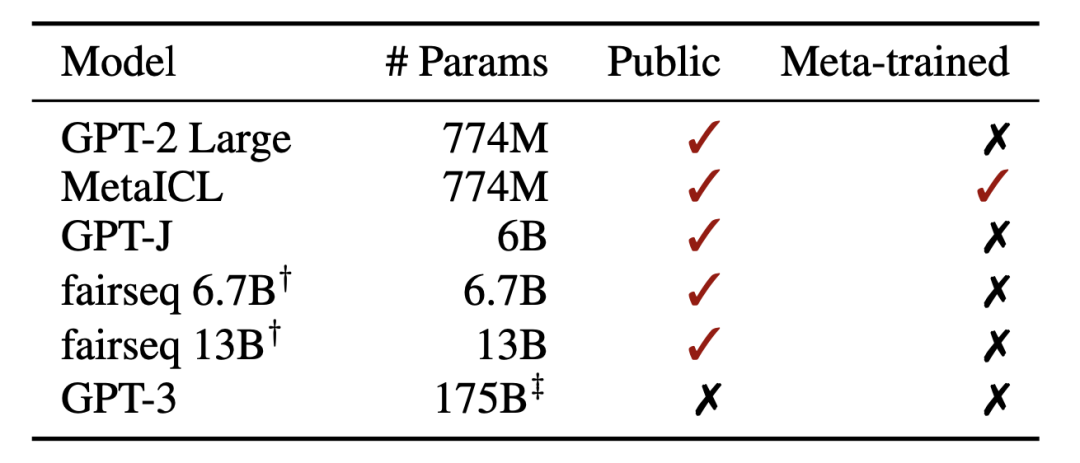
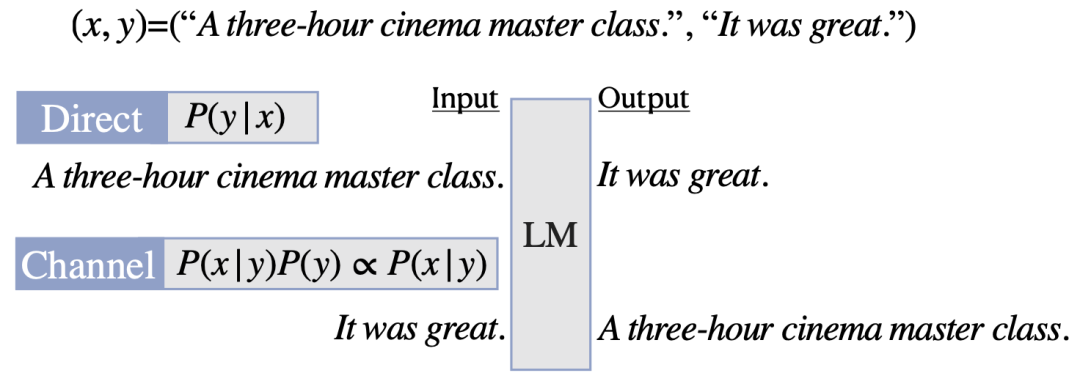
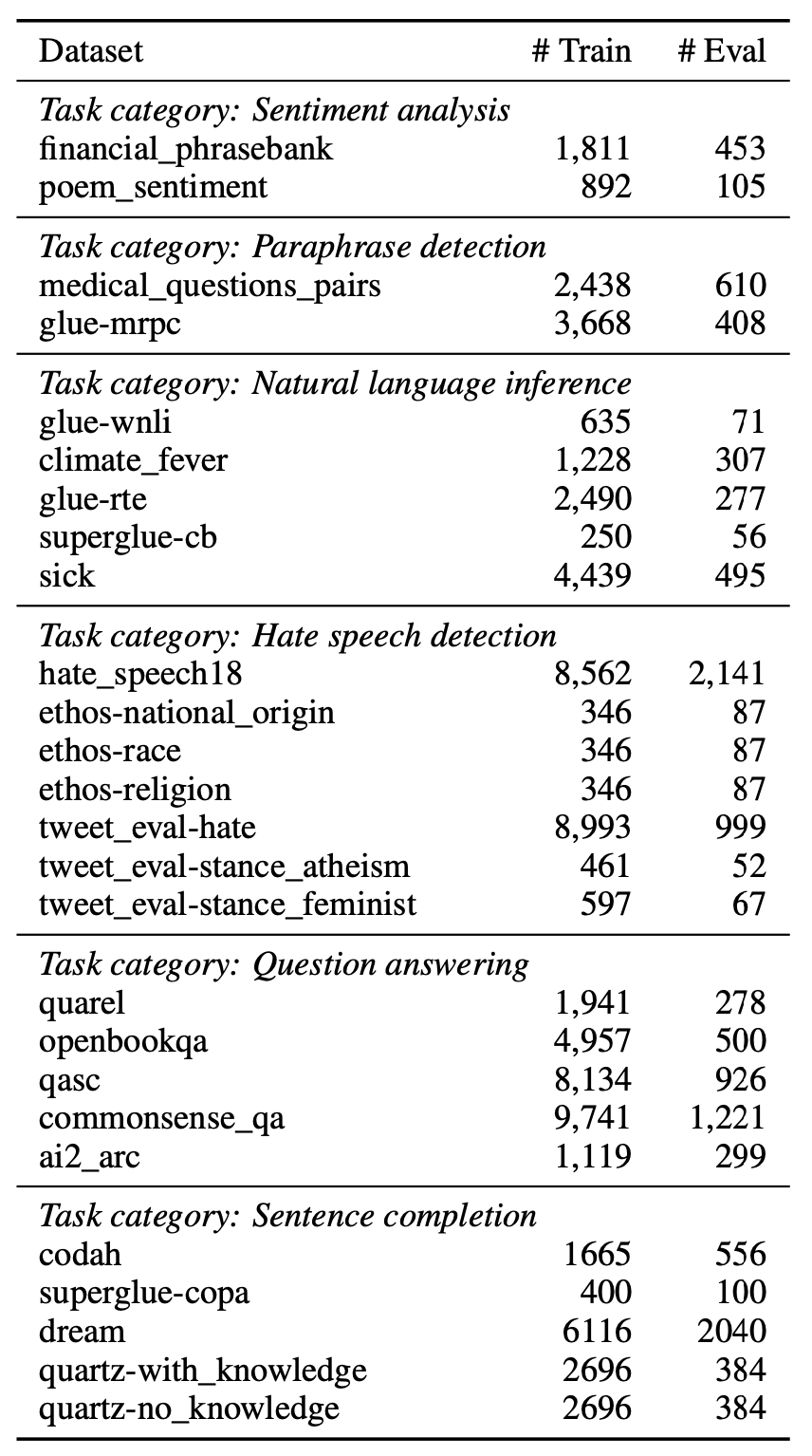
随着GPT-3等超大模型的兴起,in-context learning 的形式也流行起来。在in-context learning中,模型不根据下游任务调整参数,而是将下游任务的输入输出接起来之后作为prompt,引导模型根据测试集的输入生成预测结果。该方法的表现可以大幅超越零监督学习,并给大模型高效运用提供了新的思路。然而,in-context learning中,模型真的学习了下游任务么?作为prompt的训练样本,到底是如何让模型work的?本文作者发现,in-context learning学习的并不是输入与标注之间的关联,而是通过展示数据形式,来激活预训练模型的能力。此外还有两个附带的结论:(1)在meta learning的环境下,in-context learning的这一特点更为明显;(2)因为标签不重要,所以可以用无标注领域内数据做in-context zero shot learning。论文题目:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?论文链接:https://arxiv.org/abs/2202.12837项目地址:https://github.com/Alrope123/rethinking-demonstrations




评论
沙发等你来抢