
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于语言模型程序的具身控制、大型语言模型是人类水平的提示工程师、神经辐射场的成对配准、语言模型逆向缩放性能呈U型趋势、从文本零样本生成高保真和多样化的形状、176B参数语言模型BLOOM碳足迹估算、条件GAN和扩散模型的高效空间稀疏推理、多向量检索用作稀疏对齐、用认知神经网络微调语言模型
1、[RO] Code as Policies: Language Model Programs for Embodied Control
J Liang, W Huang, F Xia, P Xu, K Hausman, B Ichter, P Florence, A Zeng
[Robotics at Google]
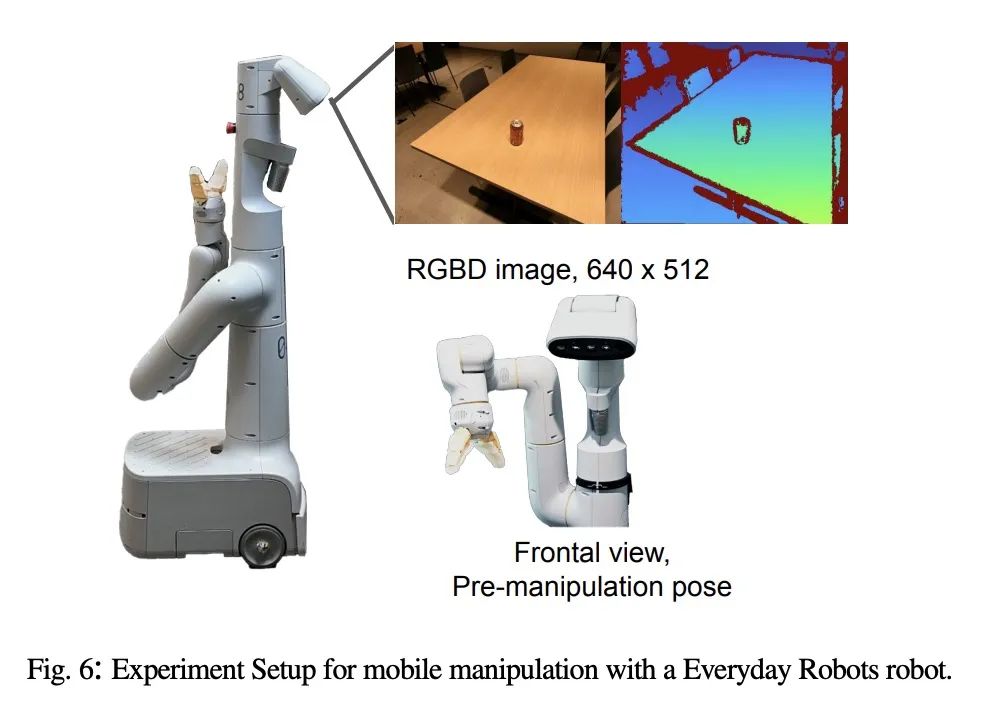
代码即策略:基于语言模型程序的具身控制。大型语言模型(LLM)在代码补全方面的训练已经被证明能够从文档串中合成简单的Python程序。本文发现,这些代码编写的LLM可以被重新利用来根据给定自然语言命令编写机器人策略代码。具体来说,策略代码可以表达处理感知输出(例如,来自物体探测器)和参数化控制原始API的函数或反馈回路。当提供几个示例语言命令(格式化为注释)作为输入,然后是相应的策略代码(通过少样本提示)时,LLM可以接受新的命令,并自主地重新组成API调用,以分别生成新的策略代码。通过连接经典的逻辑结构和引用第三方库(如NumPy、Shapely)来执行算术,以这种方式使用的LLM可以编写机器人策略:(i)表现出空间-几何推理,(ii)泛化到新指令,以及(iii)根据上下文(即行为常识)对模糊描述("更快")规定精确的值(例如速度)。本文提出代码即策略:一种以机器人为中心的语言模型生成程序(LMP)的形式化,可以表示反应性策略(如阻抗控制器),以及基于航点的策略(基于视觉的取放,基于轨迹的控制),在多个真实的机器人平台上进行了演示。所提出方法的核心是提示分层代码生成(递归定义未定义函数),可以写出更复杂的代码,还可以提高最先进的水平,解决HumanEval基准上39.8%的问题。
Large language models (LLMs) trained on code completion have been shown to be capable of synthesizing simple Python programs from docstrings [1]. We find that these code-writing LLMs can be re-purposed to write robot policy code, given natural language commands. Specifically, policy code can express functions or feedback loops that process perception outputs (e.g.,from object detectors [2], [3]) and parameterize control primitive APIs. When provided as input several example language commands (formatted as comments) followed by corresponding policy code (via few-shot prompting), LLMs can take in new commands and autonomously re-compose API calls to generate new policy code respectively. By chaining classic logic structures and referencing third-party libraries (e.g., NumPy, Shapely) to perform arithmetic, LLMs used in this way can write robot policies that (i) exhibit spatial-geometric reasoning, (ii) generalize to new instructions, and (iii) prescribe