
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:大型语言模型不是零样本交流器、基于多任务微调的跨语言泛化、用递归神经网络从神经测量中重构计算动力学、面向构成性文本到图像合成的免训练结构化扩散指导、基于截图解析的视觉语言理解预训练、视觉语言语意合成性失败调查、基于执行的自然语言到代码翻译、基于异构知识推理链的开放域问答、基于扩散模型解决音频逆问题
1、[CL] Large language models are not zero-shot communicators
L Ruis, A Khan, S Biderman, S Hooker, T Rocktäschel, E Grefenstette
[University College London & EleutherAI & Cohere for AI]
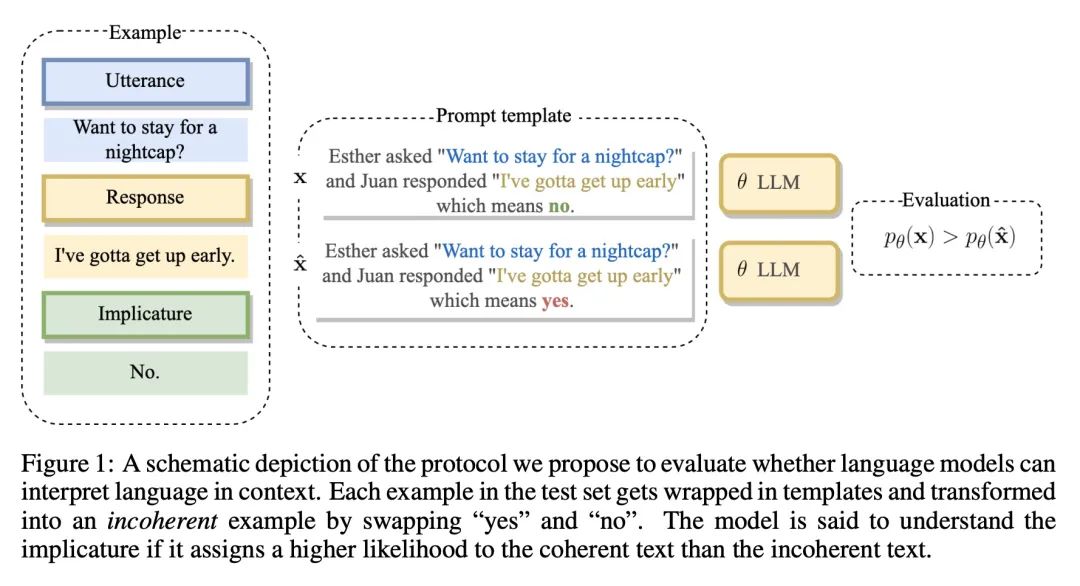
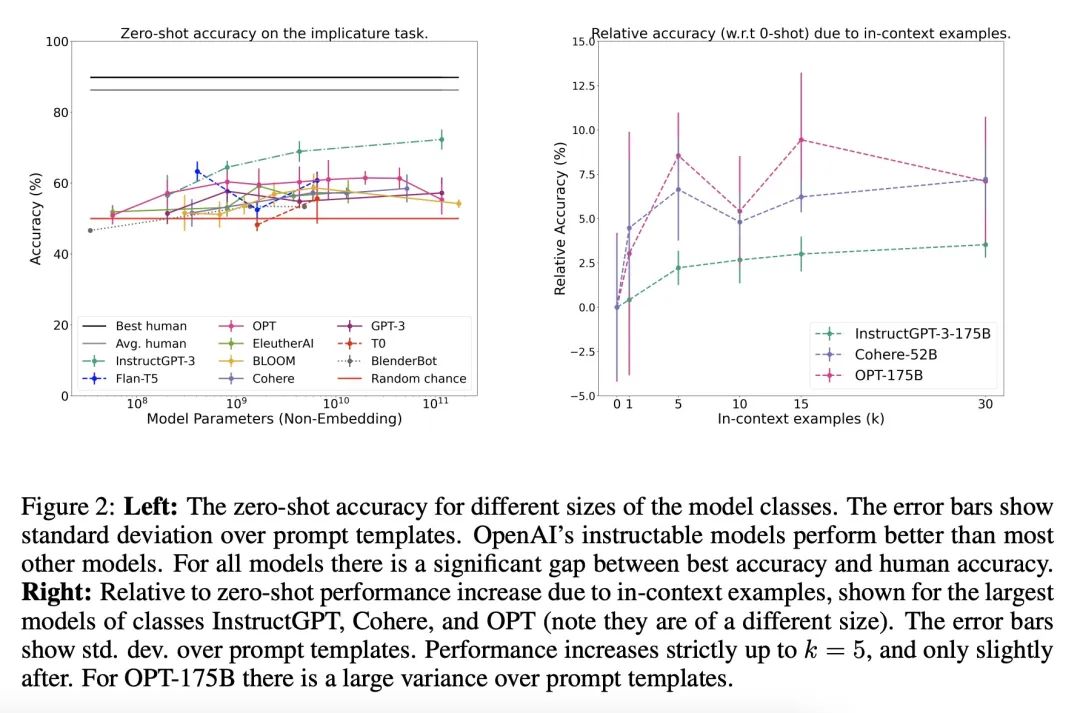
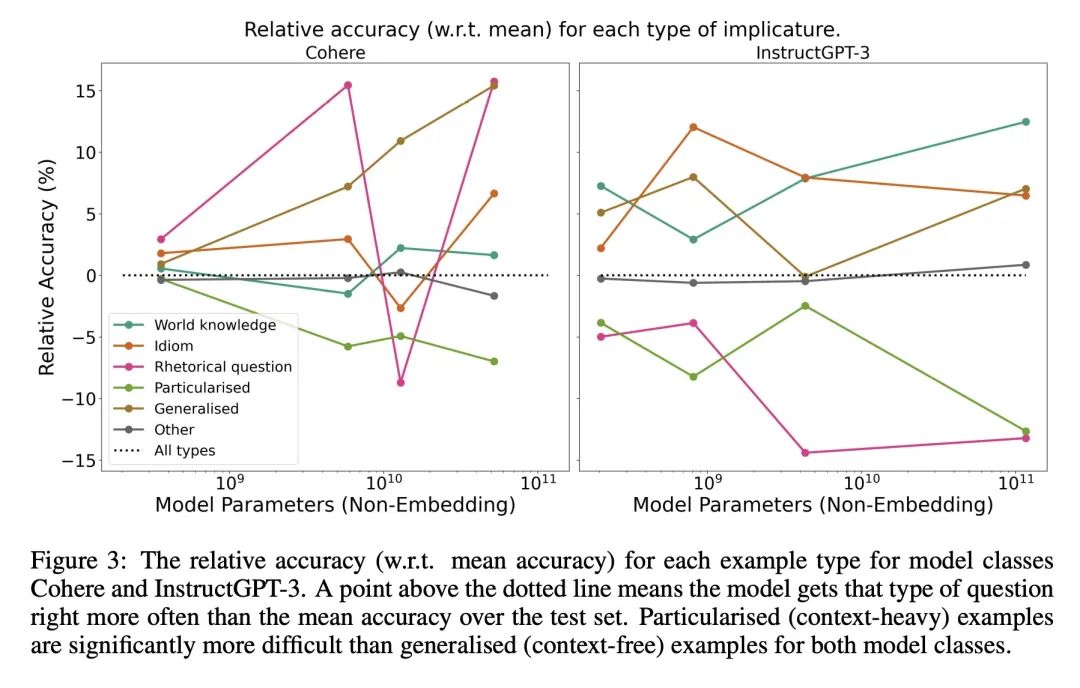
大型语言模型不是零样本交流器。尽管广泛使用大型语言模型作为对话智能体,但对性能的评估未能抓住交流的一个关键方面:在上下文中解释语言。人利用对世界的信念和已有知识来解释语言。例如,对于 "你有没有留下指纹?"这个问题,我们直观地理解为"我戴了手套"的回答是"没有"。为了研究LLM是否有能力进行这种类型的推理,即所谓的暗示,本文设计了一个简单的任务,并对广泛使用的最先进的模型进行了评估。结果发现,尽管只对需要二元推理(是或不是)的语料进行评估,但大多数的表现都接近随机。被调整为"与人意图对齐"的模型的表现要好得多,但仍然显示出与人类表现的巨大差距。本文将该发现作为进一步研究的起点,以评估LLM在上下文中如何解释语言,并推动人类话语的更务实和有用的模型的发展。
Despite widespread use of LLMs as conversational agents, evaluations of performance fail to capture a crucial aspect of communication: interpreting language in context. Humans interpret language using beliefs and prior knowledge about the world. For example, we intuitively understand the response "I wore gloves" to the question "Did you leave fingerprints?" as meaning "No". To investigate whether LLMs have the ability to make this type of inference, known as an implicature, we design a simple task and evaluate widely used state-of-the-art models. We find that, despite only evaluating on utterances that require a binary inference (yes or no), most perform close to random. Models adapted to be "aligned with human intent" perform much better, but still show a significant gap with human performance. We present our findings as the starting point for further research into evaluating how LLMs interpret language in context and to drive the development of more pragmatic and useful models of human discourse.
https://arxiv.org/abs/2210.14986

2、[CL] Crosslingual Generalization through Multitask Finetuning
N Muennighoff, T Wang, L Sutawika, A Roberts, S Biderman, T L Scao...
