5%,MAE为85.4%。SimCLR的整体FLOPs负载比ViT-L模型的CAN高70%。
We introduce CAN, a simple, efficient and scalable method for self-supervised learning of visual representations. Our framework is a minimal and conceptually clean synthesis of (C) contrastive learning, (A) masked autoencoders, and (N) the noise prediction approach used in diffusion models. The learning mechanisms are complementary to one another: contrastive learning shapes the embedding space across a batch of image samples; masked autoencoders focus on reconstruction of the low-frequency spatial correlations in a single image sample; and noise prediction encourages the reconstruction of the high-frequency components of an image. The combined approach results in a robust, scalable and simple-to-implement algorithm. The training process is symmetric, with 50% of patches in both views being masked at random, yielding a considerable efficiency improvement over prior contrastive learning methods. Extensive empirical studies demonstrate that CAN achieves strong downstream performance under both linear and finetuning evaluations on transfer learning and robustness tasks. CAN outperforms MAE and SimCLR when pre-training on ImageNet, but is especially useful for pre-training on larger uncurated datasets such as JFT-300M: for linear probe on ImageNet, CAN achieves 75.4% compared to 73.4% for SimCLR and 64.1% for MAE. The finetuned performance on ImageNet of our ViT-L model is 86.1%, compared to 85.5% for SimCLR, and 85.4% for MAE. The overall FLOPs load of SimCLR is 70% higher than CAN for ViT-L models.
https://arxiv.org/abs/2210.16870

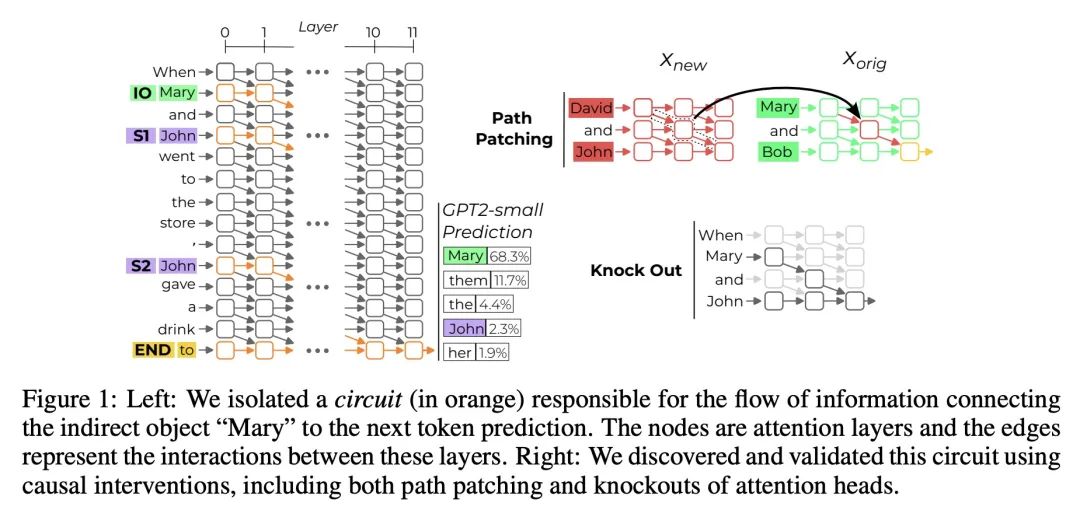
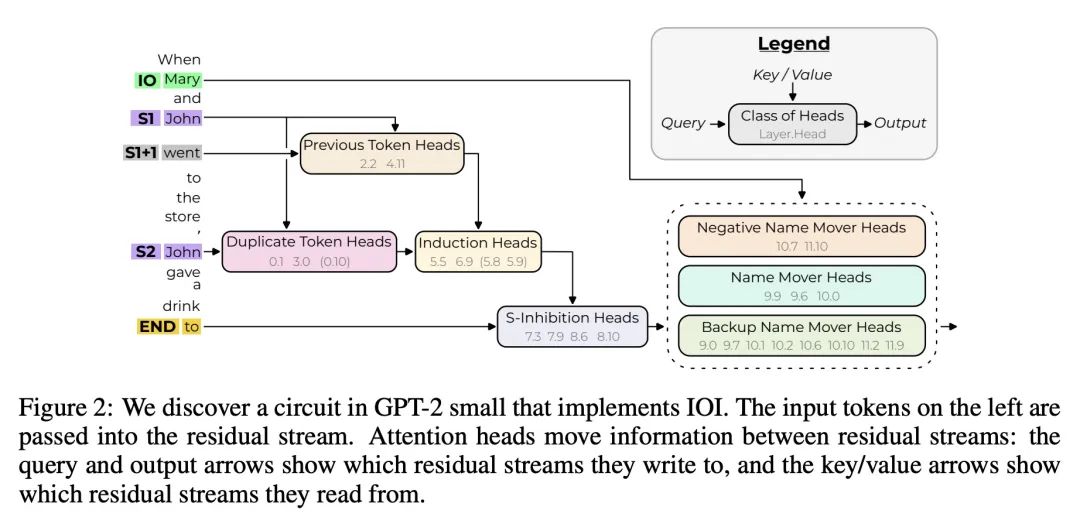
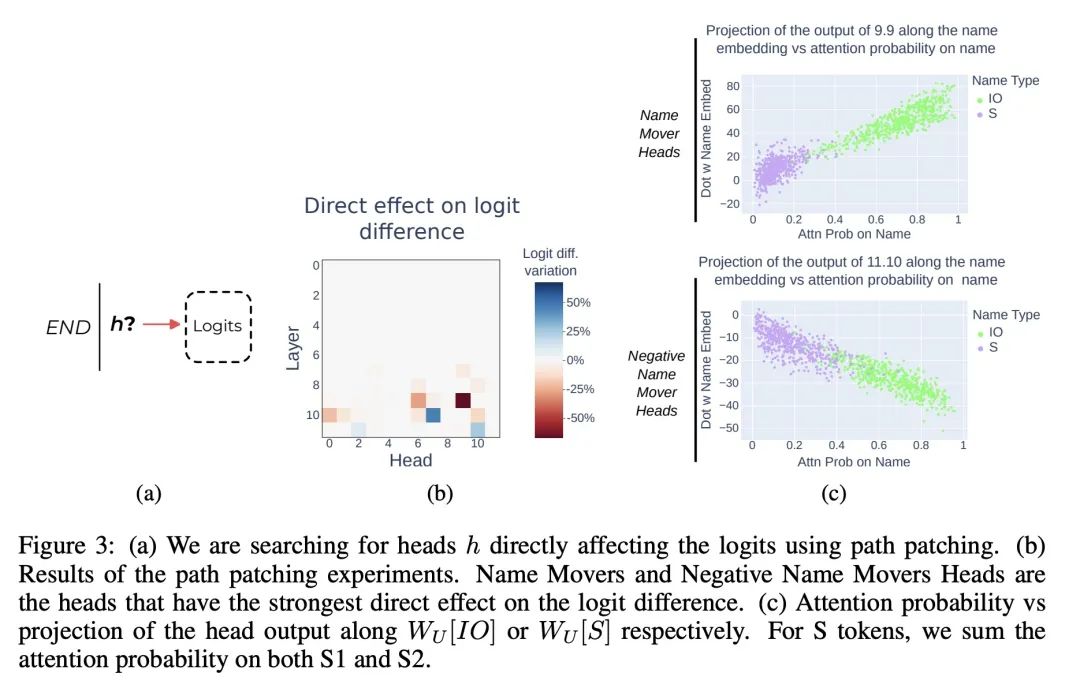
3、[LG] Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
K Wang, A Variengien, A Conmy, B Shlegeris, J Steinhardt
[Redwood Research]
现实场景可解释性:GPT-2 small的间接目标识别回路。机制可解释性研究试图用机器学习模型的内部组件来解释其行为。然而,之前的大多数工作要么集中在小模型的简单行为上,要么以宽泛的笔触描述大模型的复杂行为。本文通过指出GPT-2 small模型如何执行一项名为间接目标识别(IOI)的自然语言任务的解释来弥补这一差距。本文的解释包括26个注意力头,分为7个主要类别,用依靠因果干预的可解释性方法的组合来发现这些头。本项调查是在语言模型"实际场景"对自然行为进行逆向工程的最大的端到端尝试。用三个定量标准来评估该解释的可靠性——忠实性、完整性和极小性。尽管这些标准支持该解释,但也指出了所述理解中的剩余差距。本文工作提供了证据,证明对大型机器学习模型的机制性理解是可行的,为将该理解扩展到更大的模型和更复杂的任务提供了机会。
Research in mechanistic interpretability seeks to explain behaviors of machine learning models in terms of their internal components. However, most previous work either focuses on simple behaviors in small models, or describes complicated behaviors in larger models with broad strokes. In this work, we bridge this gap by presenting an explanation for how GPT-2 small performs a natural language task called indirect object identification (IOI). Our explanation encompasses 26 attention heads grouped into 7 main classes, which we discovered using a combination of interpretability approaches relying on causal interventions. To our knowledge, this investigation is the largest end-to-end attempt at reverse-engineering a natural behavior "in the wild" in a language model. We evaluate the reliability of our explanation using three quantitative criteria--faithfulness, completeness and minimality. Though these criteria support our explanation, they also point to remaining gaps in our understanding. Our work provides evidence that a mechanistic understanding of large ML models is feasible, opening opportunities to scale our understanding to both larger models and more complex tasks.