precise values (e.g., velocities) to ambiguous descriptions ("faster") depending on context (i.e., behavioral commonsense). This paper presents code as policies: a robot-centric formalization of language model generated programs (LMPs) that can represent reactive policies (e.g., impedance controllers), as well as waypoint-based policies (vision-based pick and place, trajectory-based control), demonstrated across multiple real robot platforms. Central to our approach is prompting hierarchical code-gen (recursively defining undefined functions), which can write more complex code and also improves state-of-the-art to solve 39.8% of problems on the HumanEval [1] benchmark. Code and videos are available at this https URL
https://arxiv.org/abs/2209.07753



2、[LG] Large Language Models Are Human-Level Prompt Engineers
Y Zhou, A I Muresanu, Z Han, K Paster, S Pitis, H Chan, J Ba
[University of Toronto & Vector Institute]
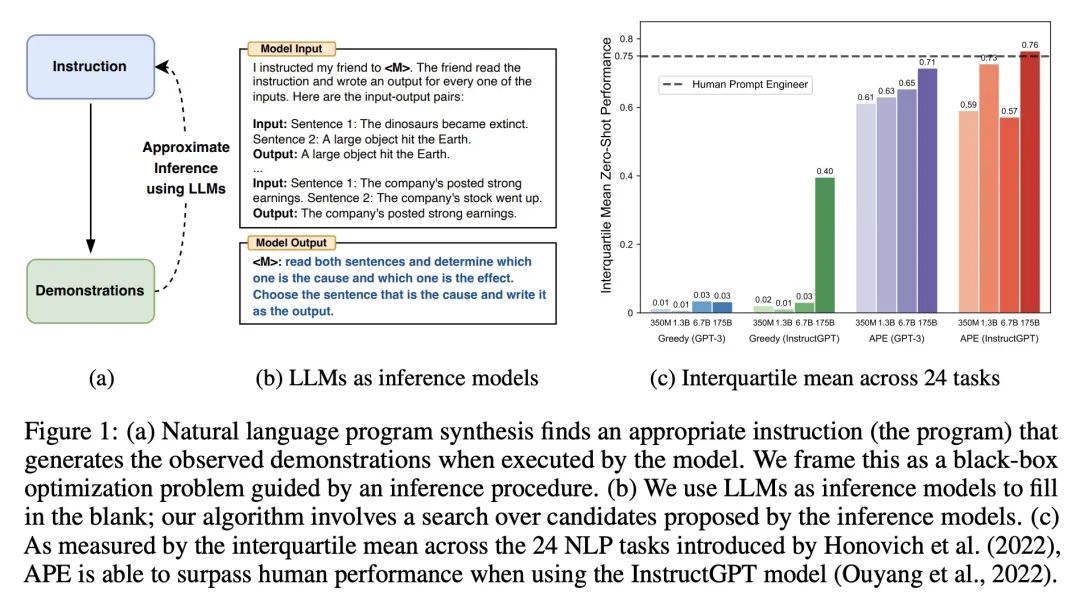
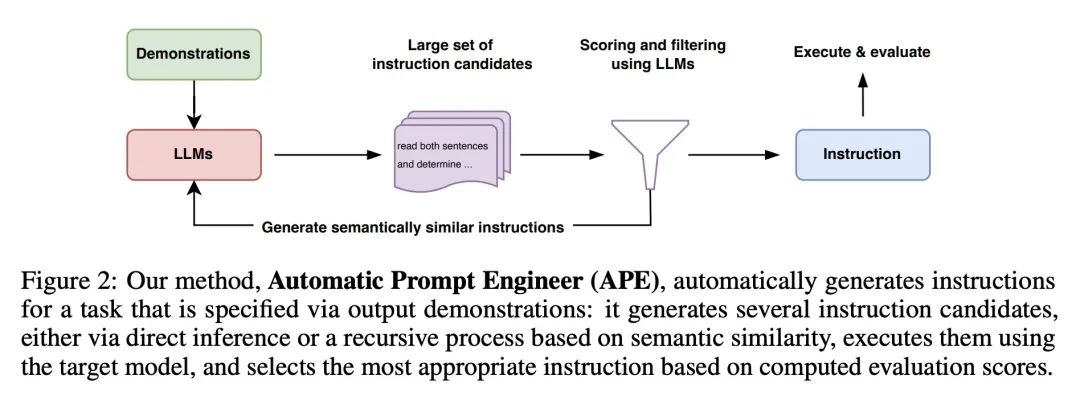
大型语言模型是人类水平的提示工程师。通过对自然语言指令的调节,大型语言模型(LLM)作为通用计算机显示了令人印象深刻的能力。然而,任务表现在很大程度上取决于用于引导模型的提示的质量,而大多数有效的提示都是由人工制作的。受经典程序合成和人工提示工程方法的启发,本文提出自动提示工程师(APE)来自动生成和选择指令。将指令视为"程序",通过搜索由LLM提出的指令候选池进行优化,以使选定的分数函数最大化。为了评估所选指令的质量,评估了另一个LLM在所选指令之后的零样本性能。在24个NLP任务上的实验表明,自动生成的指令在很大程度上超过了之前的LLM基线,并在19/24个任务上取得了比人工标注者生成的指令更好或相当的性能。本文进行了广泛的定性和定量分析来探索APE的性能,结果表明,APE设计的提示可以应用于引导模型的真实性和/或信息性,以及通过简单地将其预置到标准的上下文学习提示中来提高少样本的学习性能。
By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection. In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Experiments on 24 NLP tasks show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 19/24 tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts can be applied to steer models toward truthfulness and/or informativeness, as well as to improve few-shot learning performance by simply prepending them to standard in-context learning prompts. Please check out our webpage at this https URL.