[Hugging Face & Datasaur.ai & EleutherAI & Google Research...]
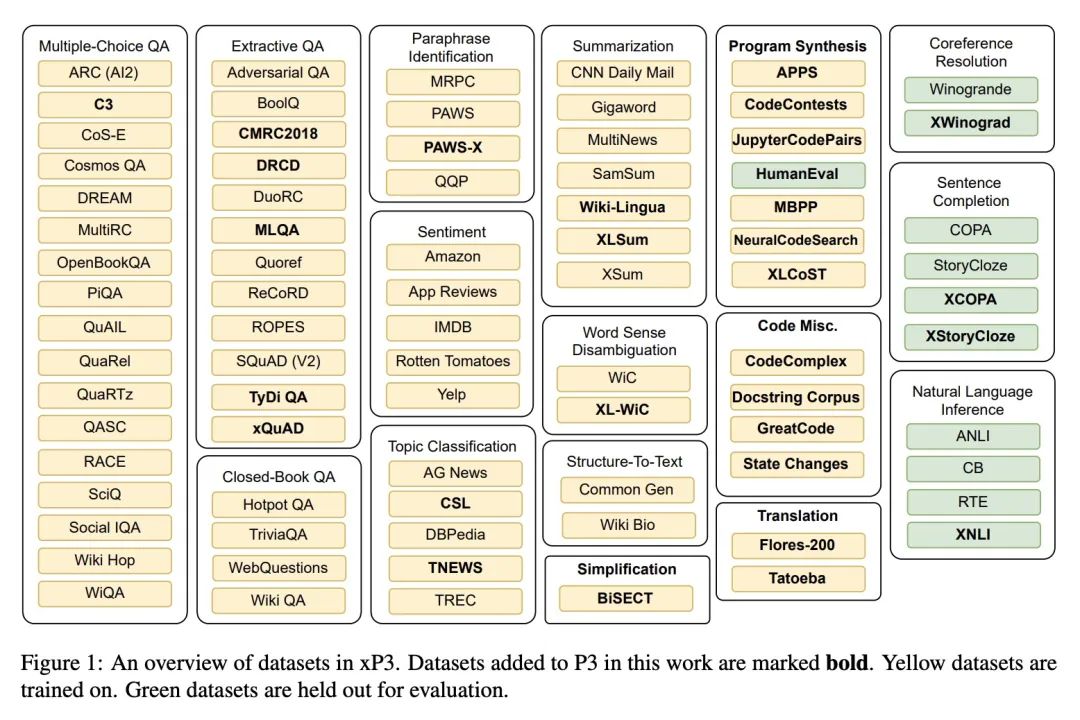
基于多任务微调的跨语言泛化。多任务提示微调(MTF)已被证明可以帮助大型语言模型在零样本设置中泛化到新任务,但迄今为止,MTF的探索主要集中在英语数据和模型上。本文将MTF应用于预训练的多语言BLOOM和mT5模型系列,以产生称为BLOOMZ和mT0的微调变体。本文发现,在英语任务中对带有英语提示的大型多语种语言模型进行微调,可以将任务泛化到只出现在预训练语料库中的非英语语言。在有英语提示的多语言任务上进行微调,可以进一步提高英语和非英语任务的性能,从而获得各种最先进的零样本结果。本文还研究了在多语言任务中对提示语的微调,这些提示语是由机器从英语翻译过来的,以符合每个数据集的语言。本文发现在这些机器翻译的提示语上进行训练,可以在相应语言的人写的提示语上获得更好的表现。令人惊讶的是,模型能对它们从未有意见过的语言的任务实现零样本的泛化。本文猜测,这些模型正在学习与任务和语言无关的更高层次的能力。此外,本文还提出xP3,一个由46种语言的监督数据集与英语和机器翻译的提示语组成的合成数据集。
Multitask prompted finetuning (MTF) has been shown to help large language models generalize to new tasks in a zero-shot setting, but so far explorations of MTF have focused on English data and models. We apply MTF to the pretrained multilingual BLOOM and mT5 model families to produce finetuned variants called BLOOMZ and mT0. We find finetuning large multilingual language models on English tasks with English prompts allows for task generalization to non-English languages that appear only in the pretraining corpus. Finetuning on multilingual tasks with English prompts further improves performance on English and non-English tasks leading to various state-of-the-art zero-shot results. We also investigate finetuning on multilingual tasks with prompts that have been machine-translated from English to match the language of each dataset. We find training on these machine-translated prompts leads to better performance on human-written prompts in the respective languages. Surprisingly, we find models are capable of zero-shot generalization to tasks in languages they have never intentionally seen. We conjecture that the models are learning higher-level capabilities that are both task- and language-agnostic. In addition, we introduce xP3, a composite of supervised datasets in 46 languages with English and machine-translated prompts. Our code, datasets and models are publicly available at this https URL.