https://arxiv.org/abs/2211.00593

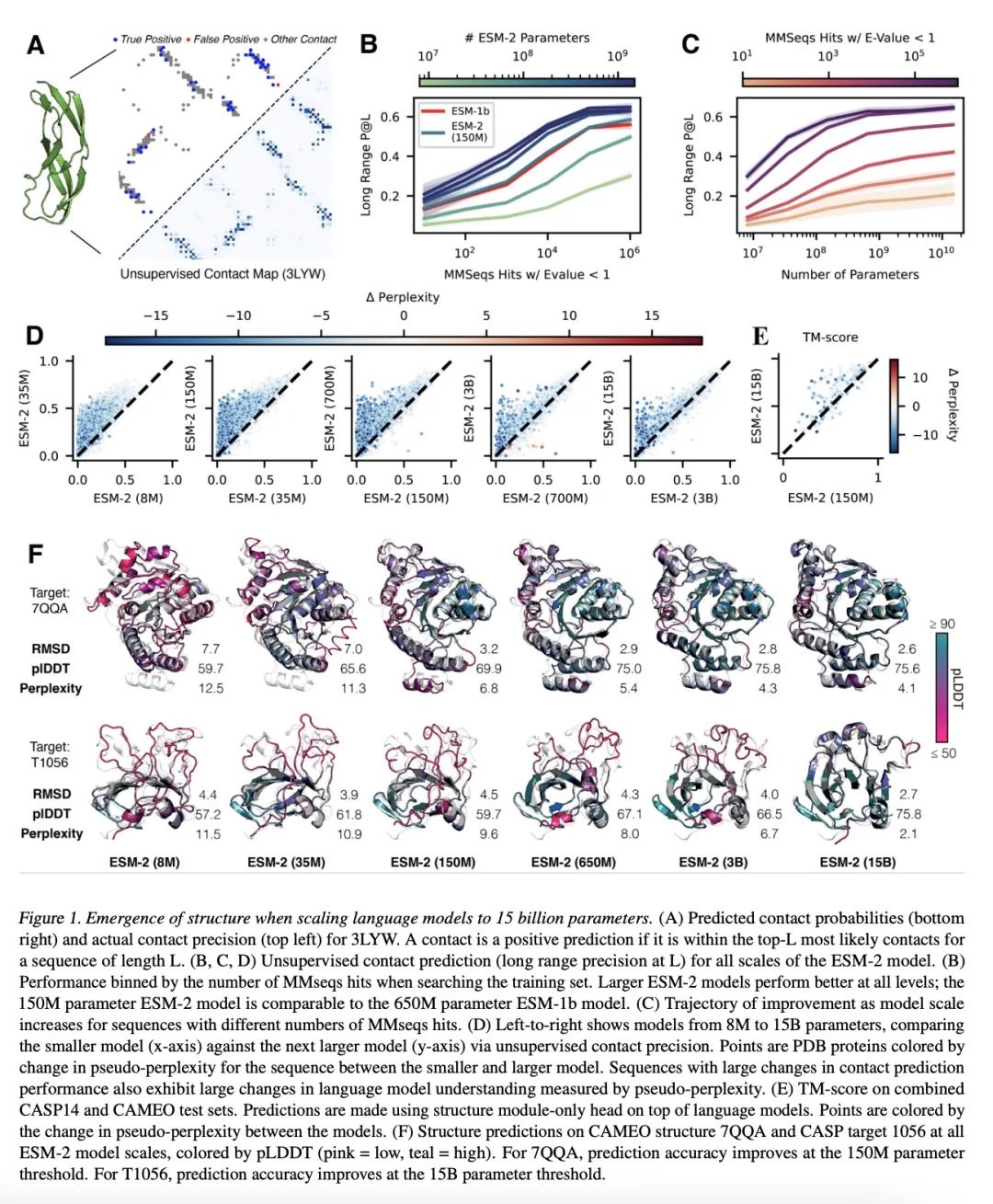
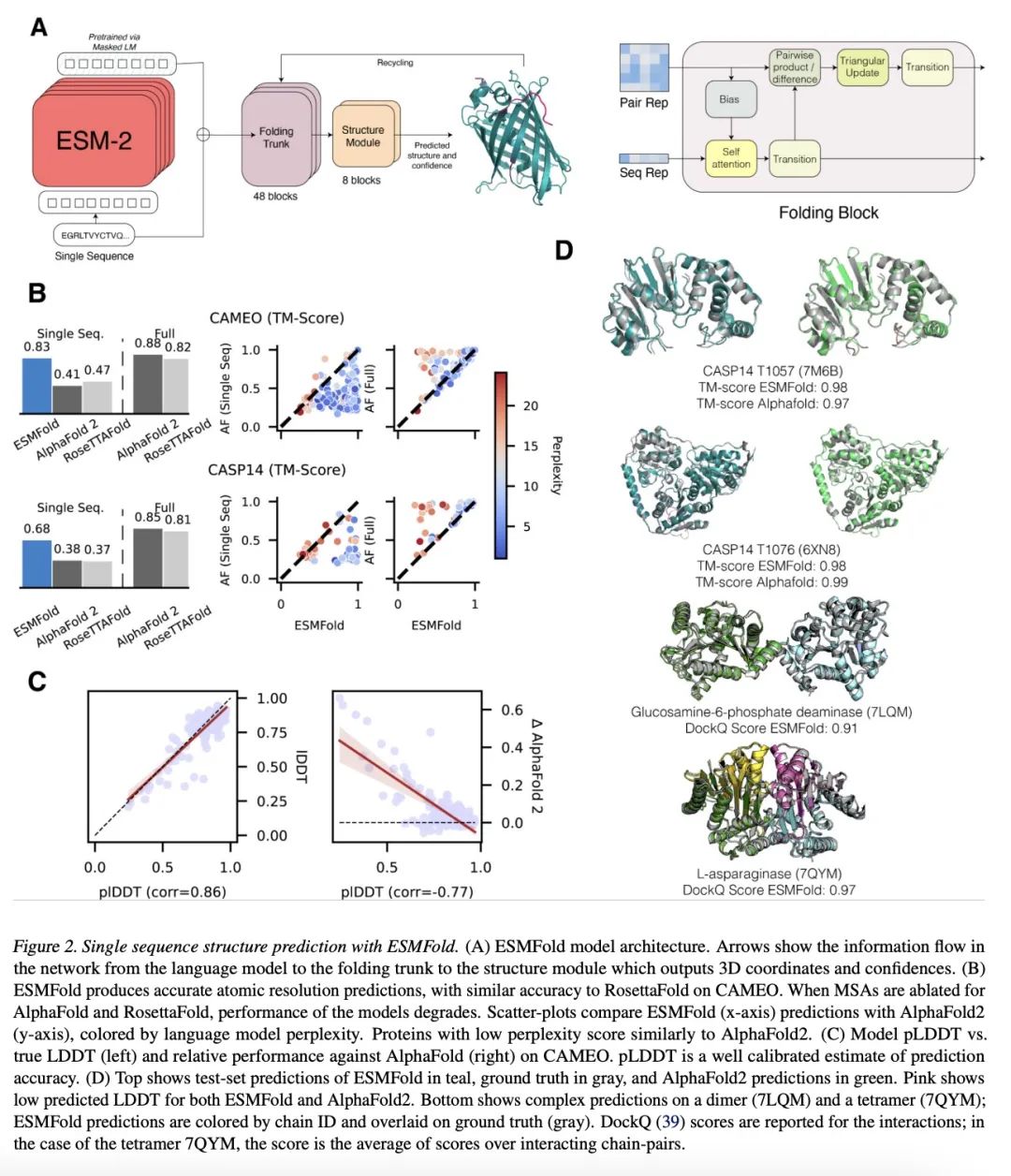
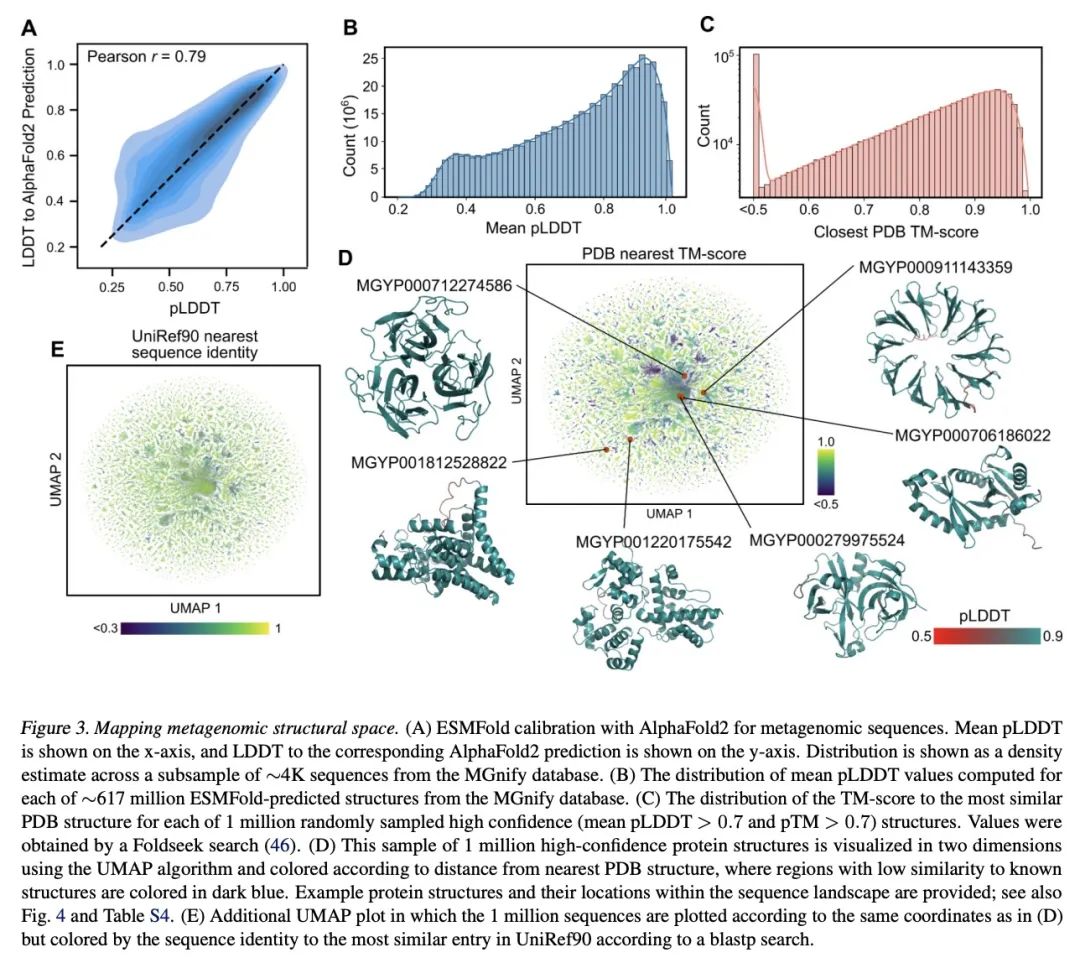
4、[LG] Evolutionary-scale prediction of atomic level protein structure with a language model
Z Lin, H Akin, R Rao, B Hie…
[Meta AI]
基于语言模型的原子级蛋白质结构进化规模预测。人工智能有可能在进化规模上开启对蛋白质结构的洞察力。最近才有可能将蛋白质结构预测扩展到两亿个编目蛋白质。对大规模基因测序实验所揭示的指数级增长的数十亿蛋白质序列的结构进行定性,将需要在折叠速度方面取得突破。本文表明,用大型语言模型从主序列直接推断结构,可以使高分辨率结构预测的速度提高一个数量级。利用语言模型在数以百万计的序列中学习进化模式的洞察力,本文训练了高达150亿个参数的模型,这是迄今为止最大的蛋白质语言模型。随着语言模型的扩展,其学习到的信息能够以单个原子的分辨率预测蛋白质的3D结构。这使得预测的速度比最先进的方法快60倍,同时保持分辨率和精度。在此基础上,本文提出ESM Metagenomic Atlas,第一个大规模元基因组蛋白质结构特征,有超过6.17亿个结构。该图集揭示了超过2.25亿个高置信度的预测,包括数百万个与实验确定的结构相比较新的结构,使人们前所未有地看到地球上一些最不为人所知的蛋白质结构的广阔性和多样性。
Artificial intelligence has the potential to open insight into the structure of proteins at the scale of evolution. It has only recently been possible to extend protein structure prediction to two hundred million cataloged proteins. Characterizing the structures of the exponentially growing billions of protein sequences revealed by large scale gene sequencing experiments would necessitate a breakthrough in the speed of folding. Here we show that direct inference of structure from primary sequence using a large language model enables an order of magnitude speed-up in high resolution structure prediction. Leveraging the insight that language models learn evolutionary patterns across millions of sequences, we train models up to 15B parameters, the largest language model of proteins to date. As the language models are scaled they learn information that enables prediction of the three-dimensional structure of a protein at the resolution of individual atoms. This results in prediction that is up to 60x faster than state-of-the-art while maintaining resolution and accuracy. Building on this, we present the ESM Metagenomic Atlas. This is the first large-scale structural characterization of metagenomic proteins, with more than 617 million structures. The atlas reveals more than 225 million high confidence predictions, including millions whose structures are novel in comparison with experimentally determined structures, giving an unprecedented view into the vast breadth and diversity of the structures of some of the least understood proteins on earth.
