
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于专家去噪器集成的文本-图像扩散模型、深度神经网络可证最佳线性约束强制、流行音乐钢琴版生成、利用对比学习实现图像数据集无监督可视化、基于目标建议先验的视觉操纵模仿学习、基于真实数据集的离线强化学习、关于数学transformer可解释性和泛化性的三个结果、扩散模型合成图像检测研究、深度学习数据分离法则
1、[CV] eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Y Balaji, S Nah, X Huang, A Vahdat, J Song, K Kreis, M Aittala, T Aila, S Laine, B Catanzaro, T Karras, M Liu
[NVIDIA Corporation]
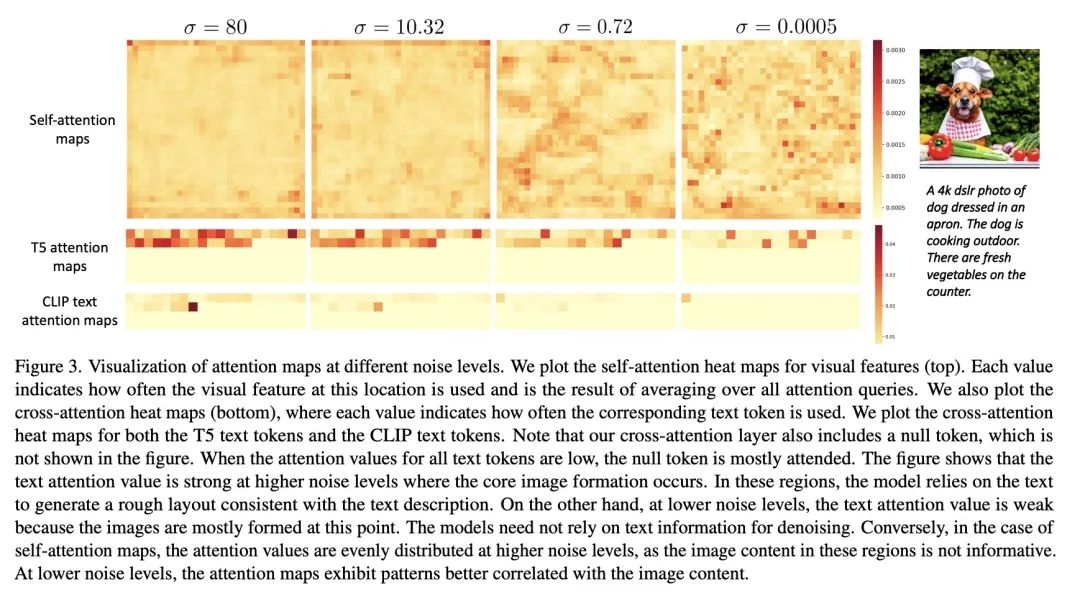
eDiffi: 基于专家去噪器集成的文本-图像扩散模型。大规模的基于扩散的生成模型在文本条件的高分辨率图像合成方面取得了突破性进展。从随机噪声开始,这种文本到图像的扩散模型以一种迭代的方式逐渐合成图像,同时以文本提示为条件进行调节。本文发现,在整个过程中,其合成行为发生了质的变化。在采样早期,生成强烈依赖文本提示来生成文本对齐的内容,而后来,文本调节几乎完全被忽略。这表明,在整个生成过程中共享模型参数可能并不理想。因此,与现有的工作相比,本文建议训练一个专门用于不同合成阶段的文本-图像扩散模型的集成。为保持训练效率,最初训练一个单一的模型,然后将其分成专门的模型,为迭代生成过程的特定阶段进行训练。所提出的扩散模型集合eDiffi,在保持相同的推理计算成本和保留高视觉质量的情况下,实现了改进的文本对齐,在标准基准上超过了之前的大规模文本到图像的扩散模型。此外,训练该模型以利用各种嵌入进行调节,包括T5文本、CLIP文本和CLIP图像嵌入,不同的嵌入会导致不同的行为。值得注意的是,CLIP图像嵌入允许以一种直观的方式将参考图像的风格迁移到目标文本到图像的输出。最后,本文展示了一种技术,使eDiffi的"用字作画"能力得以实现。用户可以选择输入文本中的单词,并在画布上画出它来控制输出,这对于精心设计心中所需的图像非常方便。
Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiffi, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiffi's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at this https URL
https://arxiv.org/abs/2211.01324


2、[LG] POLICE: Provably Optimal Linear Constraint Enforcement for Deep Neural Networks
R Balestriero, Y LeCun
[Meta AI]
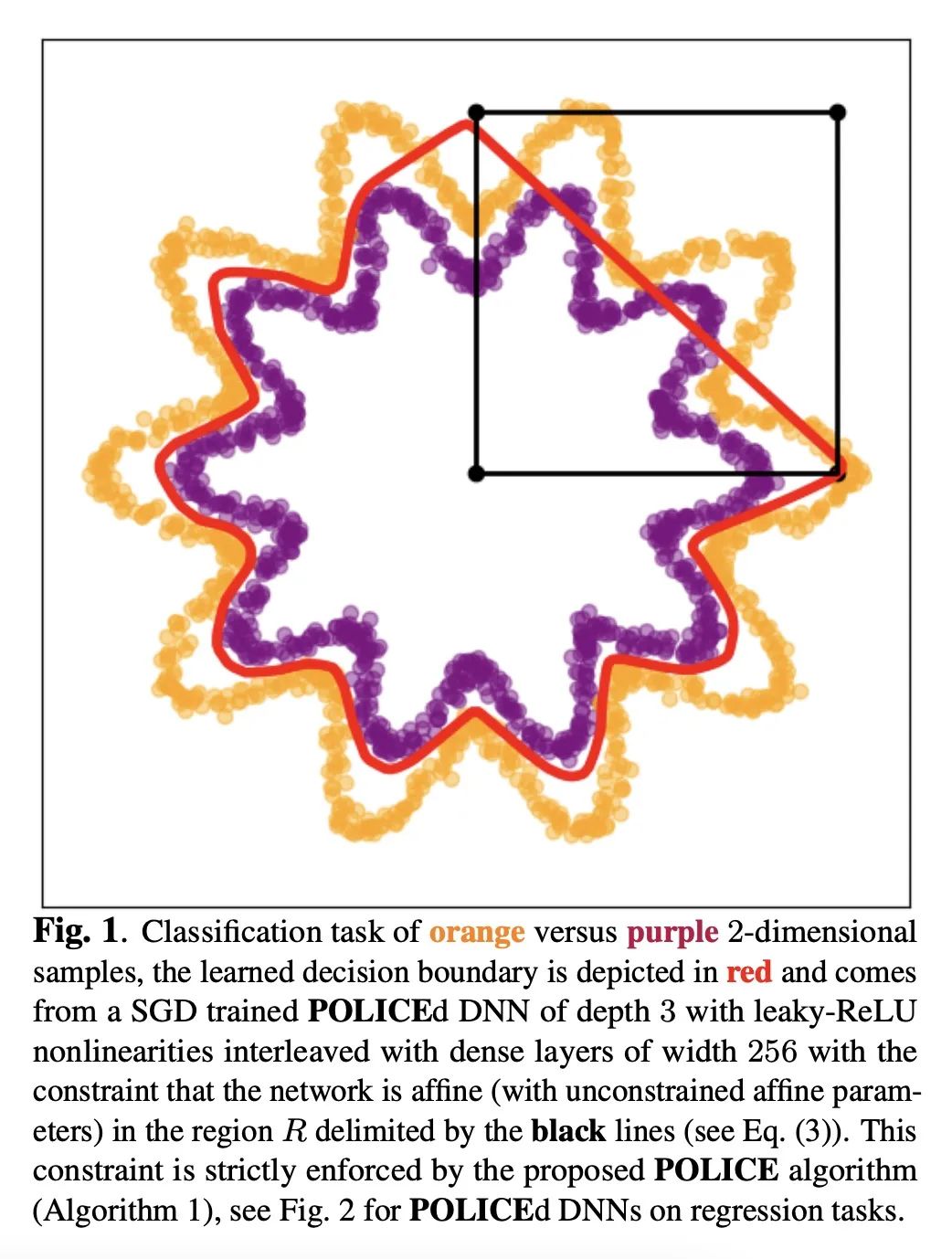