https://arxiv.org/abs/2211.01786


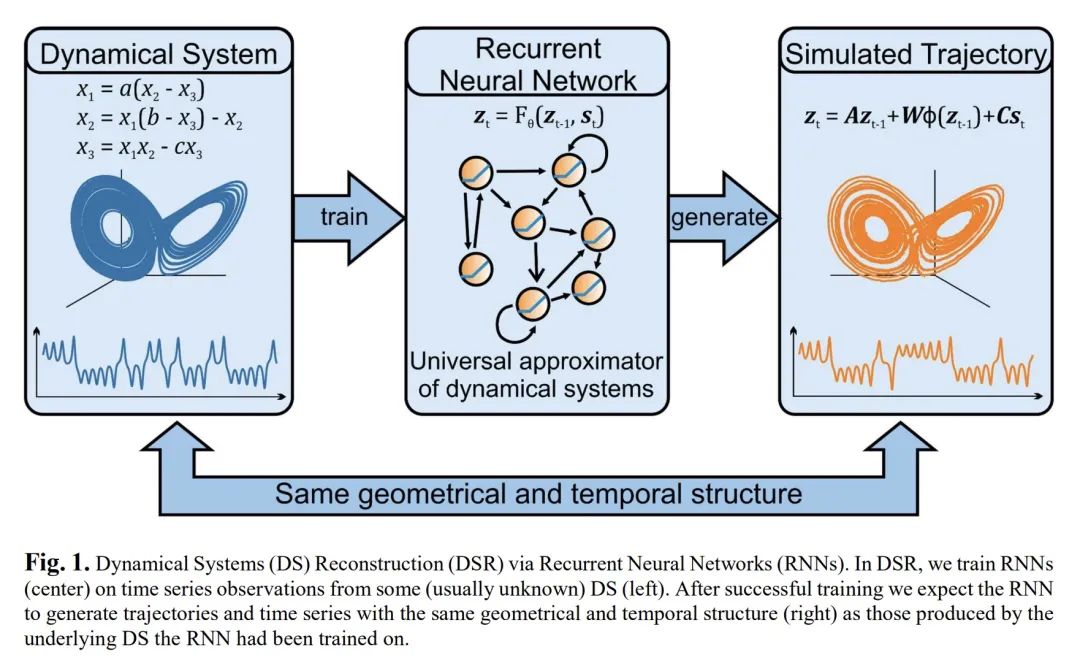
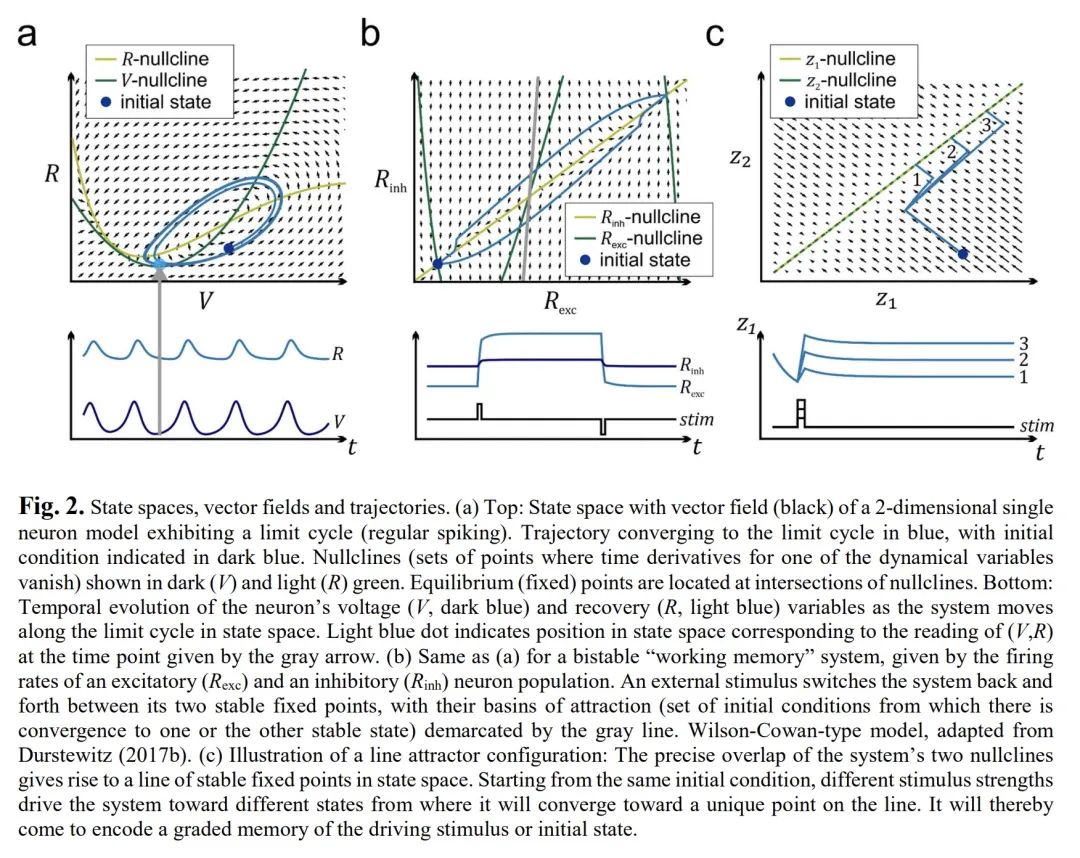
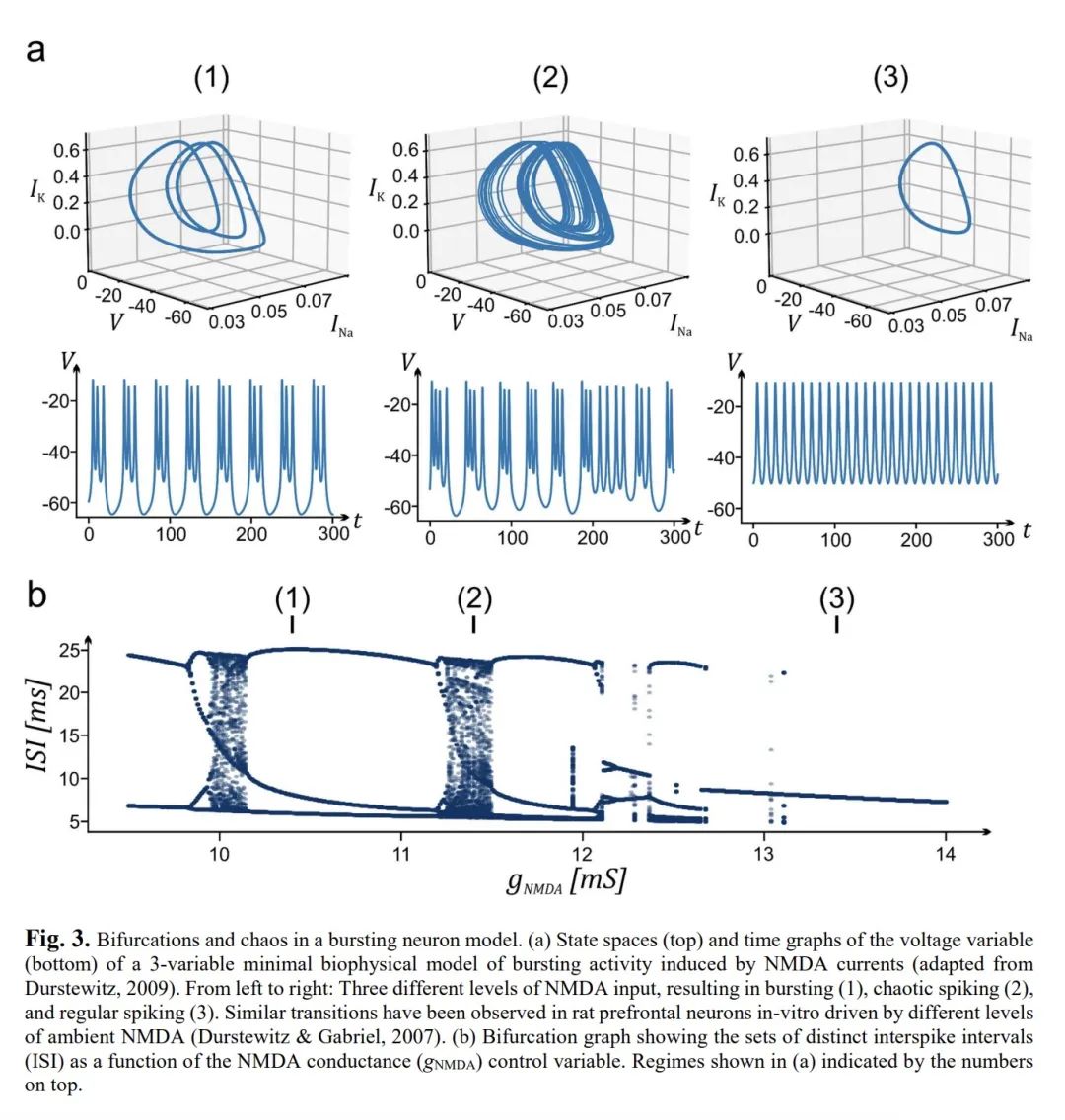
3、[LG] Reconstructing Computational Dynamics from Neural Measurements with Recurrent Neural Networks
D Durstewitz, G Koppe, M I Thurm
[Heidelberg University]
用递归神经网络从神经测量中重构计算动力学。神经科学的机制和计算模型通常采取微分或时间递归方程系统的形式。此类系统的时空行为是动态系统理论(DST)的主题。DST为描述和分析从分子到行为的任何层次的神经生物学过程提供了一个强大的数学工具箱,几十年来一直是计算神经科学的支柱。最近,递归神经网络(RNN)成为研究神经或行为观察背后的非线性动力学的流行机器学习工具。通过训练RNN完成与动物科目相同的行为任务并剖析其内部运作,可以产生关于行为的神经-计算基础的见解和假设。另外,RNN可以直接在既有的生理和行为时间序列上进行训练。理想情况下,一旦训练好的RNN将能够产生与观察到的数据具有相同的时间和几何属性。这被称为动态系统重建,是机器学习和非线性动力学的一个新兴领域。通过这种更强大的方法,就其动态和计算特性而言,训练的RNN成为实验探测系统的代用品。然后,训练后的系统可以被系统地分析、探测和仿真。本文将回顾这个非常令人激动和迅速扩展的领域,包括机器学习的最新趋势,这些趋势在神经科学中可能还不太为人所知。本文还将讨论基于RNN动态系统重建的重要验证测试、注意事项和要求。概念和应用将用神经科学的各种例子来说明。
Mechanistic and computational models in neuroscience usually take the form of systems of differential or time-recursive equations. The spatio-temporal behavior of such systems is the subject of dynamical systems theory (DST). DST provides a powerful mathematical toolbox for describing and analyzing neurobiological processes at any level, from molecules to behavior, and has been a mainstay of computational neuroscience for decades. Recently, recurrent neural networks (RNNs) became a popular machine learning tool for studying the nonlinear dynamics underlying neural or behavioral observations. By training RNNs on the same behavioral tasks as employed for animal subjects and dissecting their inner workings, insights and hypotheses about the neuro-computational underpinnings of behavior could be generated. Alternatively, RNNs may be trained directly on the physiological and behavioral time series at hand. Ideally, the once trained RNN would then be able to generate data with the same temporal and geometrical properties as those observed. This is called dynamical systems reconstruction, a burgeoning field in machine learning and nonlinear dynamics. Through this more powerful approach the trained RNN becomes a surrogate for the experimentally probed system, as far as its dynamical and computational properties are concerned. The trained system can then be systematically analyzed, probed and simulated. Here we will review this highly exciting and rapidly expanding field, including recent trends in machine learning that may as yet be less well known in neuroscience. We will also discuss important validation tests, caveats, and requirements of RNN-based dynamical systems reconstruction. Concepts and applications will be illustrated with various examples from neuroscience.
