


一、研究背景
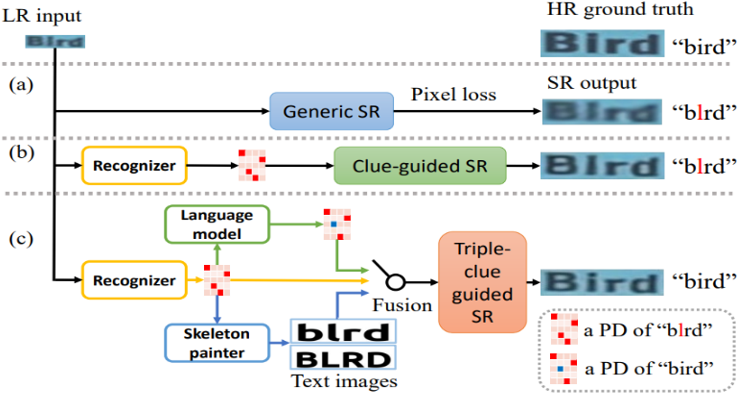
场景文本图像超分辨率(STISR)作为一种重要的图像预处理技术,能够显著降低低分辨率文本图像的识别难度,提升识别模型性能。早期的方法[1-3]将 STISR任务视为一般的超分辨率(SR)问题,仅利用像素级损失函数捕获的像素级信息来恢复 LR 图像,如图1(a)所示。然而,这些方法忽略了文本图像所特有的文本特征信息,因而无法实现最佳的性能。
最新的一些方法[4-7]提出关注图像的文本特征,并利用文本信息来引导高分辨率文本图像的重建,如图1(b)所示。这些方法通常引入额外的识别器,使用识别器的识别结果作为指导超分辨率的线索。例如,[4][5]提出使用一个预训练好的识别网络对所恢复的文本内容进行监督,并通过识别器提供的注意力热图对每个字符进行定位; [6][7]提出使用识别网络输出的文本概率分布作为图像的文本先验知识,更好地对超分过程进行语义指导。尽管上述方法的性能取得了显著提升,但直接使用识别器的反馈仍存在两个问题:1)模态兼容性问题。识别器的输出是概率分布(PD)的形式,它与STISR这一低级的像素级视觉任务有明显的模态差距,因此存在模态兼容性问题。2)不准确。识别器的识别结果通常不准确(CRNN[8]在LR/HR图像的识别准确率仅为26.8%/72.4%),因而会误导后续的超分辨率重建。
因此,基于对现有方法的思考,作者提出了一种新的场景文本图像超分辨率方法C3-STISR。该方法联合使用识别器的反馈、视觉信息和语言信息等三重线索(Triple Clues)来指导超分过程,如图1(c)所示。具体来说,视觉线索是根据识别器预测的文本序列来绘制图像,并从所绘制的文本图像中提取到的图像特征;由于视觉线索与STISR任务更兼容,因此能够得到更好的超分效果(如图1(c)中,由于视觉线索的使用,获得了更清晰的字符“B”)。而语言线索是由预训练好的的语言模型生成的,它能够校正预测的文本(在图1(c)中,“Blrd”被校正为“Bird”)。此外,由于这些线索具有不同的形式,该方法设计了一个线索提取模块以分别提取识别、视觉和语言线索,并设计了一个门控融合模块将三重线索融合为一个综合的、统一的超分辨率重建引导信号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