https://biorxiv.org/content/10.1101/2022.07.20.500902v2

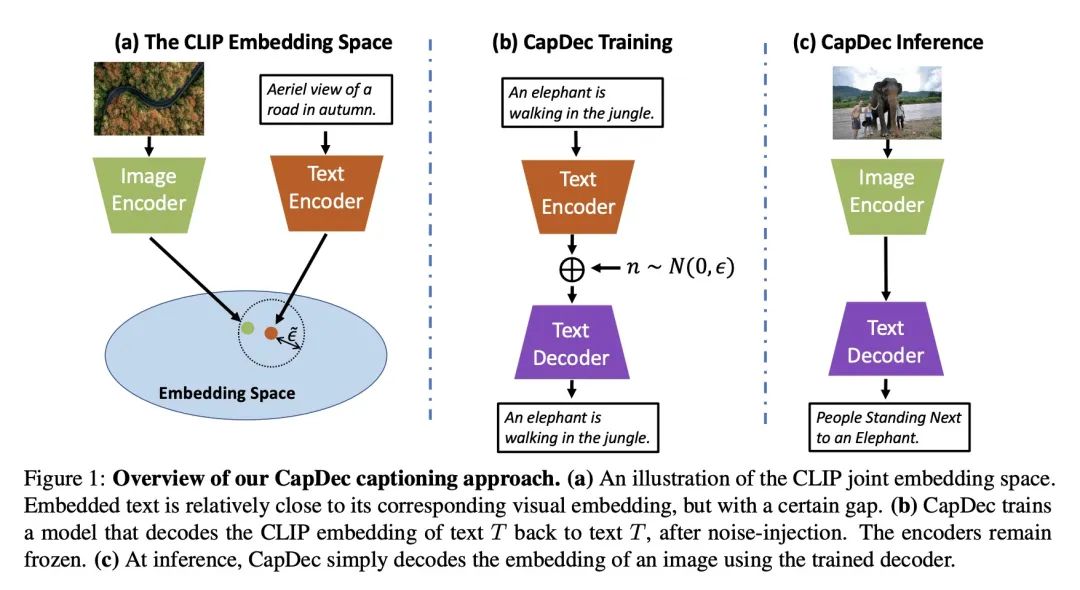
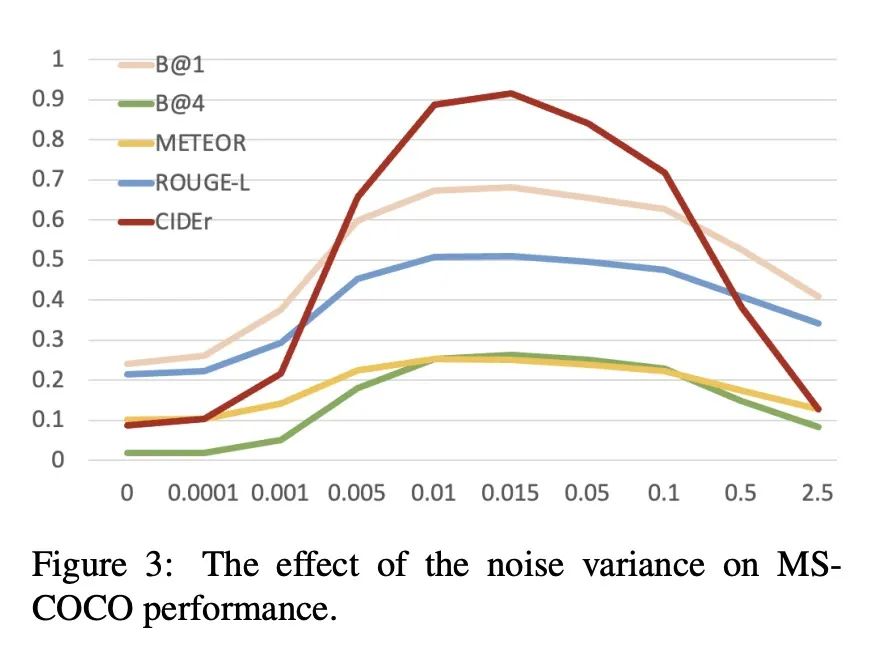
5、[CL] Text-Only Training for Image Captioning using Noise-Injected CLIP
D Nukrai, R Mokady, A Globerson
[Tel Aviv University]
基于噪声注入的CLIP图像描述纯文本训练。本文考虑在训练时只用CLIP模型和额外的文本数据,而不使用额外的带描述图像来进行图像自动描述的任务。该方法依赖这样一个事实,即CLIP被训练成使视觉和文本嵌入相似。