https://biorxiv.org/content/10.1101/2022.10.31.514408v1

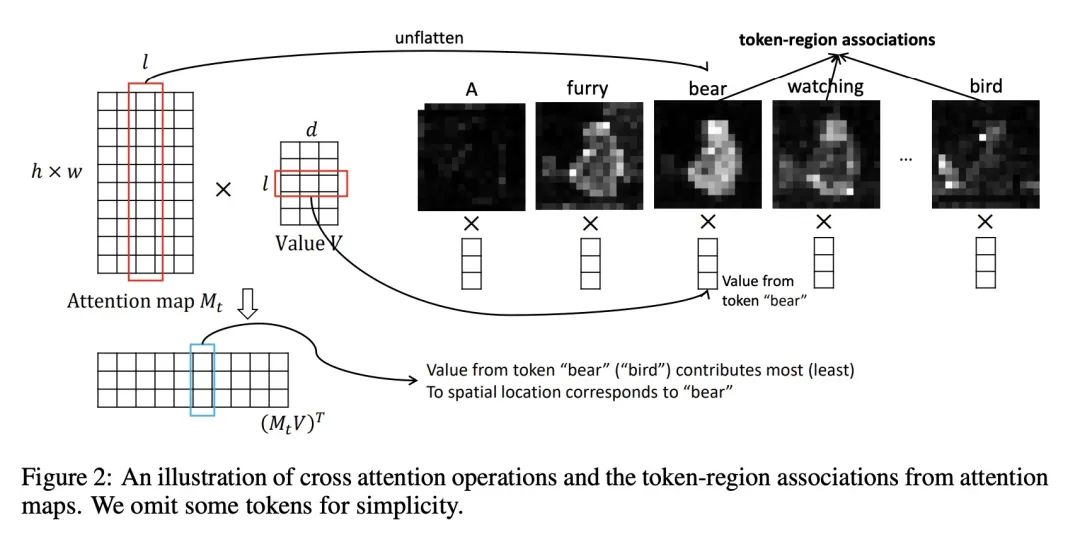
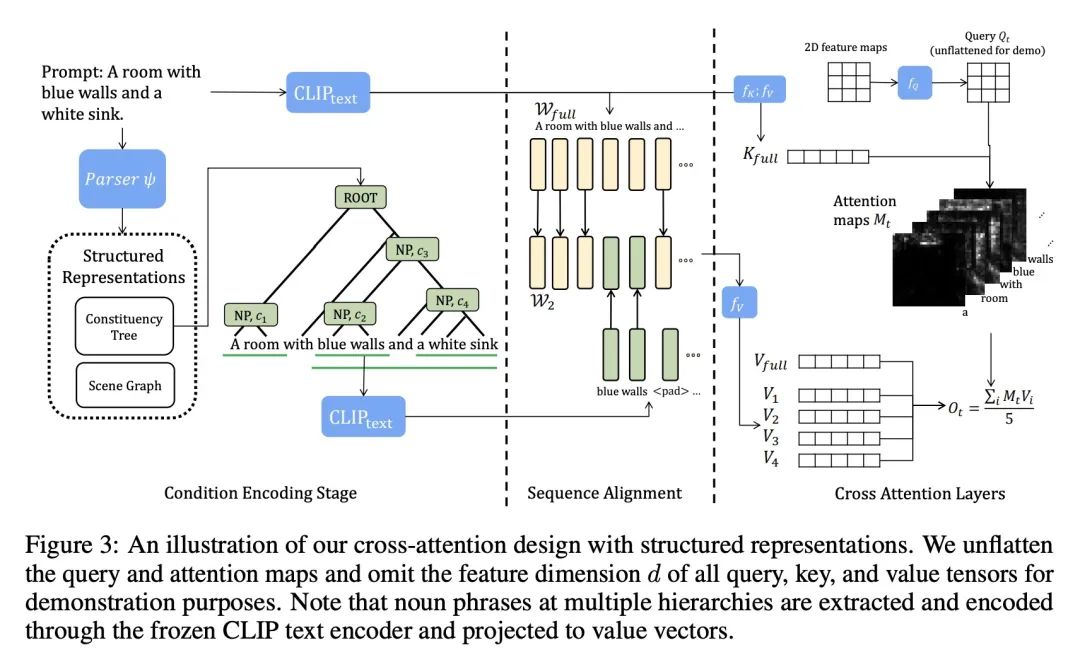
4、[LG] Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
面向构成性文本到图像合成的免训练结构化扩散指导。大规模扩散模型在文本到图像合成(T2I)方面表现出了卓越的性能。尽管其有能力生成高质量和创造性的图像,但用户仍然观察到与文本输入不一致的图像,特别是在涉及多个对象时。本文努力提高现有大规模T2I模型的合成技能,特别是更准确的属性绑定和更好的图像合成。本文提议根据最近发现的基于扩散的T2I模型的特性,将语言结构与交叉注意力层结合起来。所提出方法在一个最先进的模型——Stable Diffusion模型上实现,并在定性和定量结果中实现了更好的合成技能。所提出的结构化交叉注意力设计也很高效,不需要额外的训练样本。本文进行了深入的分析,揭示了不正确的图像合成的潜在原因,并证明了生成过程中交叉注意力层的特性。
Large-scale diffusion models have demonstrated remarkable performance on text-to-image synthesis (T2I). Despite their ability to generate high-quality and creative images, users still observe images that do not align well with the text input, especially when involving multiple objects. In this work, we strive to improve the compositional skills of existing large-scale T2I models, specifically more accurate attribute binding and better image compositions. We propose to incorporate language structures with the cross-attention layers based on a recently discovered property of diffusion-based T2I models. Our method is implemented on a state-of-the-art model, Stable Diffusion, and achieves better compositional skills in both qualitative and quantitative results. Our structured cross-attention design is also efficient that requires no additional training samples. Lastly, we conduct an in-depth analysis to reveal potential causes of incorrect image compositions and justify the properties of cross-attention layers in the generation process.