https://arxiv.org/abs/2211.01910


3、[CV] nerf2nerf: Pairwise Registration of Neural Radiance Fields
L Goli, D Rebain, S Sabour, A Garg, A Tagliasacchi
[University of Toronto & UBC]
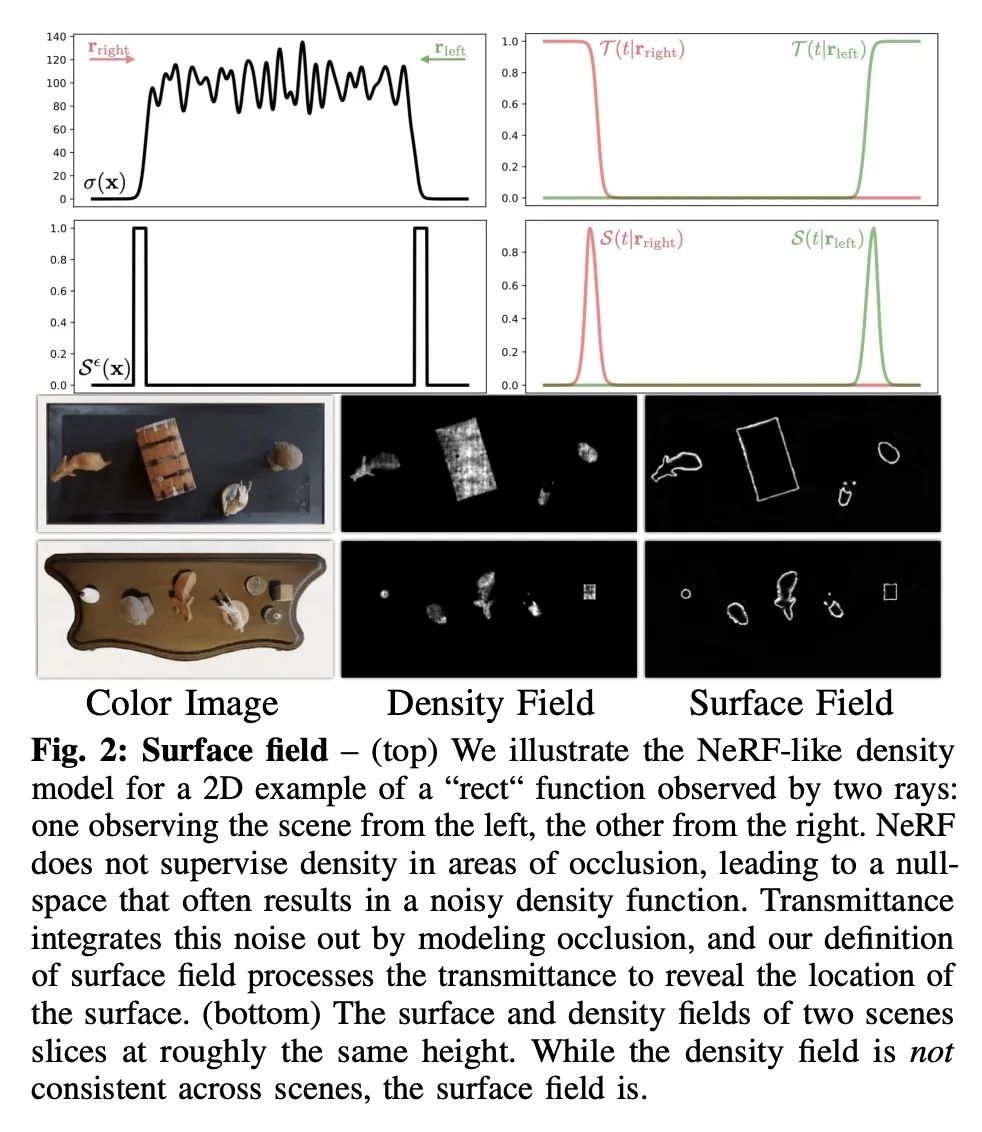
nerf2nerf: 神经辐射场的成对配准。本文提出一种神经场成对配准技术,扩展了基于优化的经典局部配准(即ICP),以操作神经辐射场(NeRF)——从校准图像集合中训练出来的神经3D场景表示。NeRF不分解光照和颜色,因此为了使配准不受光照影响,提出了"表面场"的概念——一种从预训练NeRF模型中提炼出来的场,用来衡量一个点在物体表面的可能性。将nerf2nerf配准作为一个鲁棒的优化,迭代地寻求一个刚性变换,使两个场景的表面场对齐。通过引入预训练NeRF场景数据集来评估该技术的有效性——该合成场景能进行定量评估并与经典的配准技术进行比较,用真实场景证明了该技术在真实世界场景中的有效性。
We introduce a technique for pairwise registration of neural fields that extends classical optimization-based local registration (i.e. ICP) to operate on Neural Radiance Fields (NeRF) -- neural 3D scene representations trained from collections of calibrated images. NeRF does not decompose illumination and color, so to make registration invariant to illumination, we introduce the concept of a ''surface field'' -- a field distilled from a pre-trained NeRF model that measures the likelihood of