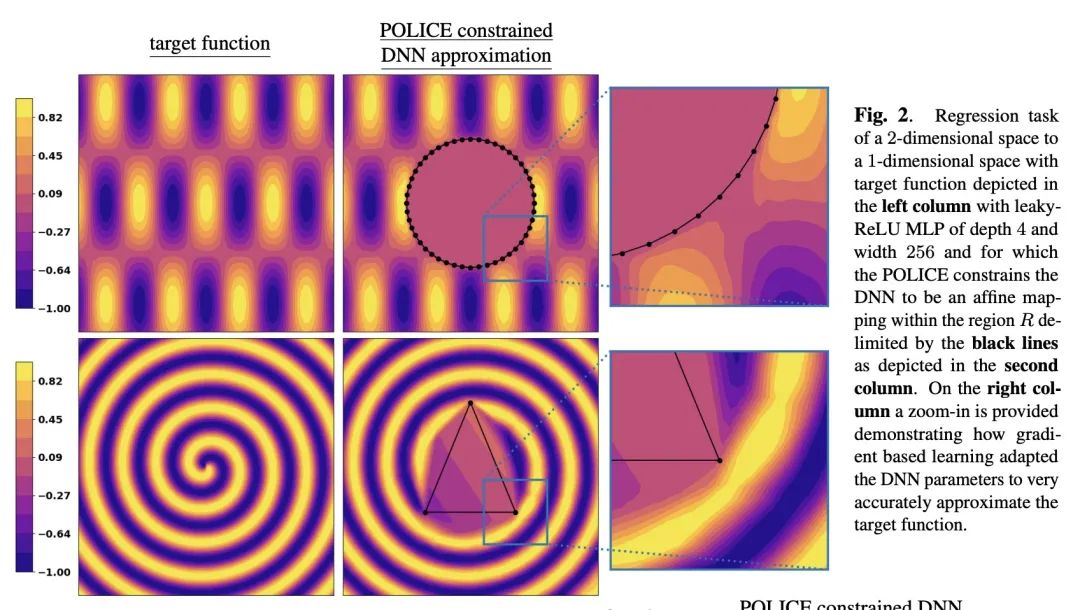
POLICE:深度神经网络可证最佳线性约束强制。深度神经网络(DNN)在许多情况下胜过其他函数近似器,这要归功于它们在组成任意所需的可微算子方面的模块化。形成的参数化函数可以通过简单的梯度下降来解决手头的任务。这种模块化是以严格执行DNN的约束为代价的,例如,来自任务的先验知识,或来自所需的物理特性,这是一个公开的挑战。本文提出了第一个可证仿射约束强制方法,该方法需要对给定的DNN的前向通道进行最小的改变,在计算上是友好的,并且使DNN的参数优化不受约束,即可采用基于梯度的标准方法。该方法不需要任何抽样,并可证明确保DNN在训练和测试期间的任何时候都能满足对给定输入空间区域的仿射约束。将该方法命名为POLICE,代表可证明的最佳近似约束强制。
Deep Neural Networks (DNNs) outshine alternative function approximators in many settings thanks to their modularity in composing any desired differentiable operator. The formed parametrized functional is then tuned to solve a task at hand from simple gradient descent. This modularity comes at the cost of making strict enforcement of constraints on DNNs, e.g. from a priori knowledge of the task, or from desired physical properties, an open challenge. In this paper we propose the first provable affine constraint enforcement method for DNNs that requires minimal changes into a given DNN's forward-pass, that is computationally friendly, and that leaves the optimization of the DNN's parameter to be unconstrained i.e. standard gradient-based method can be employed. Our method does not require any sampling and provably ensures that the DNN fulfills the affine constraint on a given input space's region at any point during training, and testing. We coin this method POLICE, standing for Provably Optimal LInear Constraint Enforcement.
