
第一辆汽车诞生之初,时速只有 16 公里,甚至不如马车跑得快,很长一段时间,汽车尴尬地像一种“很酷的玩具”。人工智能作图的出现也是如此。
AI 作图一开始的 “风格化” 本身就为 “玩” 而生,大家普遍兴致勃勃地尝试头像生成、磨皮,但很快就失去兴趣。直到扩散模型的降临,才给 AI 作图带来质变,让人们看到了 “AI 转成生产力” 的曙光:画家、设计师不用绞尽脑汁思考色彩、构图,只要告诉 Diffusion 模型想要什么,就能言出法随般地生成高质量图片。
然而,与汽车一样,如果扩散模型生成图片时“马力不足”,那就没法摆脱玩具的标签,成为人类手中真正的生产工具。
起初,AI 作图需要几天,再缩减到几十分钟,再到几分钟,出图时间在不断加速,问题是,究竟快到什么程度,才会在专业的美术从业者甚至普通大众之间普及开来?
显然,现在还无法给出具体答案。即便如此,可以确定的是 AI 作图在技术和速度上的突破,很可能已经接近甚至超过阈值,因为这一次,OneFlow 带来了字面意义上 “一秒出图” 的 Stable Diffusion 模型。
-
OneFlow Stable Diffusion 使用地址:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion
-
OneFlow 地址:https://github.com/Oneflow-Inc/oneflow/
比快更快,OneFlow 一马当先
下面的图表分别展示了在 A100 (PCIe 40GB / SXM 80GB)、RTX 2080 和 T4 不同类型的 GPU 硬件上,分别使用 PyTorch, TensorRT, AITemplate 和 OneFlow 四种深度学习框架或者编译器,对 Stable Diffusion 进行推理时的性能表现。
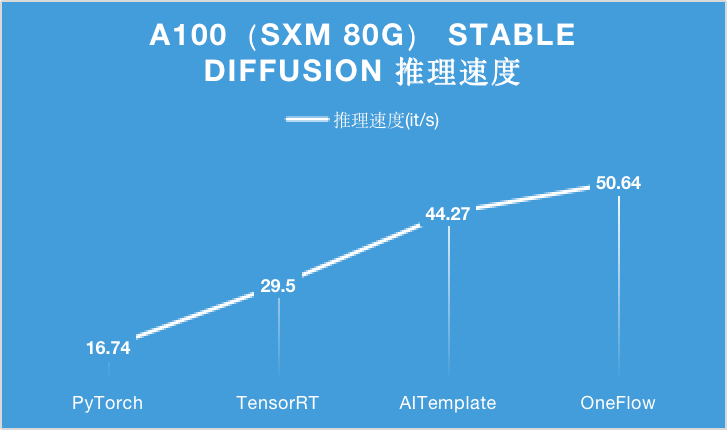
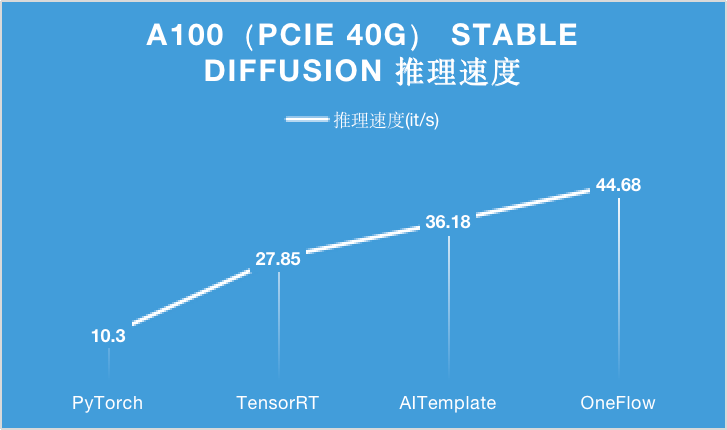
对于 A100 显卡,无论是 PCIe 40GB 的配置还是 SXM 80GB 的配置,OneFlow 的性能可以在目前的最优性能之上继续提升 15% 以上。
特别是在 SXM 80GB A100 上,OneFlow 首次让 Stable Diffusion 的推理速度达到了 50it/s 以上,首次把生成一张图片需要采样 50 轮的时间降到 1 秒以内,是当之无愧的性能之王。
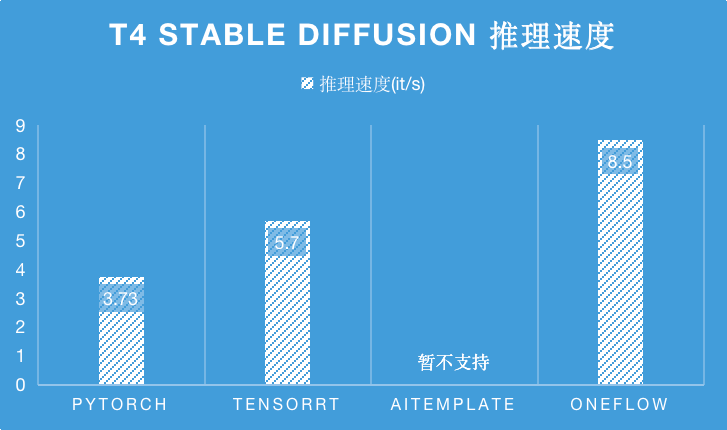
在 T4 推理卡上,由于 AITemplate 暂不支持 Stable Diffsuion,相比于目前 SOTA 性能的 TensorRT,OneFlow 的性能是它的 1.5 倍。
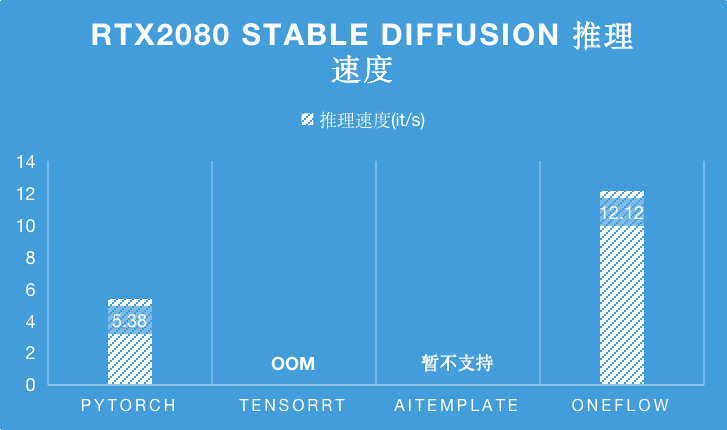
而在 RTX2080 上,TensorRT 在编译 Stable Diffsuion 时会 OOM ,相比于目前 SOTA 性能的 PyTorch,OneFlow 的性能是它的 2.25 倍。
综上,在各种硬件以及更多框架的对比中,OneFlow 都将 Stable Diffusion 的推理性能推向了一个全新的 SOTA。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