

目前最先进的神经机器翻译模型主要是自回归(autoregressive, AR)模型,即在解码时从左向右依次生成目标端单词。尽管具有很强的性能,但这种顺序解码会导致较高的解码时延,在效率方面不令人满意。相比之下,非自回归(non-autoregressive, NAR)模型使用更加高效的并行解码,在解码时同时生成所有的目标端单词。为此,NAR模型需要对目标端引入条件独立假设。然而,这一假设无法在概率上准确地描述人类语言数据中的多模态现象(或多样性现象,即一条源端句存在多个正确的翻译结果)。这为NAR模型带来了严峻的挑战,因为条件独立假设与传统的极大似然估计(Maximum Likelihood Estimate, MLE)训练方式无法为NAR模型提供足够信息量的学习信号和梯度。因此,NAR模型经常产生较差的神经表示,尤其是在解码器(Decoder)部分。而由于解码器部分直接控制生成,从而导致了NAR模型显著的性能下降。为了提升NAR模型的性能,大多数先前的研究旨在使用更多的条件信息来改进目标端依赖关系的建模(GLAT[4], CMLM[5])。我们认为,这些研究工作相当于在不改变NAR模型概率框架的前提下提供更好的替代学习信号。并且,这些工作中的大部分需要对模型结构进行特定的修改。
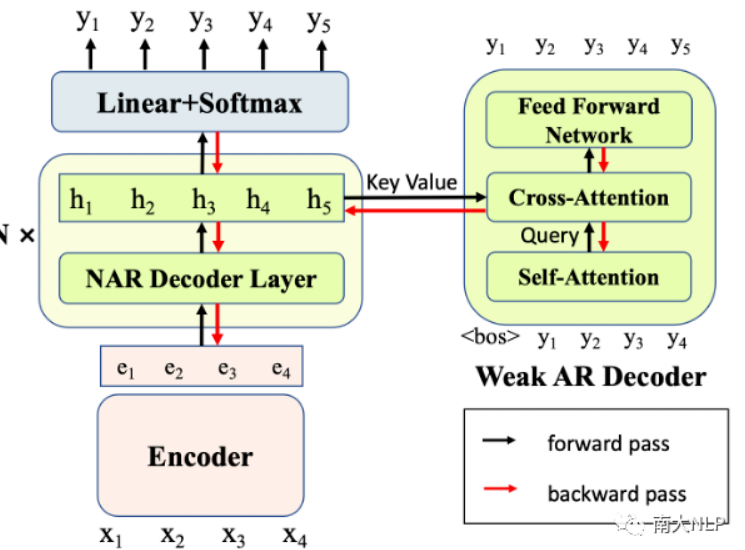
沿着这个思路,我们希望能够为NAR模型提供更具信息量的学习信号,以便更好地捕获目标端依赖。同时,最好可以无需对模型结构进行特定的修改,适配多种不同的NAR模型。因此,在本文中我们提出了一种简单且有效的多任务学习框架。我们引入了一系列解码能力较弱的AR Decoder来辅助NAR模型训练。随着弱AR Decoder的训练,NAR模型的隐层表示中将包含更多的上下文和依赖信息,继而提高了NAR模型的解码性能。同时,我们的方法是即插即用的,且对NAR模型的结构没有特定的要求。并且我们引入的AR Decoder仅在训练阶段使用,因此没有带来额外的解码开销。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