https://arxiv.org/abs/2211.01340


3、[AS] Pop2Piano : Pop Audio-based Piano Cover Generation
J Choi, K Lee
[rebellions Inc & Seoul National University]
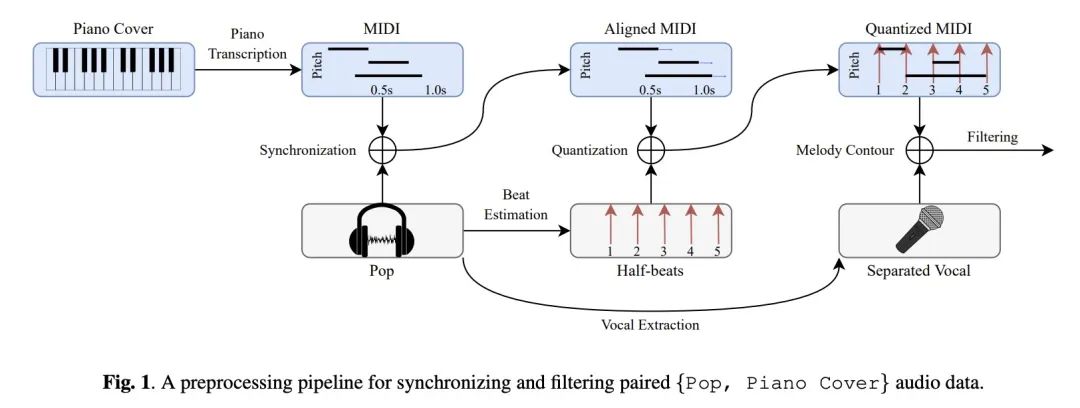
Pop2Piano : 流行音乐钢琴版生成。流行音乐的钢琴版被人们广泛喜爱。然而,流行音乐钢琴版的生成任务仍未得到充分研究。这部分是由于缺乏同步的{流行音乐,钢琴版}数据对,使得应用最新的基于数据密集型的深度学习方法成为挑战。为了发挥数据驱动方法的威力,本文利用自动流水线制作了大量的配对和同步的{流行音乐,钢琴版}数据。本文提出了Pop2Piano,一个Transformer网络,可以在给定的流行音乐波形下生成钢琴版。这是第一个在没有旋律和和弦提取模块的情况下从流行音乐中直接生成钢琴版的模型。实验表明,用所提出数据集训练的Pop2Piano可以生成可信的钢琴版。
The piano cover of pop music is widely enjoyed by people. However, the generation task of the pop piano cover is still understudied. This is partly due to the lack of synchronized {Pop, Piano Cover} data pairs, which made it challenging to apply the latest data-intensive deep learning-based methods. To leverage the power of the data-driven approach, we make a large amount of paired and synchronized {pop, piano cover} data using an automated pipeline. In this paper, we present Pop2Piano, a Transformer network that generates piano covers given waveforms of pop music. To the best of our knowledge, this is the first model to directly generate a piano cover from pop audio without melody and chord extraction modules. We show that Pop2Piano trained with our dataset can generate plausible piano covers.
https://arxiv.org/abs/2211.00895

4、[LG] Unsupervised visualization of image datasets using contrastive learning
J N Böhm, P Berens, D Kobak
[University of Tubingen]
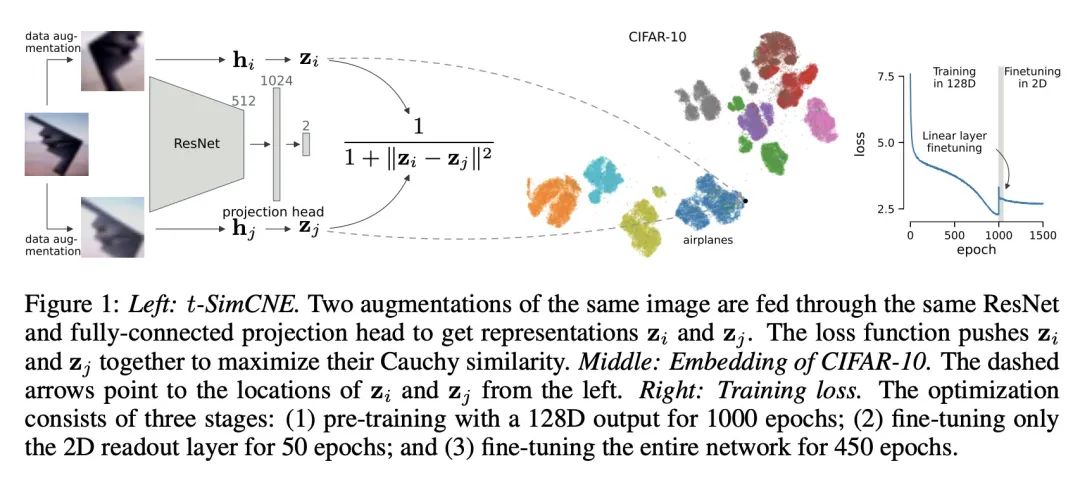
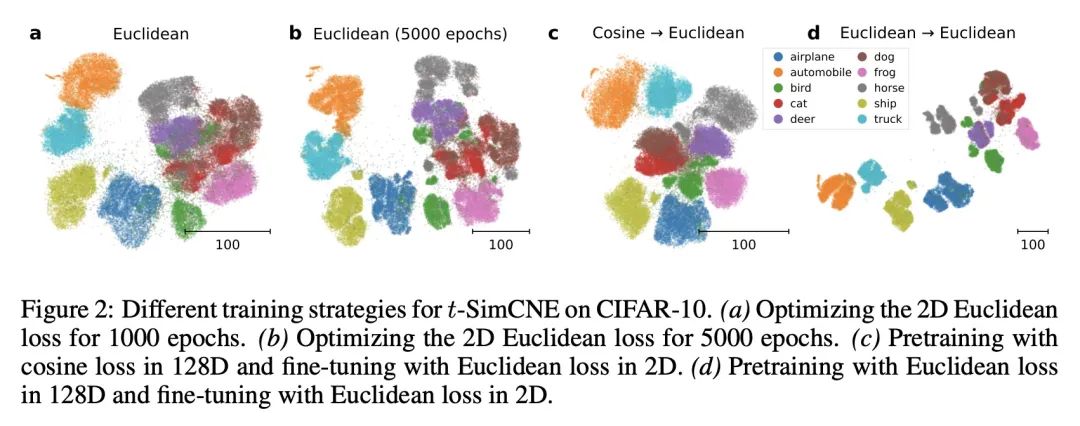
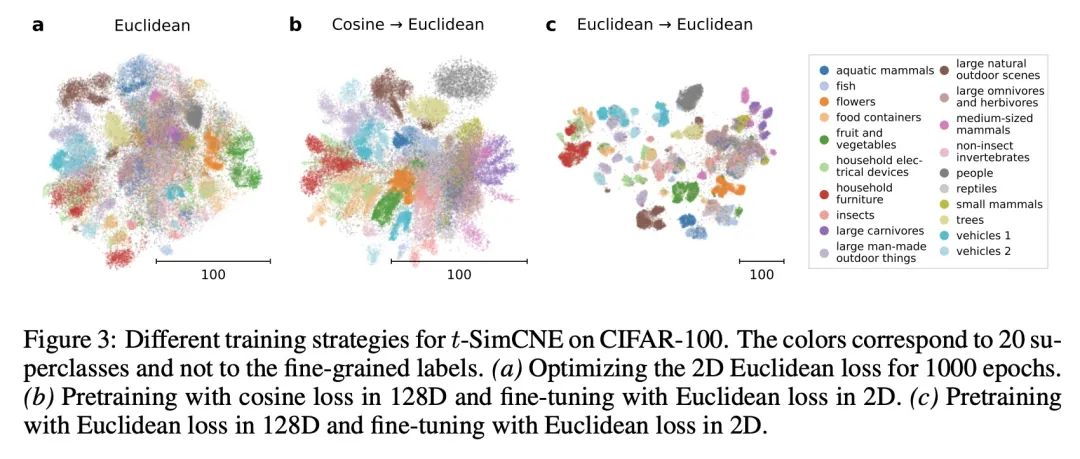