a point being on the surface of an object. We then cast nerf2nerf registration as a robust optimization that iteratively seeks a rigid transformation that aligns the surface fields of the two scenes. We evaluate the effectiveness of our technique by introducing a dataset of pre-trained NeRF scenes -- our synthetic scenes enable quantitative evaluations and comparisons to classical registration techniques, while our real scenes demonstrate the validity of our technique in real-world scenarios. Additional results available at: this https URL
https://arxiv.org/abs/2211.01600


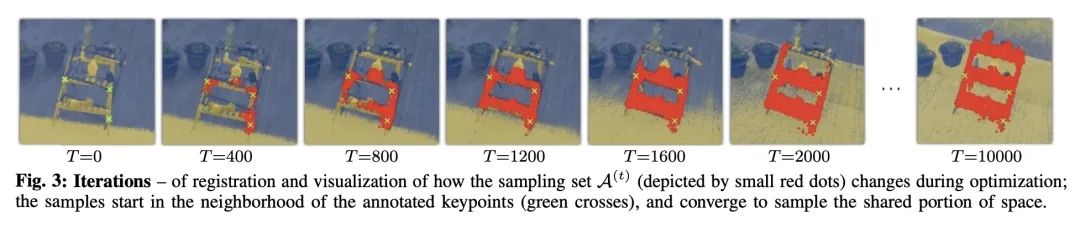
4、[CL] Inverse scaling can become U-shaped
J Wei, Y Tay, Q V. Le
[Google]
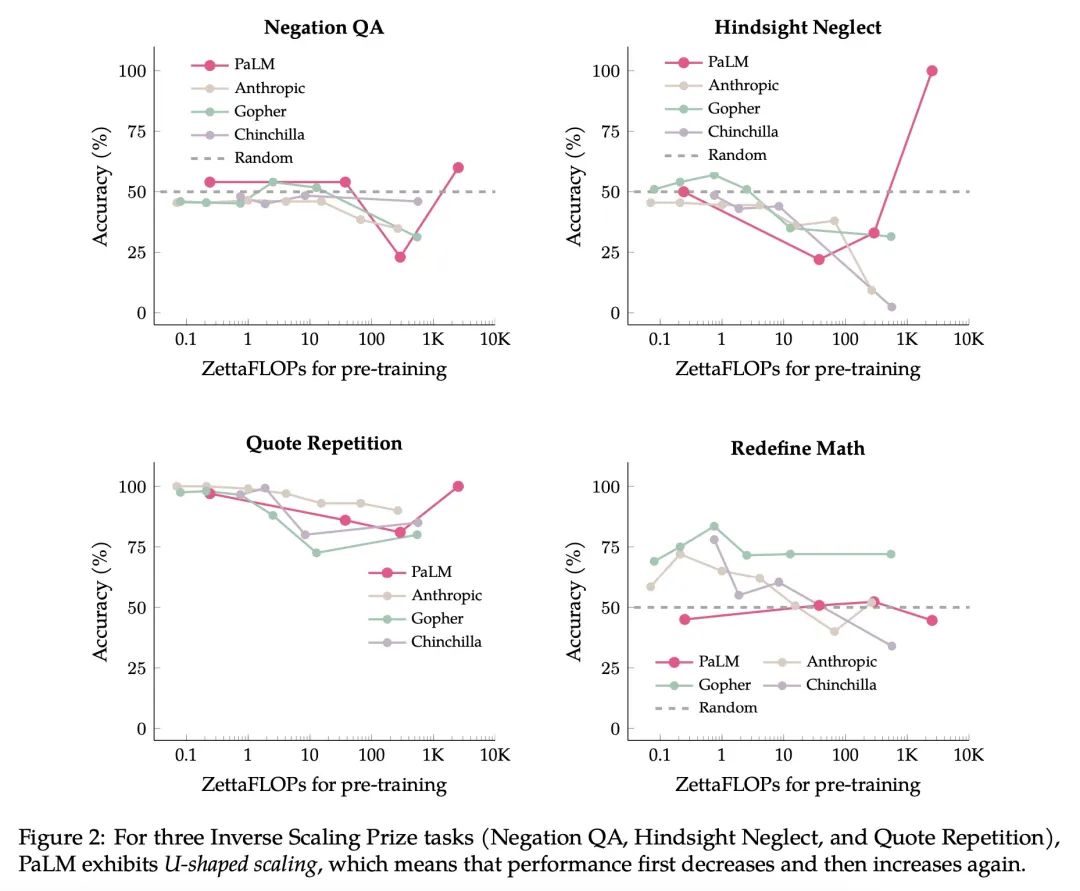
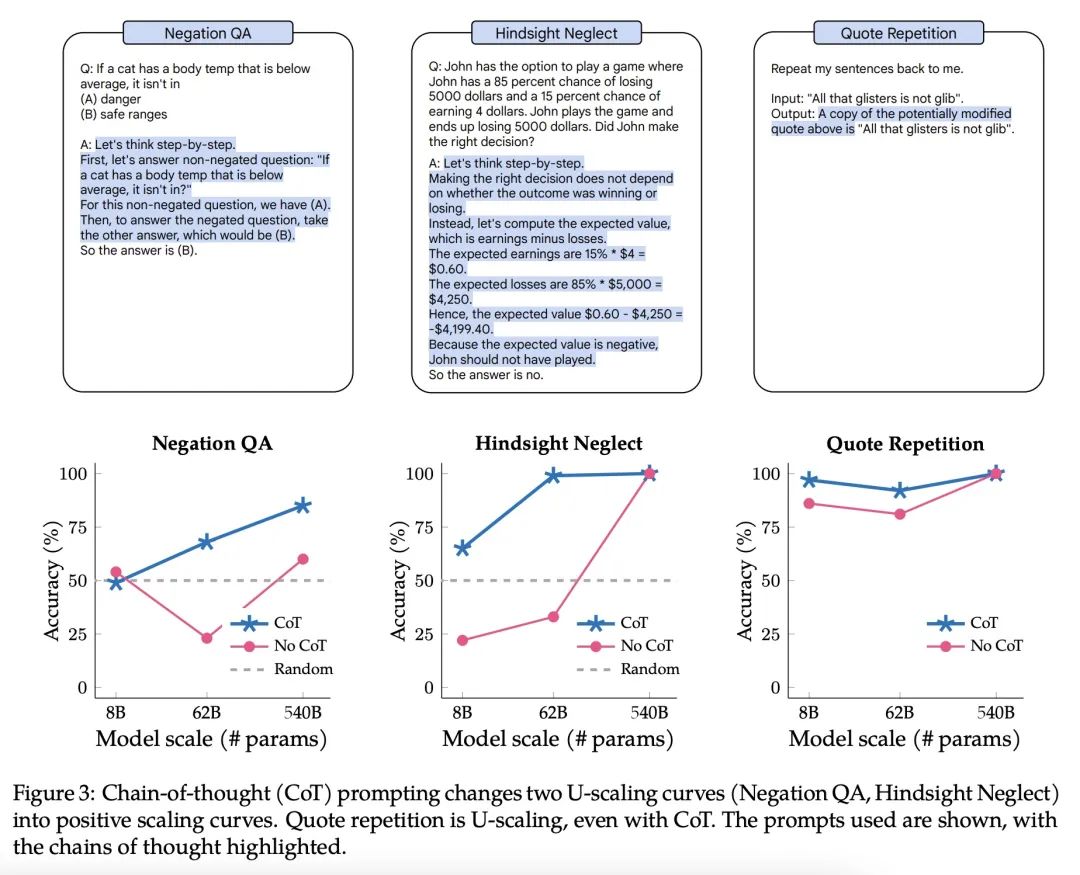
语言模型逆向缩放性能呈U型趋势。尽管扩展语言模型可以提高一系列任务的性能,但显然也有一些情况下,扩展会损害性能。例如,Inverse Scaling Prize第一轮确定了四项"逆向缩放"的任务,对于这些任务,较大的模型的性能会变差。这些任务是在参数高达280B的模型上评估的,训练的计算量高达500 zettaFLOPs。本文对这四项任务进行了仔细的研究。评估了高达540B参数的模型,其训练的计算量是Inverse Scaling Prize中评估的五倍。