
如今,各行各业正在向数字化转型,海量的文档型数据也源源不断地生成。用人工处理这些蕴含着丰富信息的文档,存在如耗时长、成本高、易出错等缺陷,在实际应用中难以高效执行。因此,社会对于自动化文档处理技术的需求日益增加,智能文档处理(IDP)成为了近几年的热点。与此同时,市场上也涌现出了许多相关产品,例如微软就提供了全方位的 IDP 服务及解决方案(https://adoption.microsoft.com/intelligent-document-processing/)。如图1所示,智能文档处理通过光学字符识别(OCR)、文档图像分析、计算机视觉,以及自然语言处理等技术,将复杂的非结构化文档数据转变为能被计算机直接理解和使用的结构化数据,从而帮助企业或个人更加高效地获取文档中的有用信息。
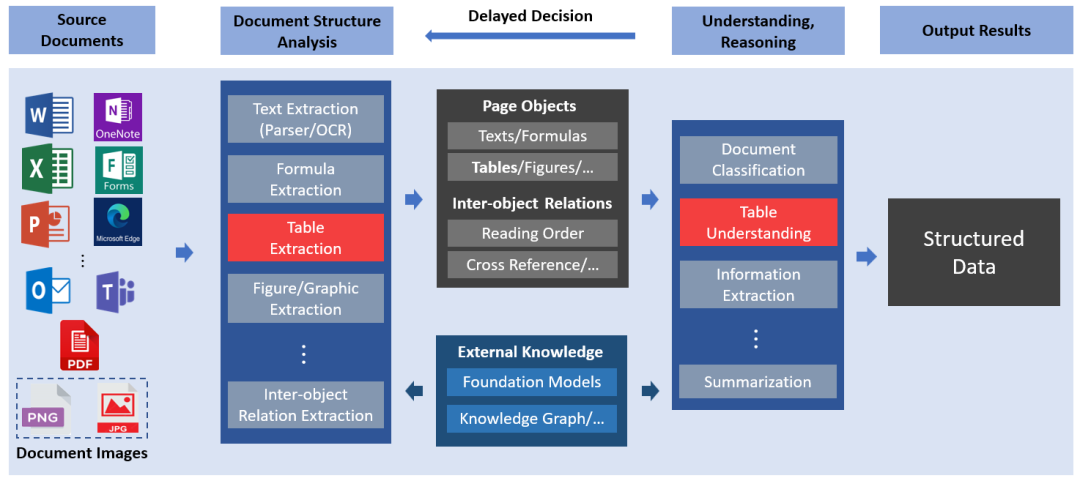
图1:智能文档处理(IDP)的流程示意图
在各类文档中,表格作为一种高效的信息表达形式,通常被人们用来呈现结构化的数据,例如公司财报、发票、银行流水、实验数据、医院检验报告等等。如何抽取及理解表格的技术一直都是 IDP 中的重要组成部分。
表格抽取技术解决的主要问题是如何自动地将图像中的表格数字化,其包含两个子任务:表格检测和表格结构识别。其中,表格结构识别旨在从表格的图像中还原表格的结构信息,包括每个单元格的坐标位置以及每个单元格所属的行列信息。如图2所示,在实际场景中,表格结构识别是一个极具挑战性的问题。其挑战的难度主要在于表格的结构与内容的复杂多样性,例如存在完全无边界和实线的表格、包含许多空白单元格或者跨行跨列单元格的表格、行列之间存在大片空白区域的表格、嵌套的表格、密集的大表格、单元格包含多行文字内容的表格等等。不仅如此,在相机拍摄的场景中,有些表格的边框可能因拍摄角度而倾斜或弯曲,这都大大增加了表格结构识别的难度。




图2:表格图像的多样性与复杂性(左右滑动查看更多)
近年来,表格结构识别领域受到了学术界与工业界的广泛关注,其中涌现出了大量研究成果。但这些研究成果的视角大多仅限于简单的应用场景,例如 PDF 或扫描文档中横平竖直的表格或分割线均为实线的表格,而对于图2中这些在实际场景中经常出现的情况,尤其是倾斜、弯曲且没有实线的表格关注度较低。因此,现有的算法距离完全解决实际场景中的表格识别问题还存在很大差距。为了让表格识别技术适用于更广泛的应用场景,微软亚洲研究院的研究员们提出了一种新的表格结构识别算法 TSRFormer[1],该算法能够较好地识别复杂场景中不同类型的表格。
自底向上范式一般需要依赖额外的模块预先检测文本或单元格作为基础单元,再预测这些基础单元是否属于同一行、列或单元格从而定位表格结构。所以该范式难以处理包含大量空白单元格或空行空列的表格。
不同于以上两种范式,亚洲研究院的研究员们发现基于拆分-合并范式的方法具有更强的可扩展性,在复杂场景中只需要较少的训练数据就能达到很高的精度,而且可以鲁棒地处理包含空白单元格以及空行空列的表格。因此,基于该范式研究员们提出了 TSRFormer。如图3所示,对于输入的表格图像,TSRFormer 先由拆分模块预测出所有行、列的表格分割线,求交点后,生成 N x M 个单元格,再由合并模块预测相邻单元格是否需要合并从而恢复出跨多行、多列的单元格。
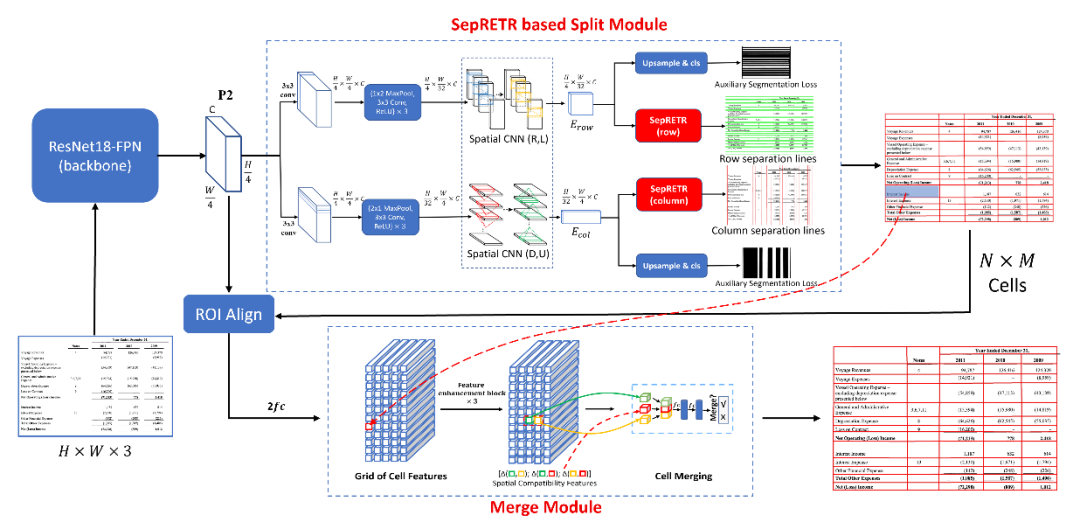
图3:TSRFormer 的整体结构图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