利用对比学习实现图像数据集无监督可视化。基于近邻图的可视化方法,如t-SNE或UMAP,被广泛用于高维数据的可视化。然而,这些方法只有在最近邻本身是有意义的情况下才能产生有意义的结果。对于用像素空间表示的图像来说,情况并非如此,因为像素空间的距离往往不能捕捉到人对相似性的感觉,因此近邻在语义上并不紧密。这个问题可以通过基于对比学习的自监督方法来规避,比如SimCLR,依赖于数据增强来产生隐性近邻,但是这些方法并不能产生适合可视化的二维嵌入。本文提出一种新的方法t-SimCNE,用于图像数据的无监督可视化。T-SimCNE结合了对比学习和近邻嵌入的思想,训练了一个从高维像素空间到二维的参数映射。本文表明,由此产生的二维嵌入实现了与最先进的高维SimCLR表示相媲美的分类精度,从而忠实地捕捉了语义关系。使用t-SimCNE,获得了CIFAR-10和CIFAR-100数据集的信息可视化,显示了丰富的集群结构,并突出了伪影和异常值。
Visualization methods based on the nearest neighbor graph, such as t-SNE or UMAP, are widely used for visualizing high-dimensional data. Yet, these approaches only produce meaningful results if the nearest neighbors themselves are meaningful. For images represented in pixel space this is not the case, as distances in pixel space are often not capturing our sense of similarity and therefore neighbors are not semantically close. This problem can be circumvented by self-supervised approaches based on contrastive learning, such as SimCLR, relying on data augmentation to generate implicit neighbors, but these methods do not produce two-dimensional embeddings suitable for visualization. Here, we present a new method, called t-SimCNE, for unsupervised visualization of image data. T-SimCNE combines ideas from contrastive learning and neighbor embeddings, and trains a parametric mapping from the high-dimensional pixel space into two dimensions. We show that the resulting 2D embeddings achieve classification accuracy comparable to the state-of-the-art high-dimensional SimCLR representations, thus faithfully capturing semantic relationships. Using t-SimCNE, we obtain informative visualizations of the CIFAR-10 and CIFAR-100 datasets, showing rich cluster structure and highlighting artifacts and outliers.