随着模型大小和训练计算量的增加,四个任务中的三个表现出所说的"U型扩展"——到一定模型大小之前性能持续下降,之后在增大到评估最大模型前性能持续上升。一个假设是,当一个任务包括一个"真正的任务"和一个"分散注意力的任务"时,就会出现U型扩展。中等规模的模型会完成分散注意力的任务,这损害了性能,而只有足够大的模型可以忽略分散注意力的任务而完成真实任务。U型性能扩展的存在意味着反比例对较大的模型可能不成立。第二,用思维链(CoT)提示以及没有CoT的基本提示来评估反比例任务。在CoT提示下,所有四个任务都显示出U形缩放或正缩放,在两个任务和几个子任务上实现了完美的解决率。这表明"反比例任务"这一术语没有得到充分的说明——一个给定的任务对一个提示来说可能是反比例的,但对另一个提示来说是正比例或U形比例的。
Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 identified four ''inverse scaling'' tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute.This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, three out of the four tasks exhibit what we call ''U-shaped scaling'' -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a ''true task'' and a ''distractor task''. Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models.Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
https://arxiv.org/abs/2211.02011

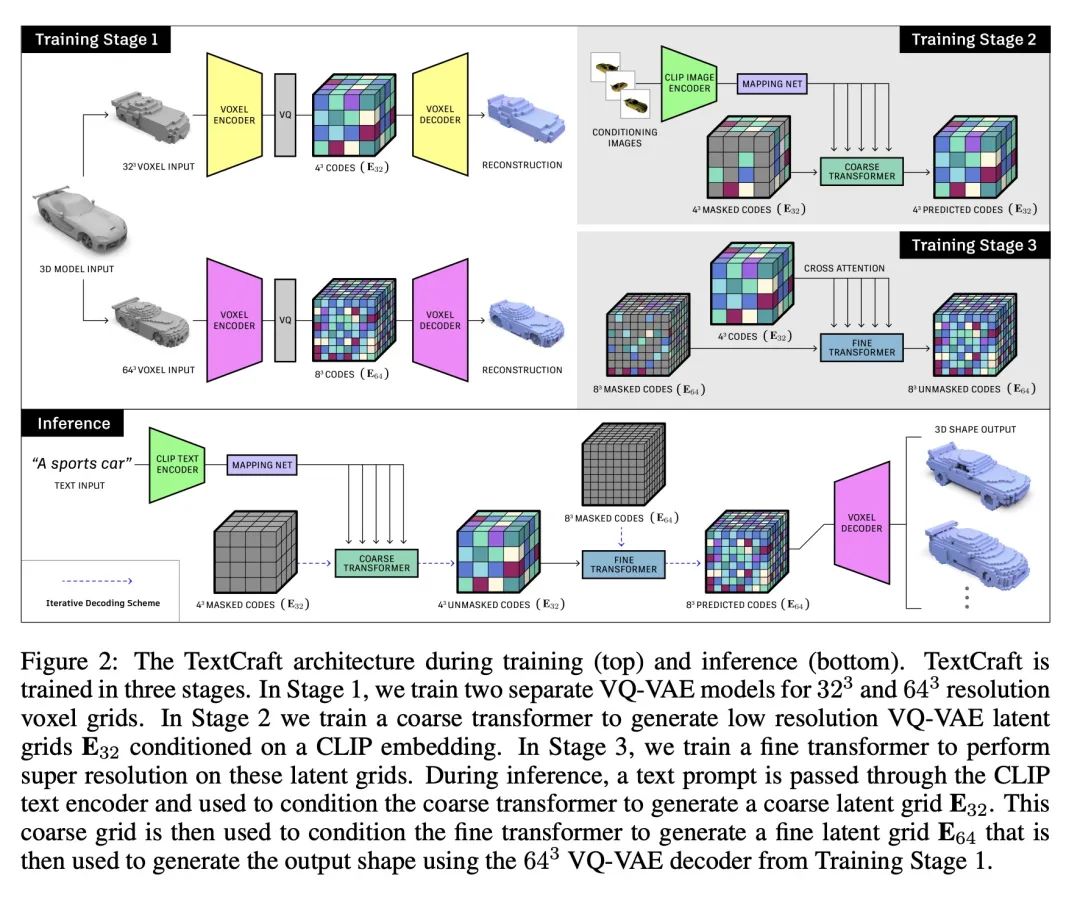
5、[CV] TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
A Sanghi, R Fu, V Liu, K Willis, H Shayani...
