
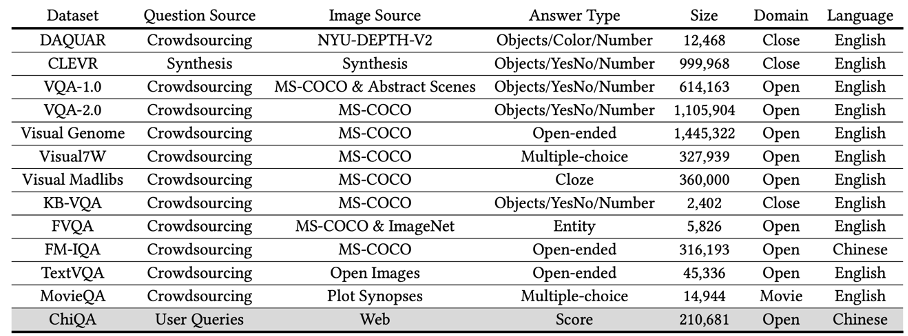
近年来,随着问答技术和多模态理解技术的蓬勃发展,视觉问答任务(Visual Question Answering)变得越来越受关注。诸如 VQA、CLEVER、Visual-7W 等大规模视觉问答数据集陆续发布,极大地推动了视觉问答任务的迭代发展。然而,当前大部分视觉问答数据都是人工合成问题,如 “她的眼睛是什么颜色” 这种标注者在看到图片后虚构设计出的。人工产生的数据会相对简单、低质甚至有偏。因此,在这项工作中,我们基于 QQ 浏览器中用户真实的问题,提出了一个基于中文的大规模图片问答数据集:ChiQA。
ChiQA 包含有超过 4 万个真实用户 query 和超过 20 万个问题 - 图像对。数据和一些 baseline 模型已经公布在GitHub。相关研究已经被 CIKM2022 长文录用。

论文地址:https://arxiv.org/abs/2208.03030
Github地址:https://github.com/benywon/ChiQA
对比单模态问答任务
ChiQA的三个显著特性
问答系统(Question Answering) 是人工智能和智能语言处理中非常重要的任务之一。近年来,随着大规模数据集(如 SQuAD、NaturalQuestions)的发布以及大规模预训练语言模型(如 BERT、GPT)的提出,问答任务得到了飞速的发展。然而,当前大部分问答任务都是单模态的,即问题、资源以及答案都是基于文本的。然而,从认知智能以及实际应用的角度来说,多模态资源如图像在很多时候往往能提供更为丰富的信息和答案。例如,对于一个问题:iPhone13 的尺寸是多少?一个针对 iPhone13 不同型号的尺寸对比图会更加清楚和直观。还有一些例子如下图所示:
 图一:一些适合用图片回答用户问题的例子
图一:一些适合用图片回答用户问题的例子
1)所有的问题都是图像相关的(image-dependent),即标注者看到图片之后提出问题。在大规模数据构建过程中,人工生成的问题往往会缺乏多样性,而且往往由于标注者的主观因素会产生偏置。在这种先看资源,再提问的数据上训练的模型往往可以不用看背景资源只看问题而轻易达到非常好的效果;
-
真实问题,真实图片:ChiQA 中的图片来源于随机用户的查询。这些查询是开放域中随机的用户 query,这些 query 非常多样,而且 query 的领域分布非常广泛。这样随机的多样性 query 保证了我们的数据中的问题不会有偏; -
可回答性:对于问答任务来说,可回答性是一个非常重要的方面。在 ChiQA 中我们不要求标注人员给出最终的答案:因为这样往往会引入一些额外的偏置,比如标注人员的常识。相反的,我们着重于可回答性,即图片对于问题是否可以回答。这种可回答性可以让 ChiQA 的标注人员既需要理解 query,也需要理解图片; -
无偏的:因为随机 query 中也会存在 28 定律,即一些高频或者单一的问题往往会出现很多次,数据中这种简单模式的问题会占据大多数,造成数据中真正跨模态理解的偏置。因此,我们在数据收集过程中引入了两阶段的主动学习过程,在第一阶段随机 query 标注完成后,我们训练了一个简单的模型,然后用这个模型挑选出 "更难" 的一些模型,从而让二阶段的标注数据中数据的丰富度和难度相对更高。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