https://openreview.net/forum?id=PUIqjT4rzq7


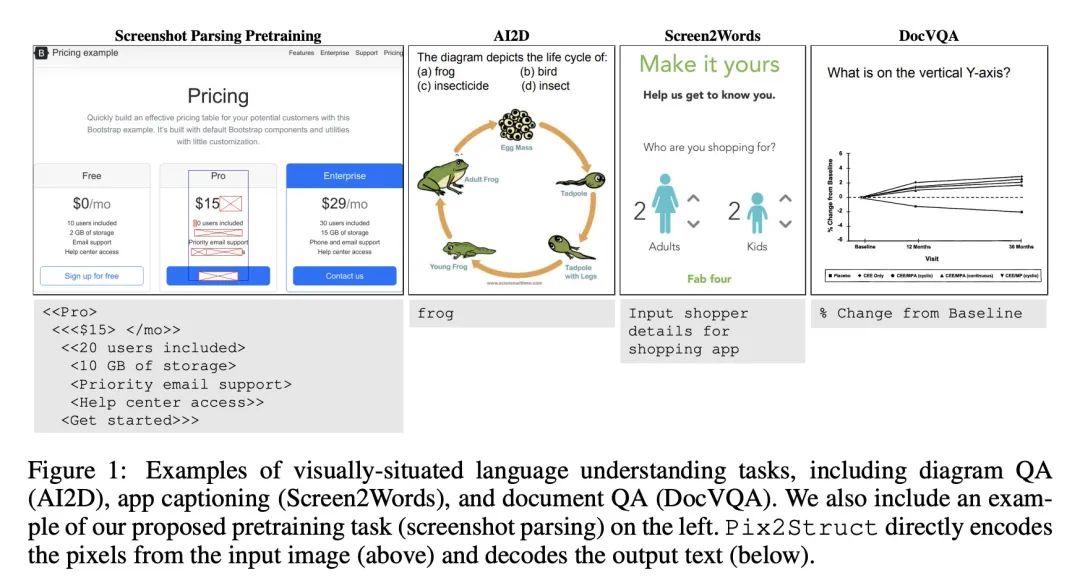
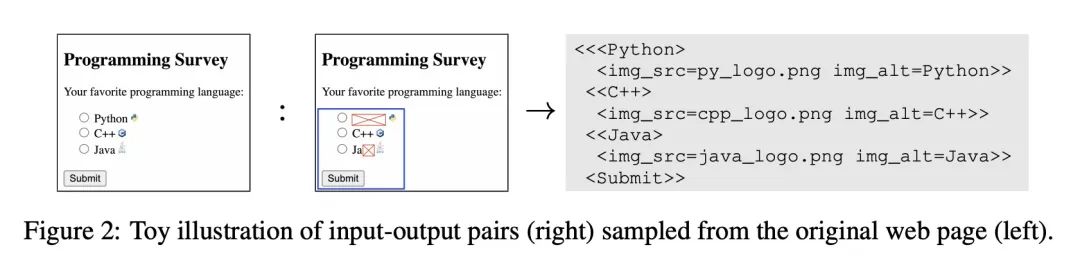
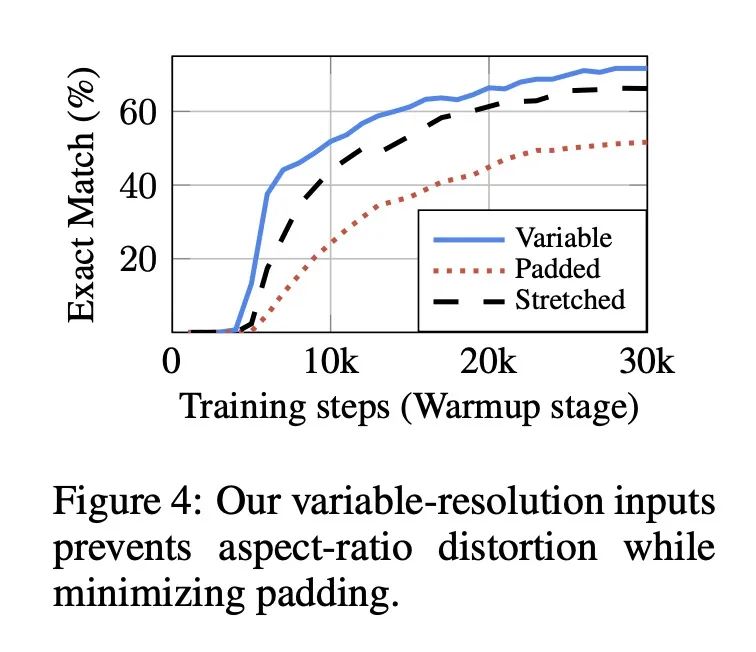
5、[LG] Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Pix2Struct: 基于截图解析的视觉语言理解预训练。视觉语言无处不在——来源包括从带有图表的教科书到带有图像和表格的网页,再到带有按钮和表格的移动应用。也许是由于这种多样性,之前的工作通常依赖于特定领域的方案,对基础数据、模型架构和目标的共享有限。本文提出Pix2Struct,一种用于纯视觉语言理解的预训练图像-文本模型,可以在包含视觉语言的任务中进行微调。Pix2Struct通过学习将网页的掩码截图解析为简化的HTML来进行预训练的。网络具有丰富的视觉元素,可以清晰地反映在HTML结构中,它提供了大量的预训练数据,非常适合于下游任务的多样性。直观地说,该目标包含了常见的预训练信号,如OCR、语言建模、图像说明。除了新颖的预训练策略外,本文还提出一种可变分辨率的输入表示法和一种更灵活的语言和视觉输入整合,其中语言提示,如问题,直接呈现在输入图像之上。本文首次表明,单个预训练模型可以在四个领域的九个任务中的六个任务中取得最先进的结果:文档、插图、用户界面和自然图像。