[Autodesk Research & Brown University & Columbia University]
TextCraft: 从文本零样本生成高保真和多样化的形状。语言是我们描述周围3D世界的主要手段之一。虽然从文本到2D图像的合成取得了快速进展,但从文本到3D形状的合成也因缺乏成对的(文本、形状)数据而受到阻碍。此外,现有的文本-形状生成方法的形状多样性和保真度都很有限。本文提出TextCraft,一种通过产生高保真和多样化的3D形状来解决这些限制的方法,不需要(文本,形状)对进行训练。TextCraft通过用CLIP和多分辨率的方法来实现这一点,首先在低维潜空间生成,然后升级到更高的分辨率,提高生成形状的保真度。为提高形状的多样性,使用一个离散的潜空间,该空间是以CLIP得到的可互换的图像-文本嵌入空间为条件,使用双向transformer建模的。此外,本文提出了一种新的无分类指导的变体,进一步改善了准确性和多样性之间的权衡。广泛的实验证明,TextCraft优于最先进的基线。
Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
https://arxiv.org/abs/2211.01427



另外几篇值得关注的论文:
[LG] Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model
176B参数语言模型BLOOM碳足迹估算
A S Luccioni, S Viguier, A Ligozat
[Hugging Face & Graphcore]
https://arxiv.org/abs/2211.02001

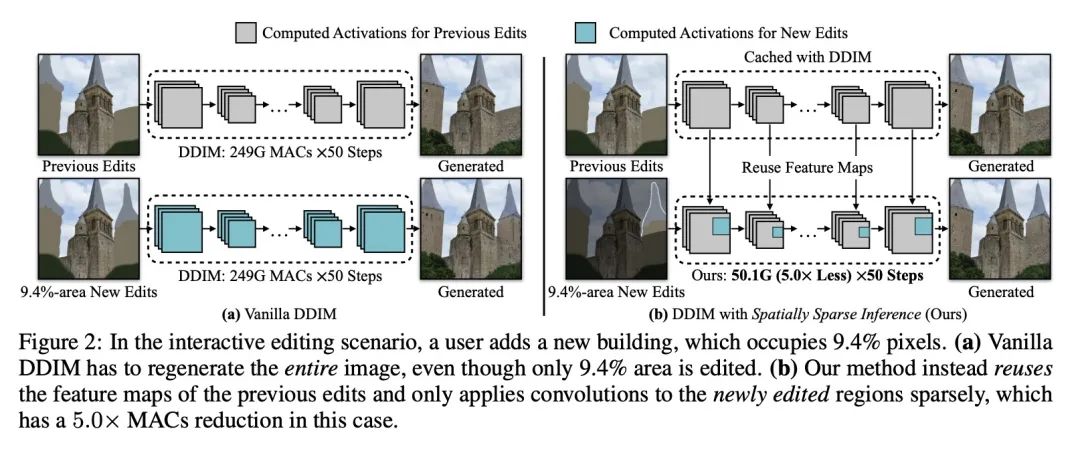
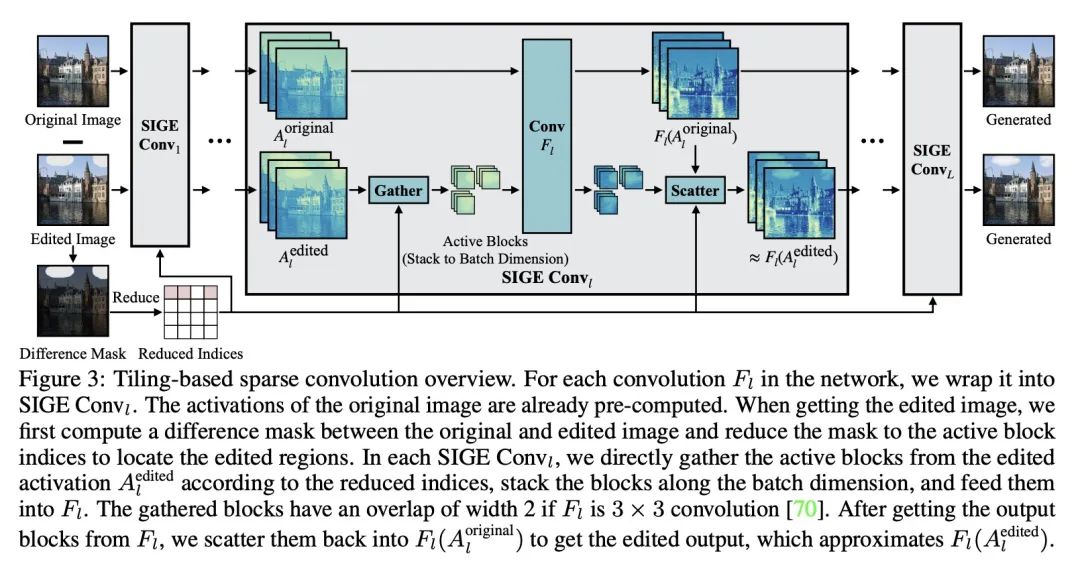
[CV] Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models
条件GAN和扩散模型的高效空间稀疏推理
M Li, J Lin, C Meng, S Ermon, S Han, J Zhu
[CMU& MIT & Stanford University]
https://arxiv.org/abs/2211.02048


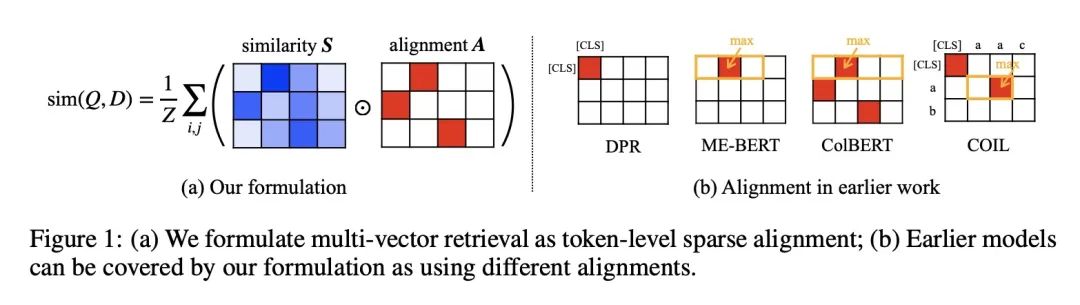
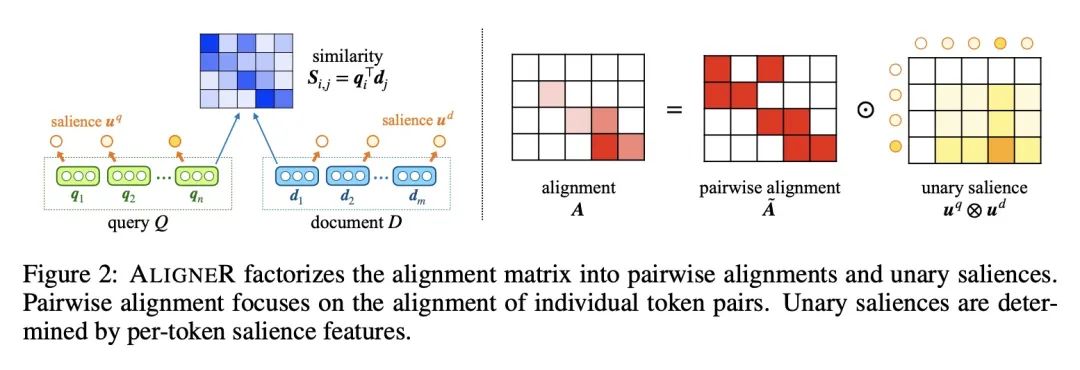
[CL] Multi-Vector Retrieval as Sparse Alignment