因此,只需要学习如何将CLIP的文本嵌入翻译回文本,可以通过学习一个只用文本的冻结CLIP文本编码器的解码器来学习如何做到这一点。这种直觉"几乎无误",因为嵌入空间之间存在差距,并建议在训练期间通过噪声注入来纠正这一问题。通过零样本图像描述基准上实验,包括风格迁移,证明了所提出方法的有效性。
We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
https://arxiv.org/abs/2211.00575


另外几篇值得关注的论文:
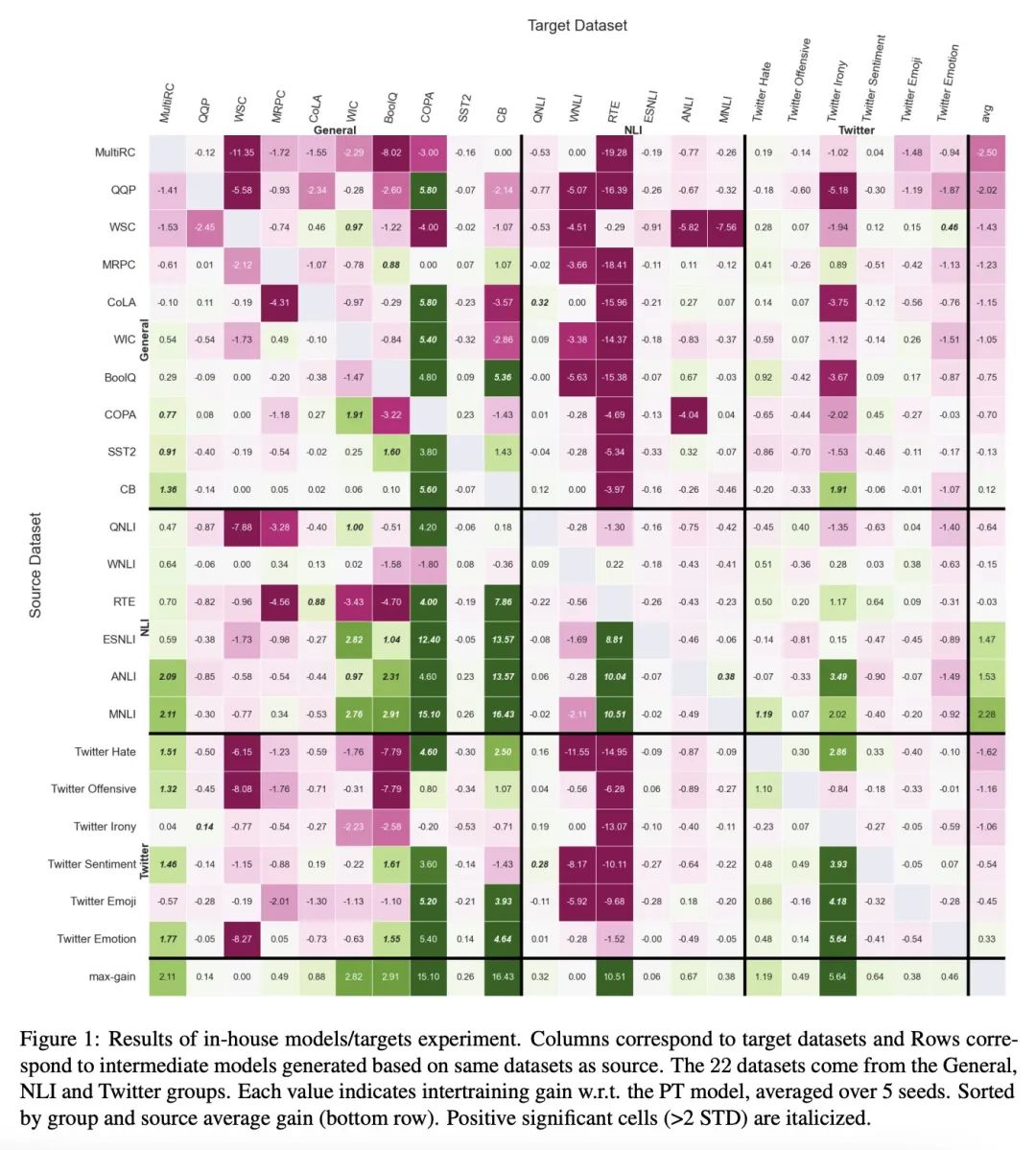
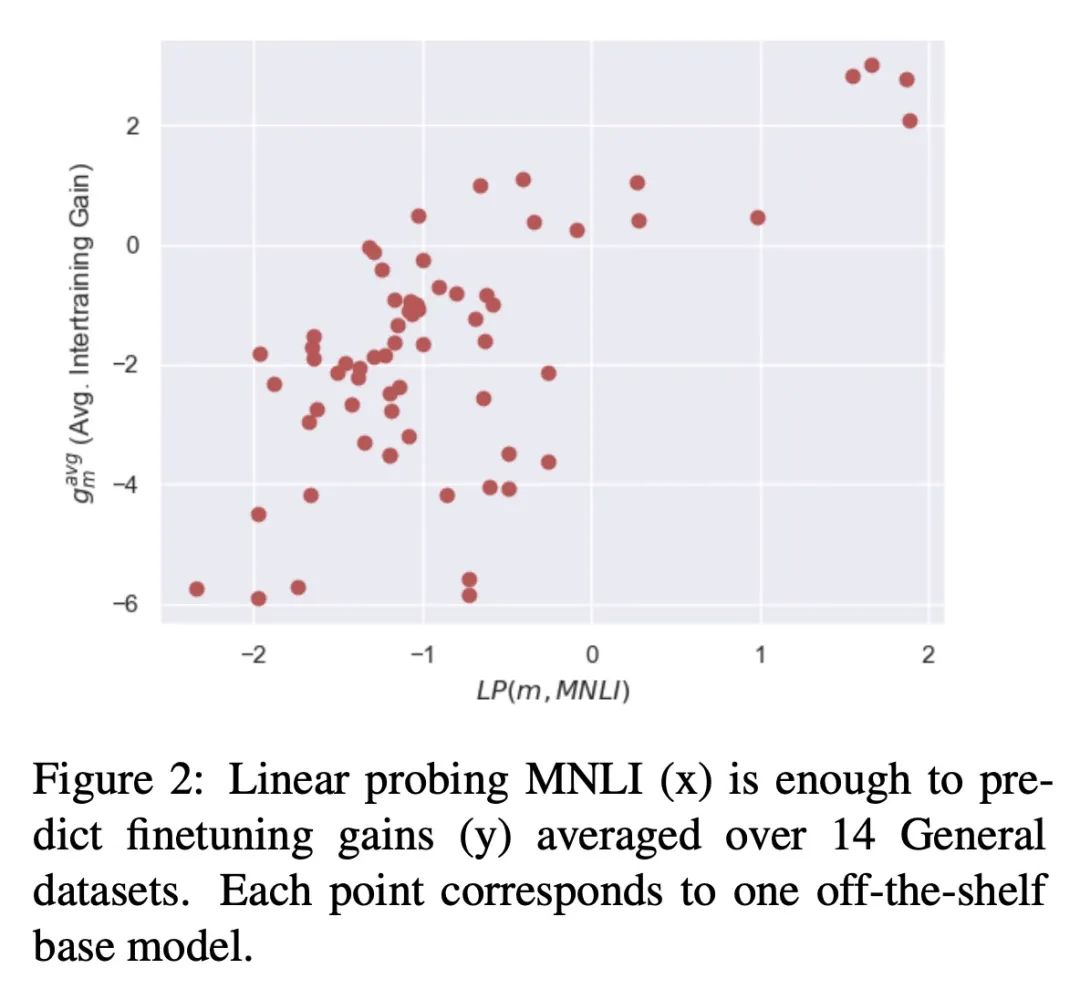
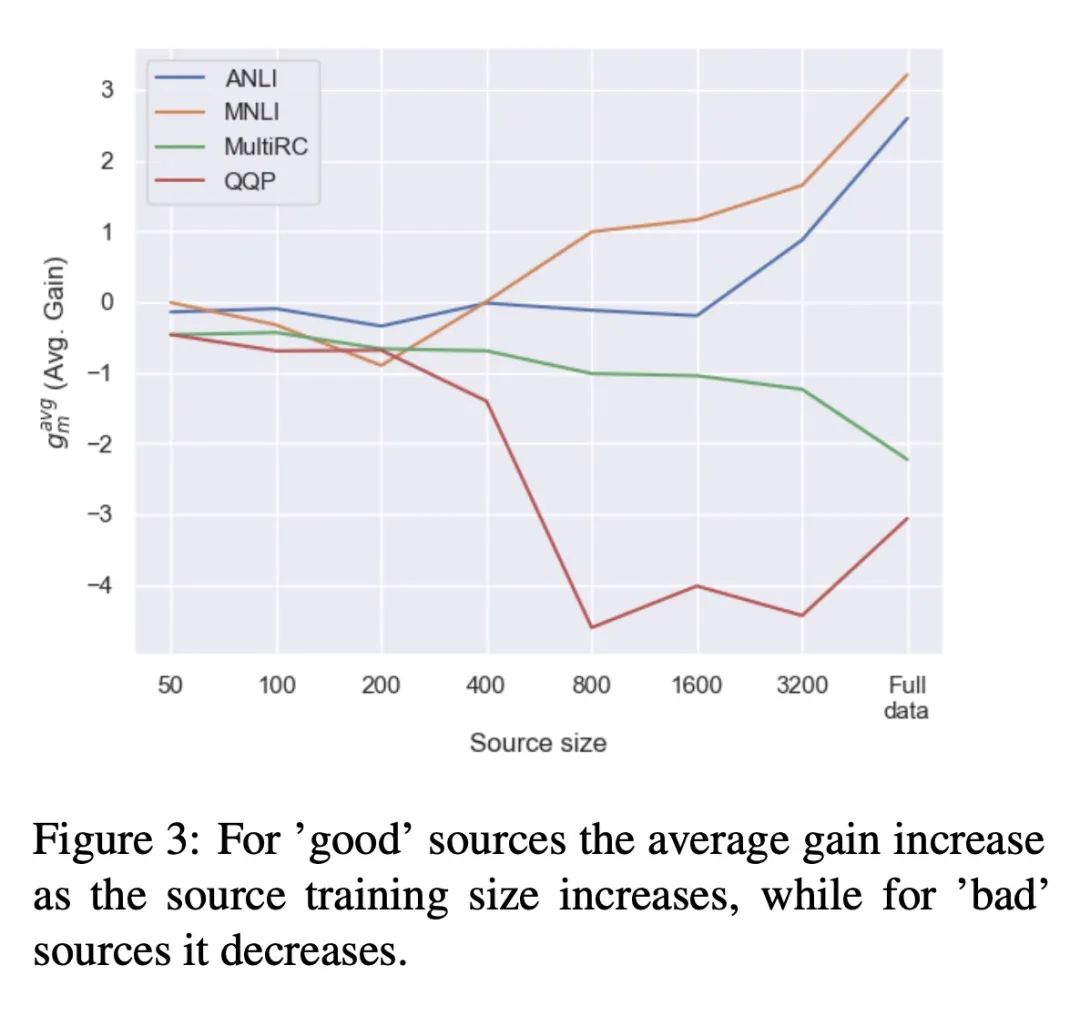