https://arxiv.org/abs/2210.09879

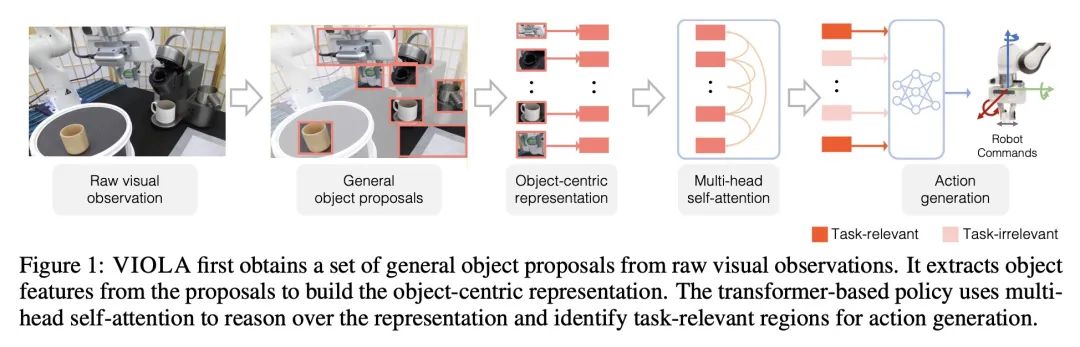
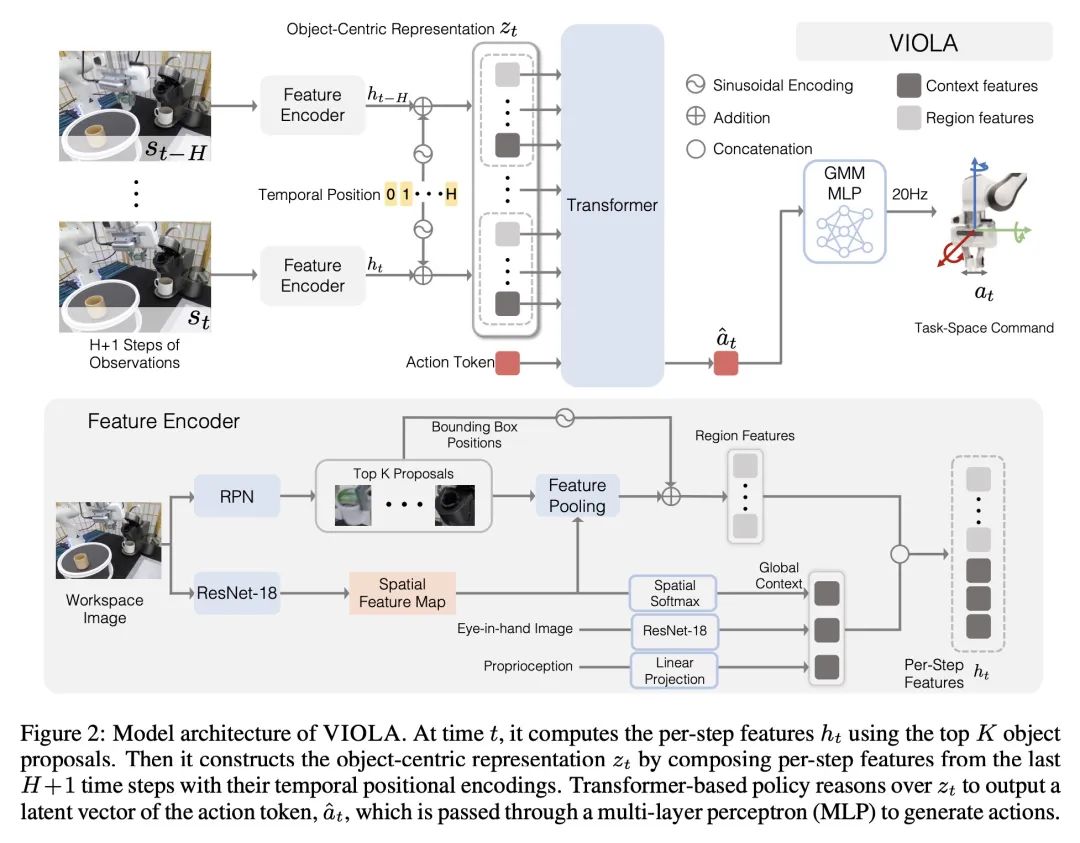
5、[RO] VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors
Y Zhu, A Joshi, P Stone, Y Zhu
[The University of Texas at Austin]
VIOLA:基于目标建议先验的视觉操纵模仿学习。本文提出VIOLA,一种以目标为中心的模仿学习方法,用于学习机器人操纵的闭环视觉运动策略。该方法是根据预训练好的视觉模型的一般目标建议来构建以目标为中心的表示。VIOLA使用一个基于transformer的策略来推理这些表征,并关注与任务相关的视觉因素以进行动作预测。这种基于物体的结构先验提高了深度模仿学习算法对目标变化和环境扰动的鲁棒性。本文在模拟和真实机器人上对VIOLA进行了定量评估。VIOLA的成功率比最先进的模仿学习方法高出45.8%。还成功地部署在一个物理机器人上,以解决具有挑战性的长跨度任务,如餐桌布置和咖啡制作。
We introduce VIOLA, an object-centric imitation learning approach to learning closed-loop visuomotor policies for robot manipulation. Our approach constructs object-centric representations based on general object proposals from a pre-trained vision model. VIOLA uses a transformer-based policy to reason over these representations and attend to the task-relevant visual factors for action prediction. Such object-based structural priors improve deep imitation learning algorithm's robustness against object variations and environmental perturbations. We quantitatively evaluate VIOLA in simulation and on real robots. VIOLA outperforms the state-of-the-art imitation learning methods by 45.8% in success rate. It has also been deployed successfully on a physical robot to solve challenging long-horizon tasks, such as dining table arrangement and coffee making. More videos and model details can be found in supplementary material and the project website: this https URL .