Visually-situated language is ubiquitous---sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
https://openreview.net/forum?id=UERcQuXlwy

另外几篇值得关注的论文:
[CL] Why is Winoground Hard? Investigating Failures in Visuolinguistic Compositionality
为什么Winoground很难?视觉语言语意合成性失败调查
A Diwan, L Berry, E Choi, D Harwath, K Mahowald
[The University of Texas at Austin]
https://arxiv.org/abs/2211.00768



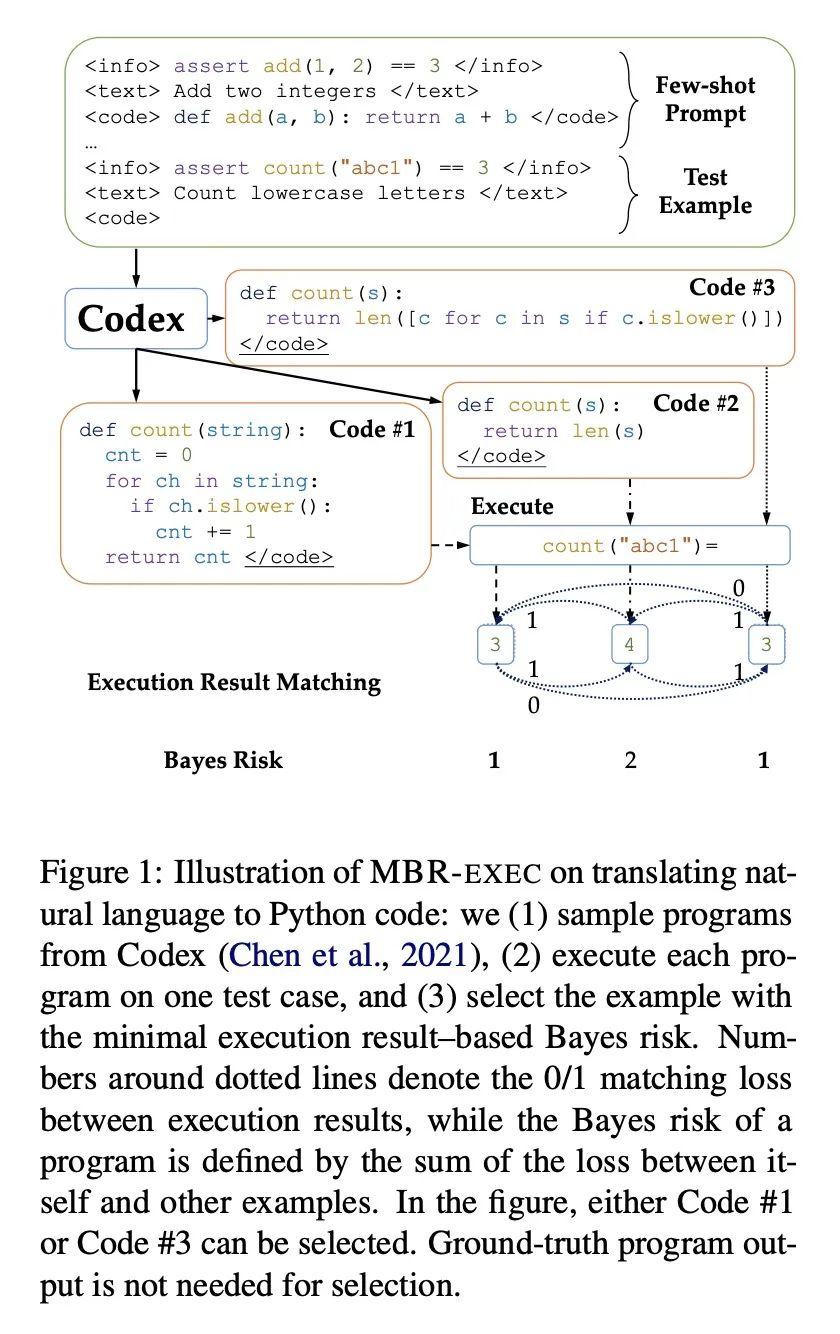
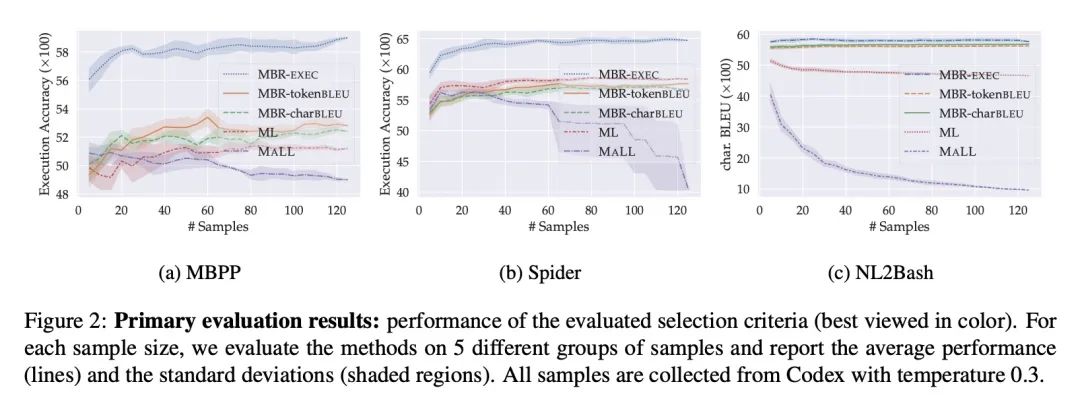
[CL] Natural Language to Code Translation with Execution
基于执行的自然语言到代码翻译
F Shi, D Fried, M Ghazvininejad, L Zettlemoyer, S I. Wang