[CL] Where to start? Analyzing the potential value of intermediate models
中间模型潜在价值分析
L Choshen, E Venezian, S Don-Yehia, N Slonim, Y Katz
[IBM Research]
https://arxiv.org/abs/2211.00107

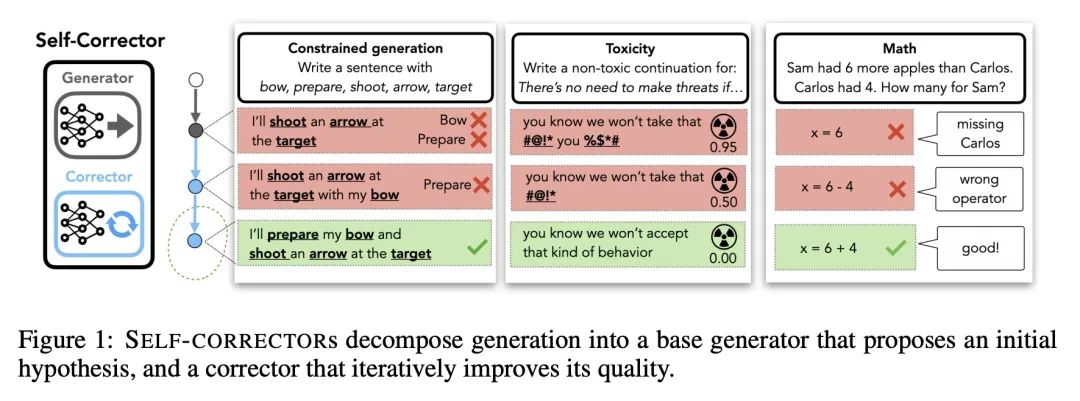
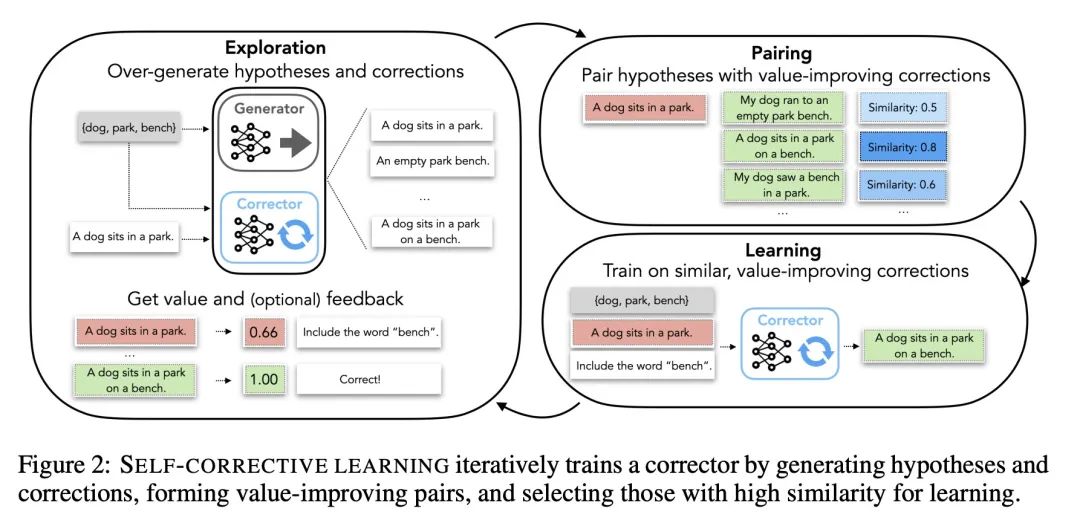
[CL] Generating Sequences by Learning to Self-Correct
基于自纠正学习的序列生成
S Welleck, X Lu, P West, F Brahman, T Shen...