https://arxiv.org/abs/2210.11339


另外几篇值得关注的论文:
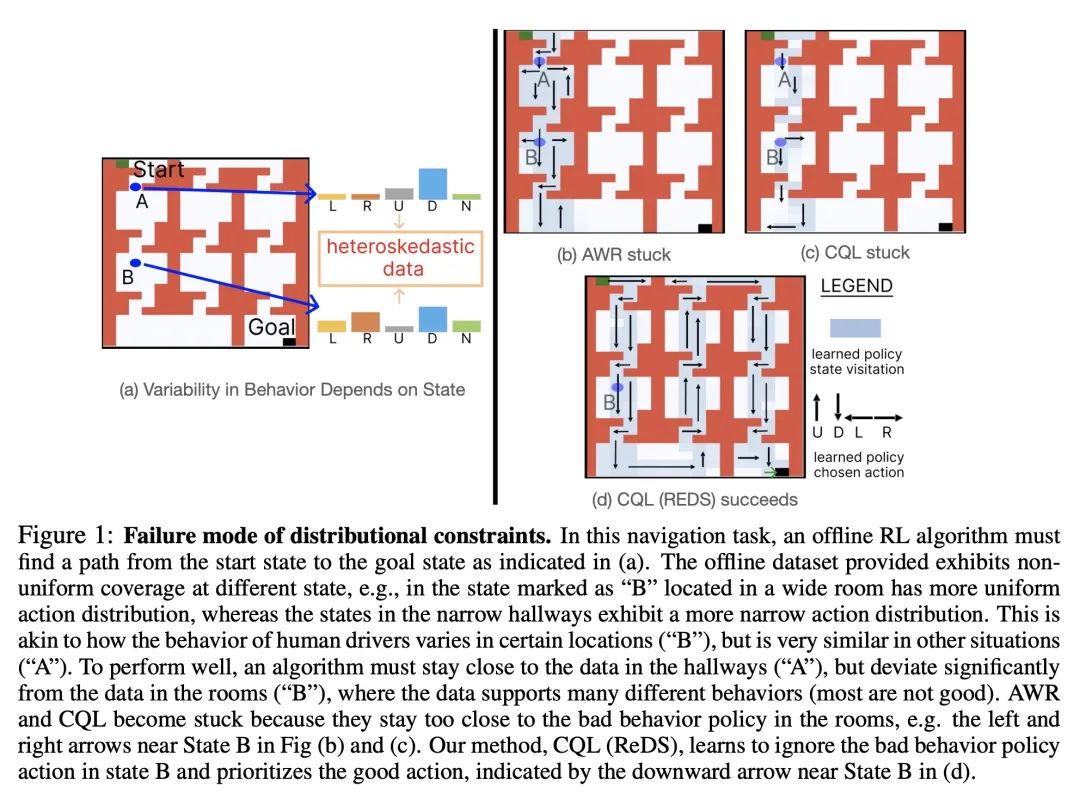
[LG] Offline RL With Realistic Datasets: Heteroskedasticity and Support Constraints
基于真实数据集的离线强化学习:异方差性和支持约束
A Singh, A Kumar, Q Vuong, Y Chebotar, S Levine
[UC Berkeley & Google Research]
https://arxiv.org/abs/2211.01052

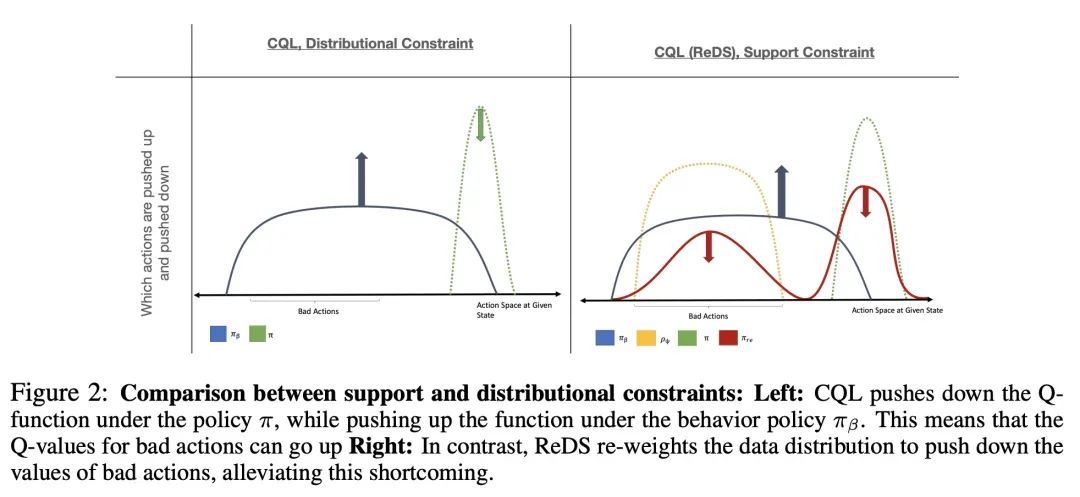
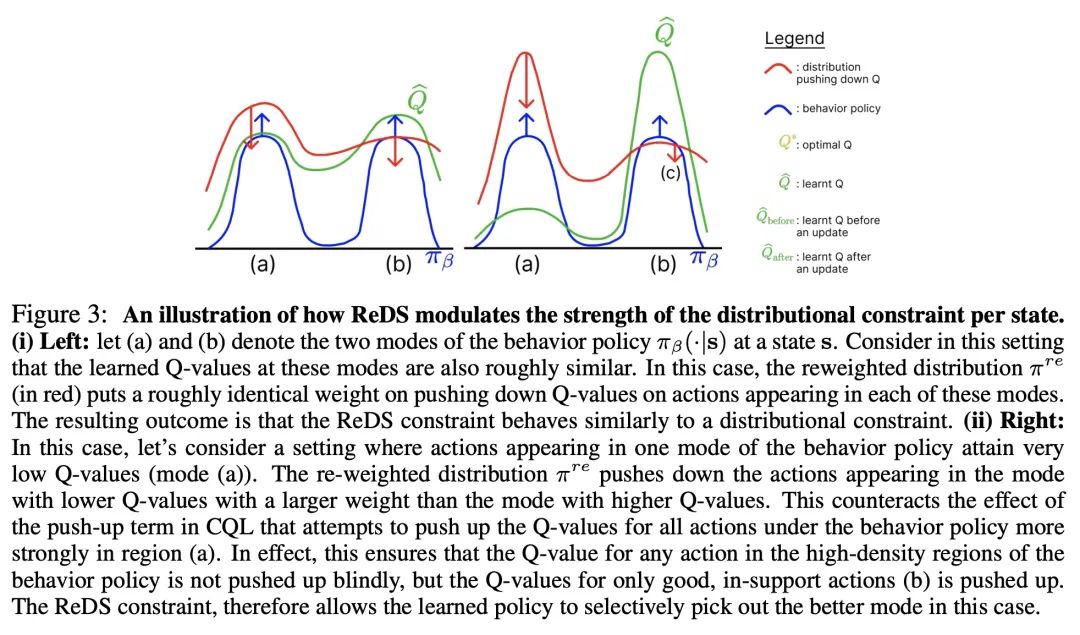