[Meta AI]
https://arxiv.org/abs/2204.11454

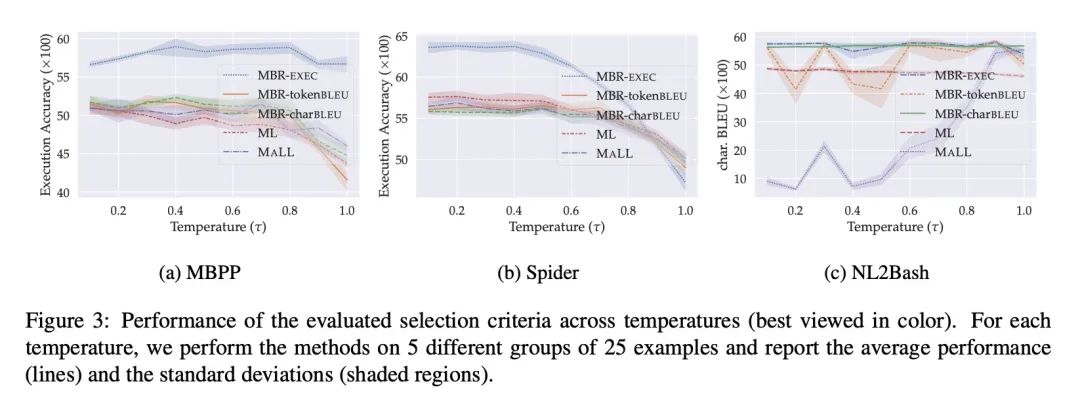
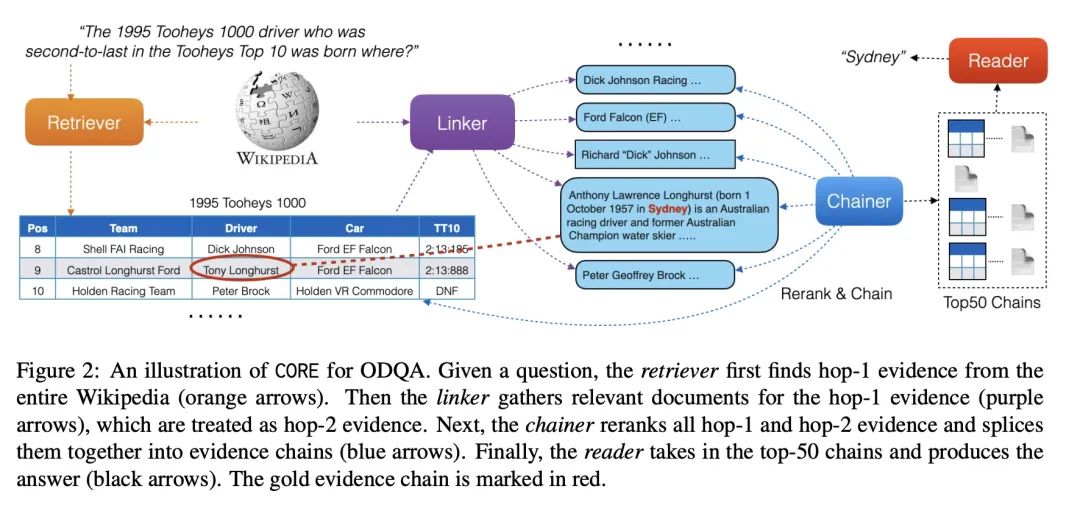
[CL] Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge
基于异构知识推理链的开放域问答
K Ma, H Cheng, X Liu, E Nyberg, J Gao
[CMU & Microsoft Research]
https://arxiv.org/abs/2210.12338

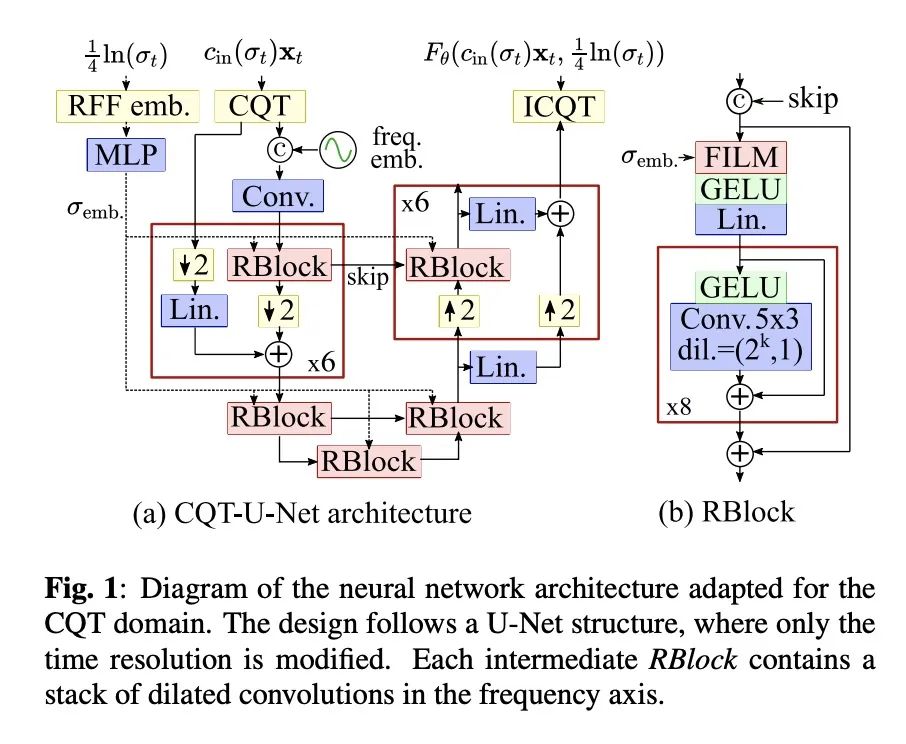
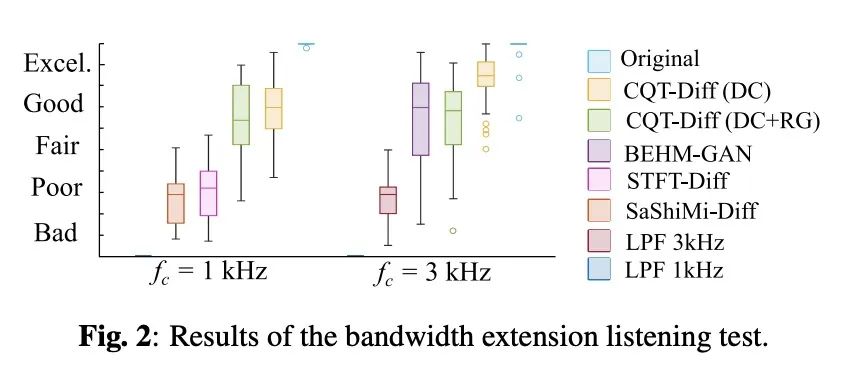
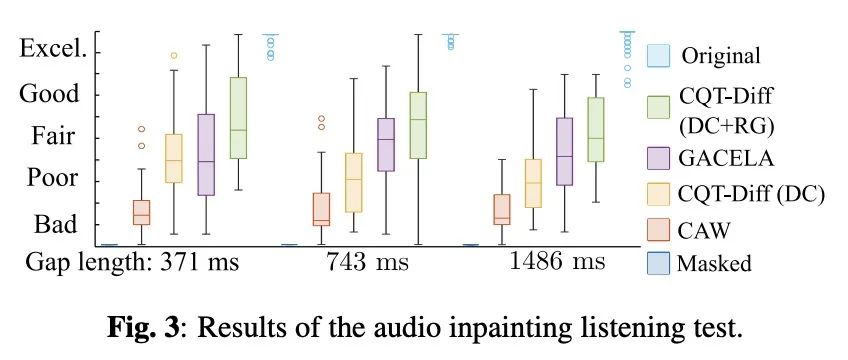
[AS] Solving Audio Inverse Problems with a Diffusion Model
基于扩散模型解决音频逆问题
E Moliner, J Lehtinen, V Välimäki
[Aalto University]
https://arxiv.org/abs/2210.15228

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