[Allen Institute for Artificial Intelligence & Johns Hopkins University & University of Washington]
https://arxiv.org/abs/2211.00053


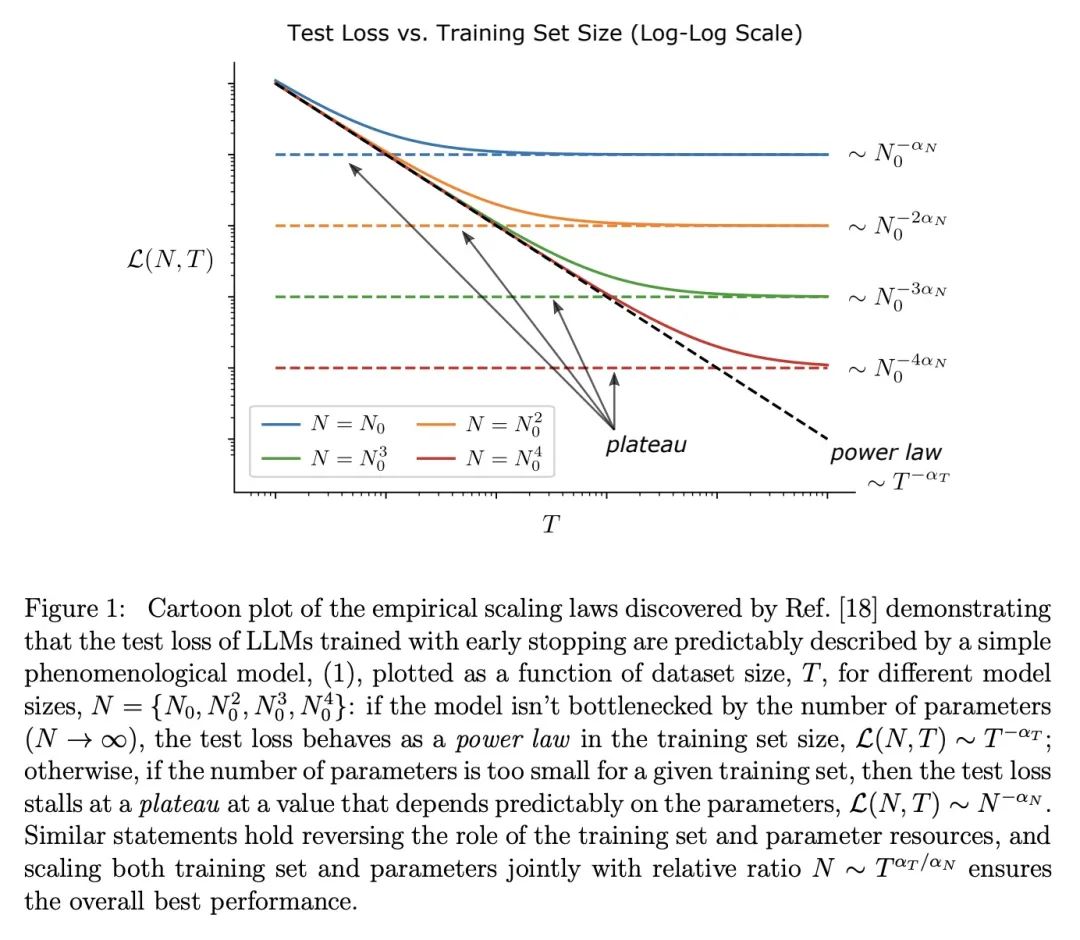
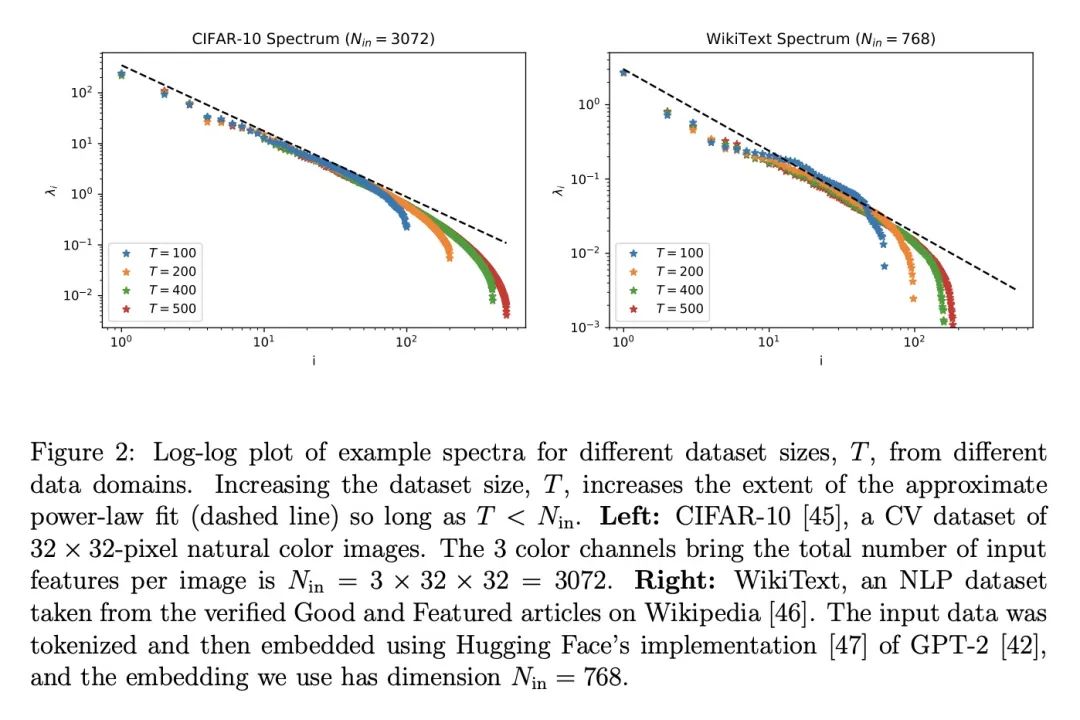
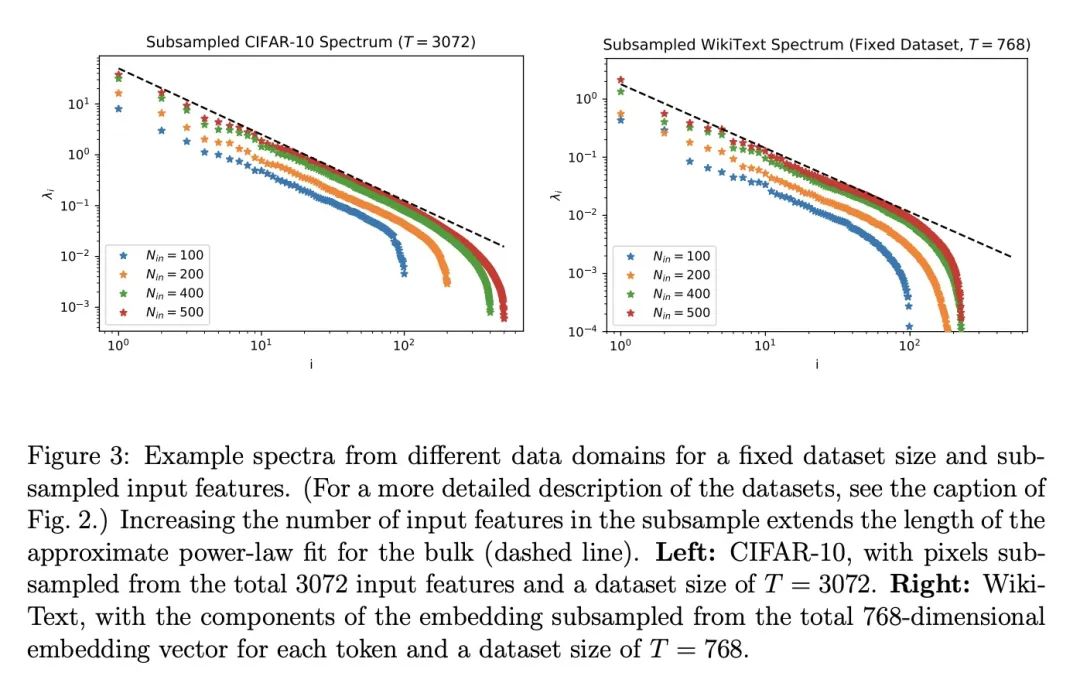
[LG] A Solvable Model of Neural Scaling Laws
一种可解的神经缩放律模型
A Maloney, D A. Roberts, J Sully
[McGill University & MIT & University of British Columbia]