[LG] What is my math transformer doing? -- Three results on interpretability and generalization
数学transformer在做什么? ——可解释性和泛化性的三个结果
F Charton
[Meta AI]
https://arxiv.org/abs/2211.00170

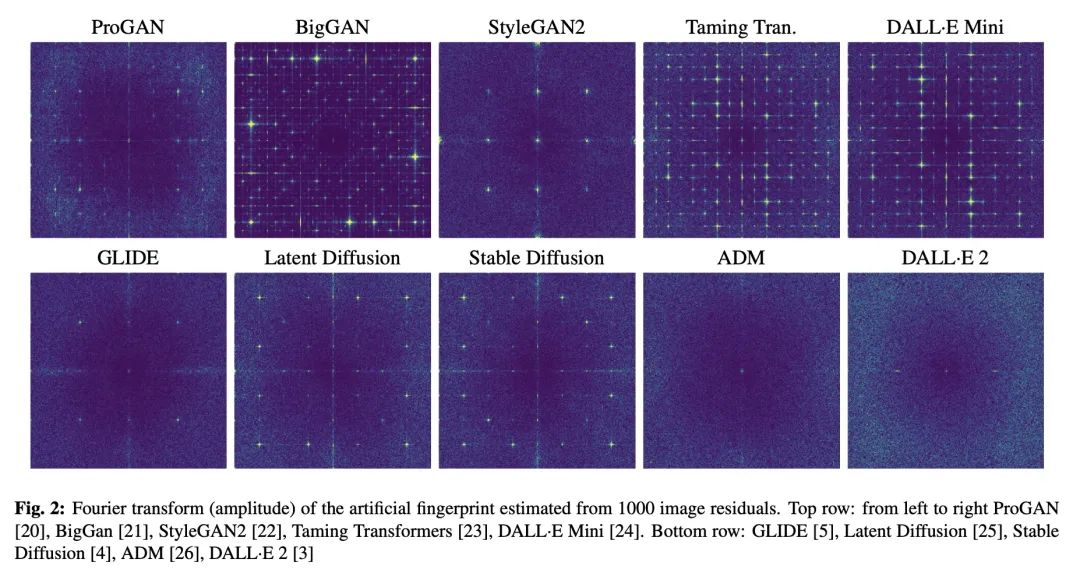
[CV] On the detection of synthetic images generated by diffusion models
扩散模型合成图像检测研究
R Corvi, D Cozzolino, G Zingarini, G Poggi, K Nagano, L Verdoliva