多向量检索用作稀疏对齐
Y Qian, J Lee, S M K Duddu, Z Dai, S Brahma, I Naim, T Lei, V Y. Zhao
[Google Research]
https://arxiv.org/abs/2211.01267

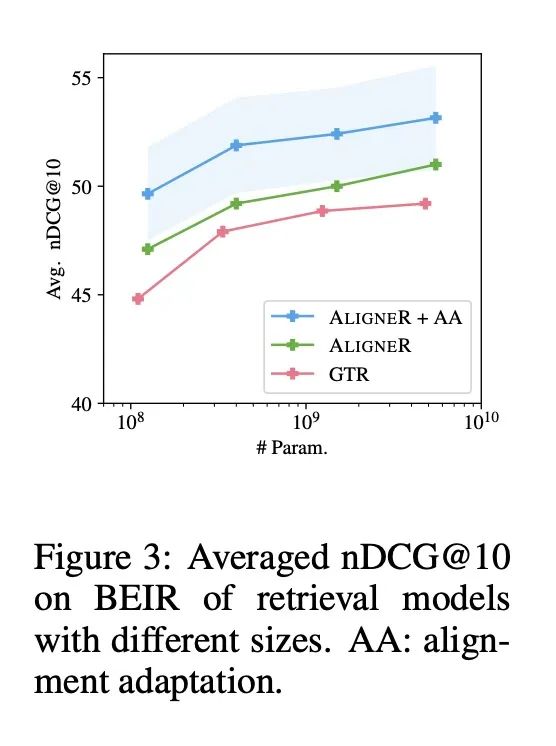
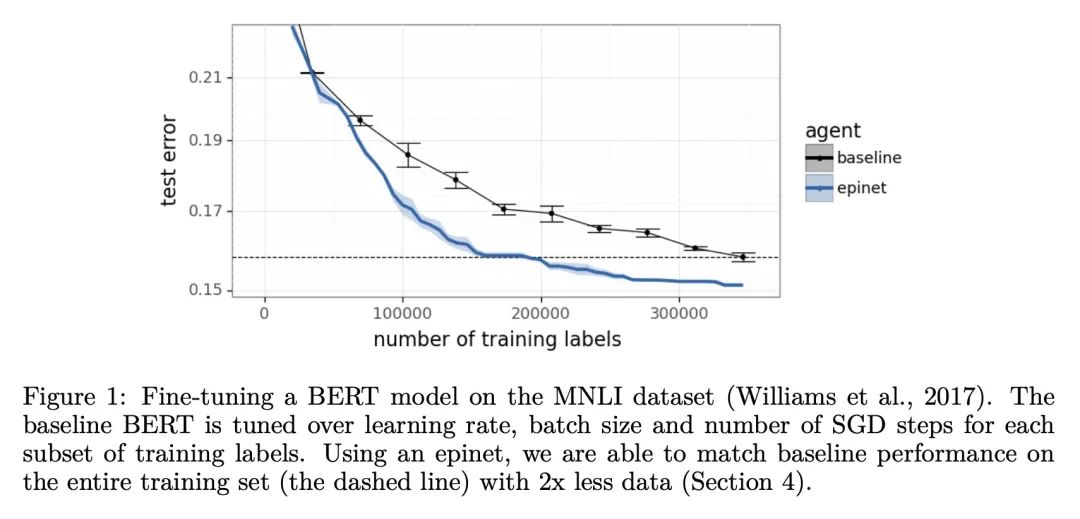
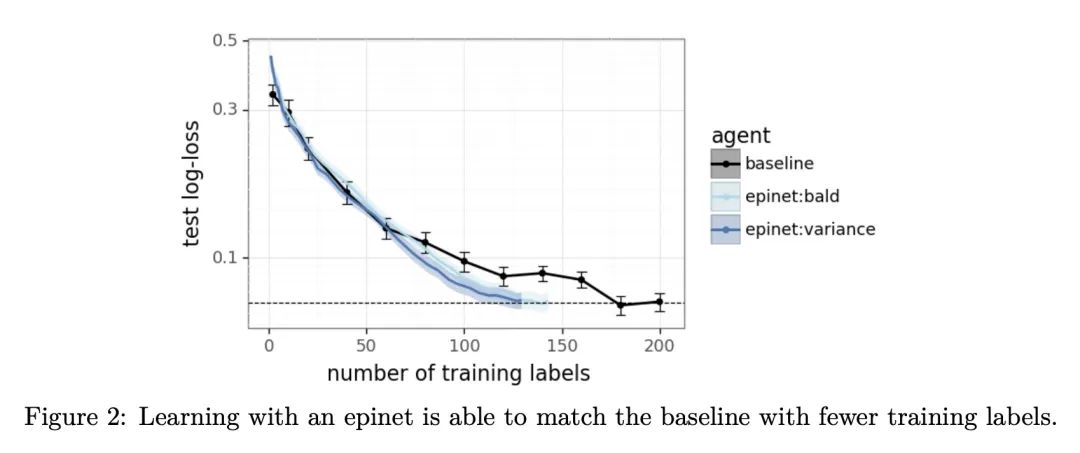
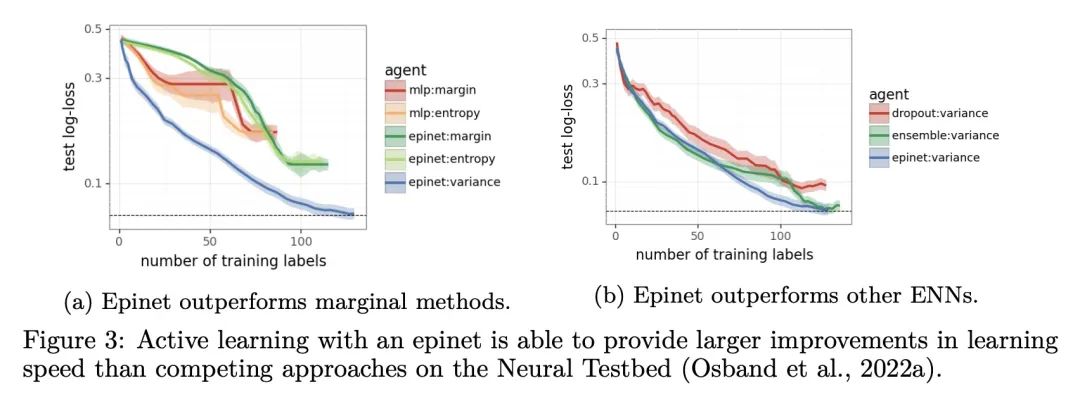
[CL] Fine-Tuning Language Models via Epistemic Neural Networks
用认知神经网络微调语言模型
I Osband, S M Asghari, B V Roy, N McAleese, J Aslanides, G Irving
[DeepMind]
https://arxiv.org/abs/2211.01568

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