https://arxiv.org/abs/2210.16859

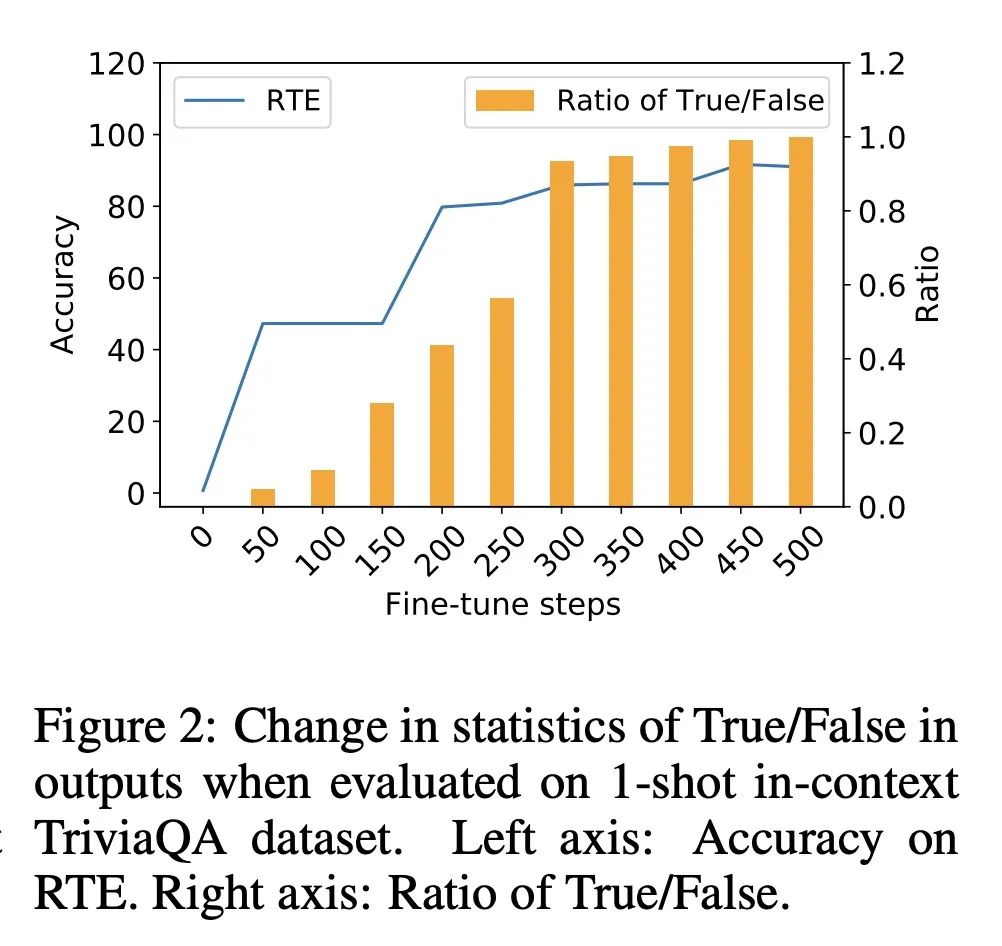
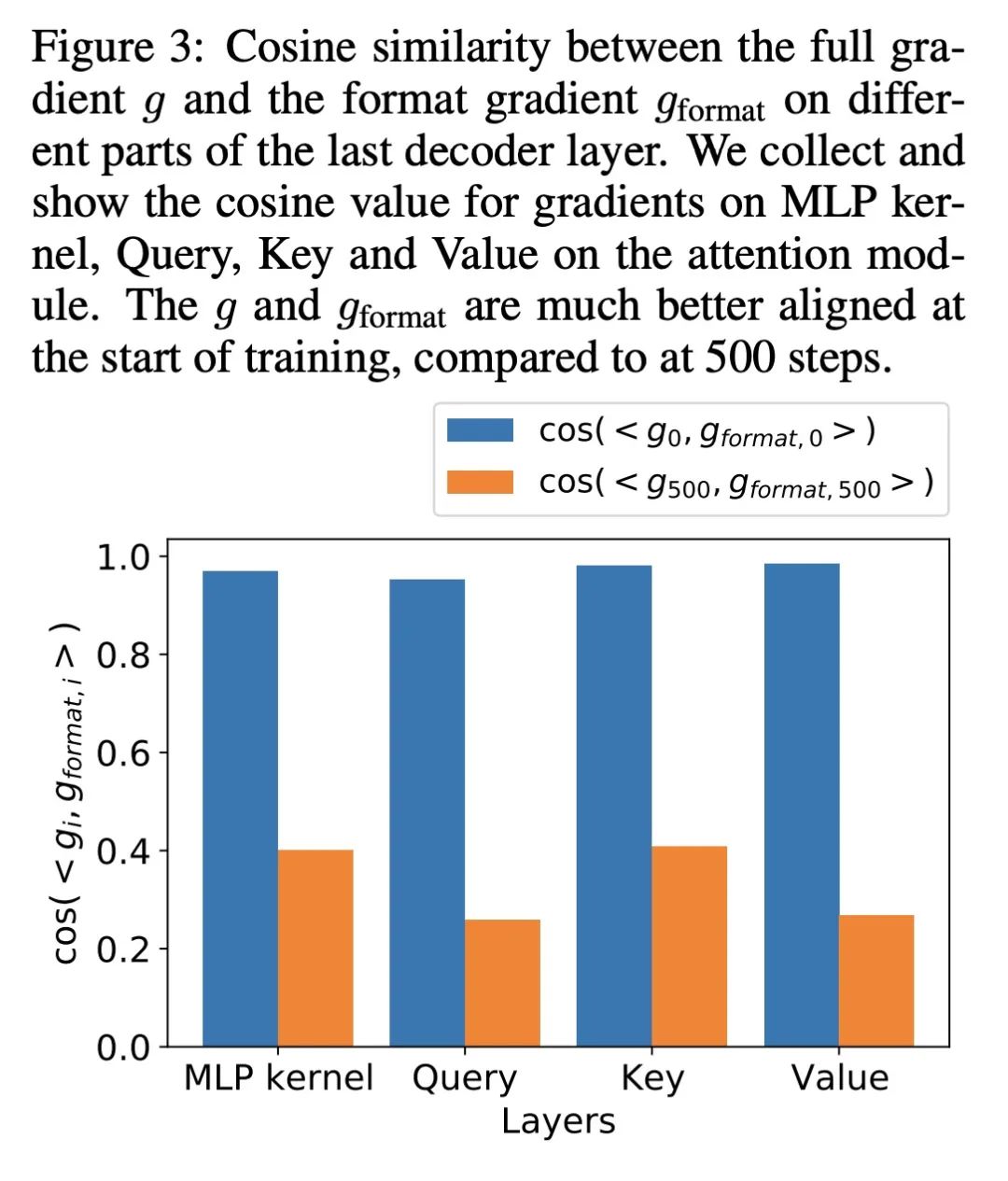
[CL] Preserving In-Context Learning ability in Large Language Model Fine-tuning
在大型语言模型微调中保留上下文学习能力
Y Wang, S Si, D Li, M Lukasik, F Yu, C Hsieh, I S Dhillon, S Kumar
[UCLA & Google]
https://arxiv.org/abs/2211.00635


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