[University Federico II of Naples & NVIDIA]
https://arxiv.org/abs/2211.00680


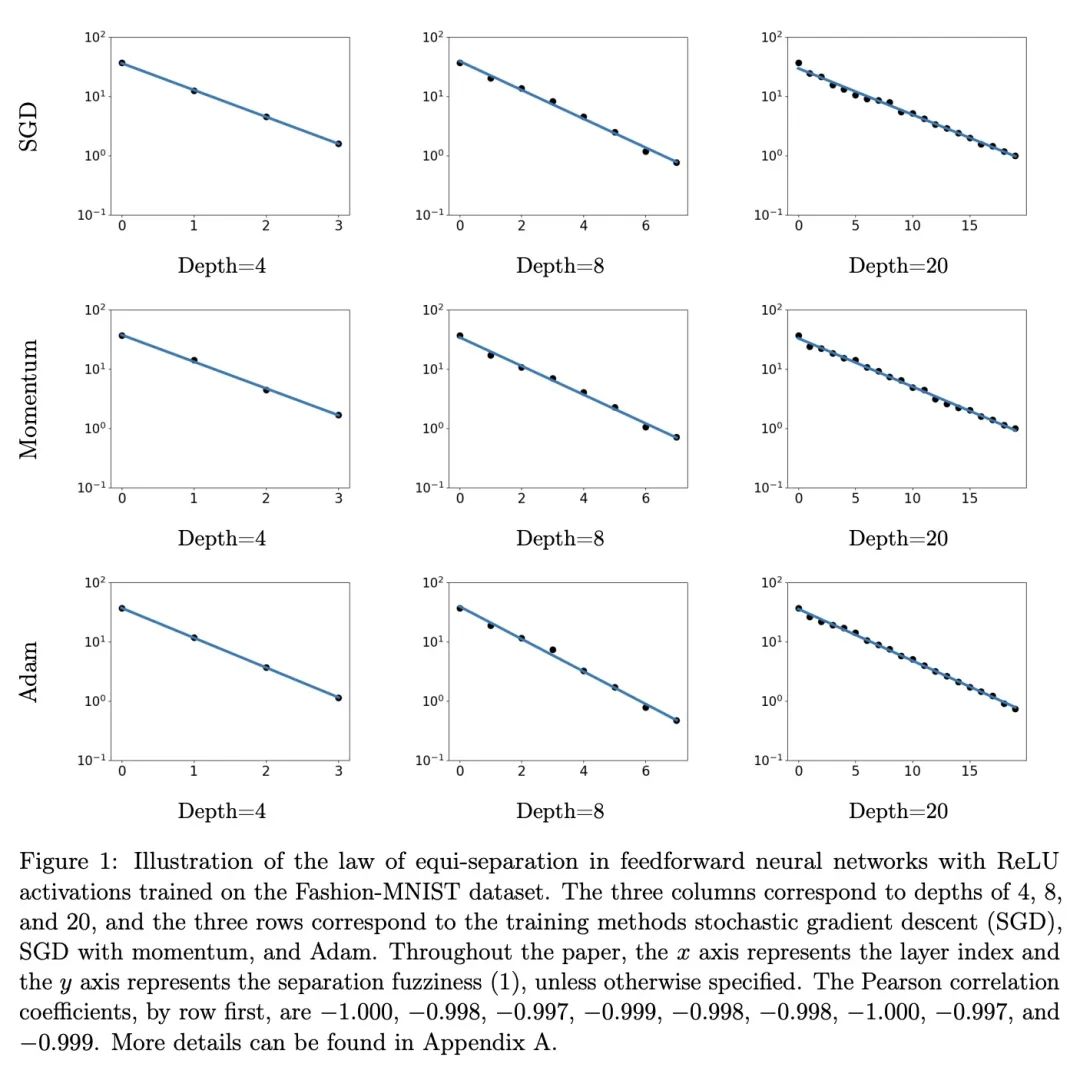
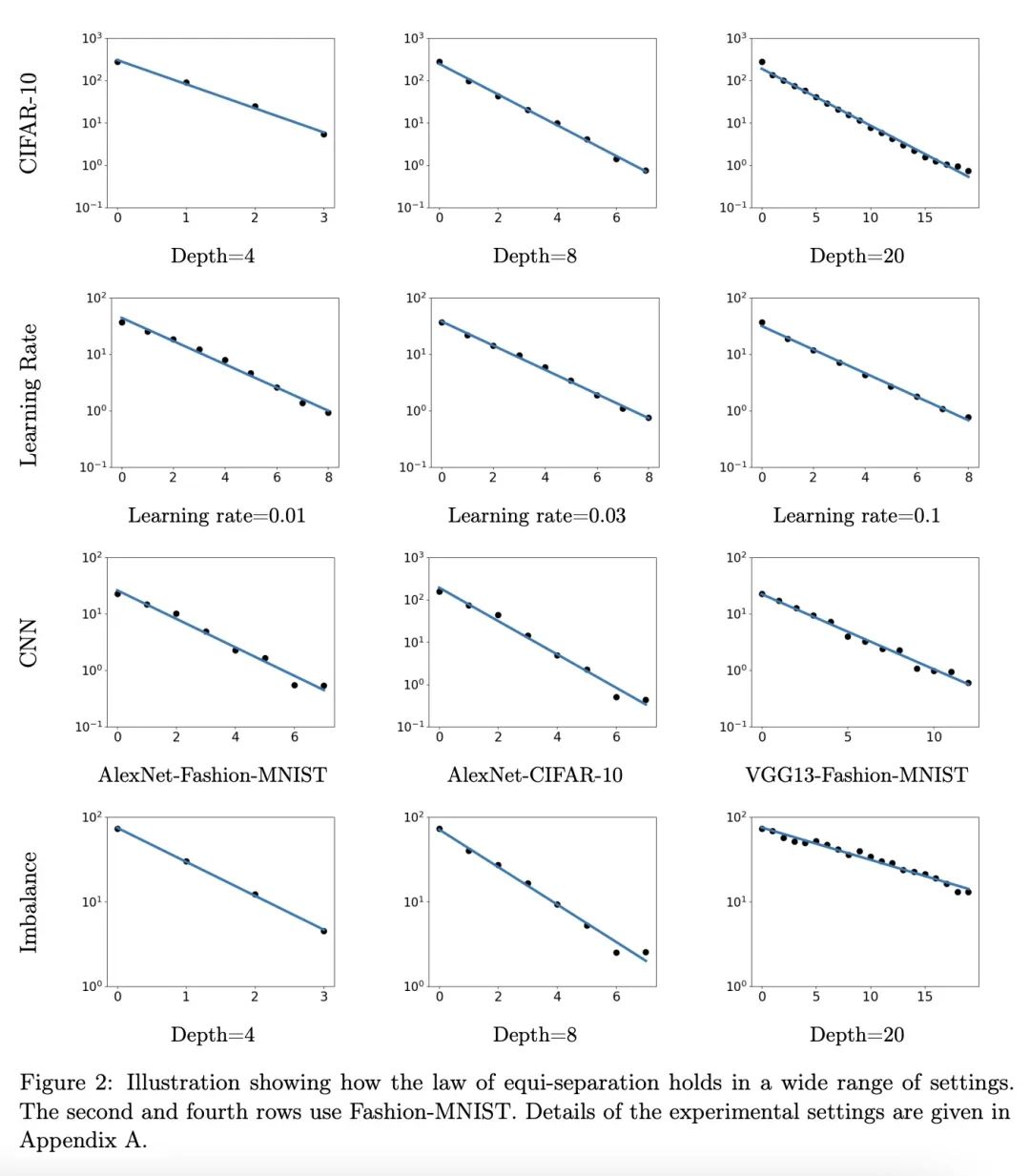
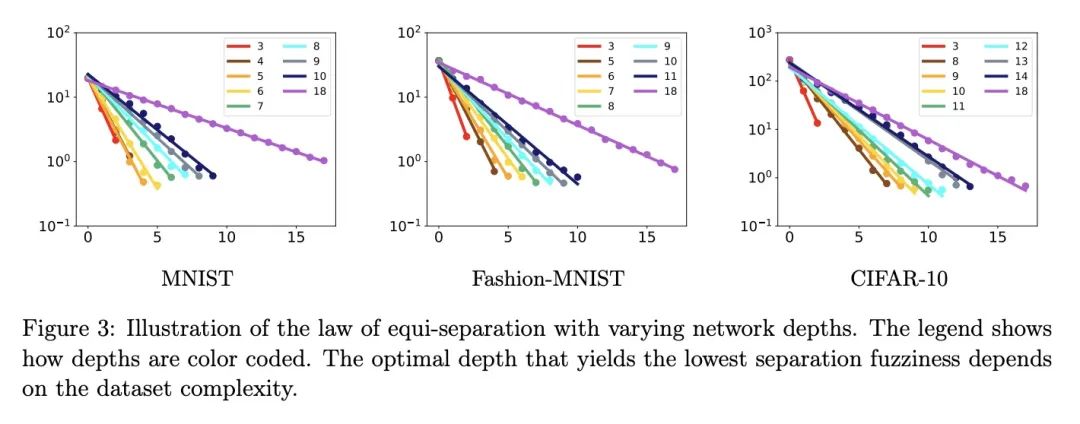
[LG] A Law of Data Separation in Deep Learning
深度学习数据分离法则
H He, W J. Su
[University of Rochester & University of Pennsylvania]
https://arxiv.org/abs/2210.17020

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