

作者:Alexis Jacq, Manu Orsini, Gabriel Dulac-Arnold,等
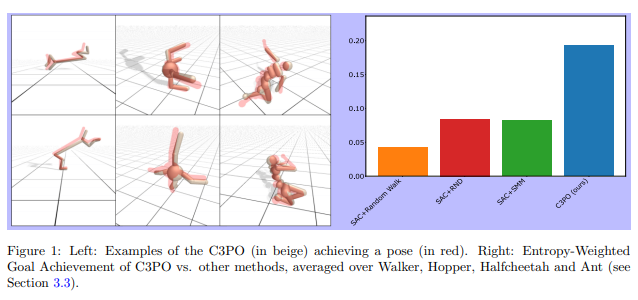
简介:本文研究产生高熵行为的探索方法。给定一个特定的实施例,作者提出了一种新方法:C3PO,该方法学习能够实现任意位置和姿势的策略。这样的策略将允许更容易控制,并且可以作为下游任务的关键构建块重复使用。该方法有两个方面:首先,作者引入了一种新的探索算法,该算法针对均匀覆盖进行优化,能够发现一组可实现的状态,并研究其获得高覆盖率和难以发现状态的能力;其次,作者利用这组可实现的状态作为通用目标实现策略的训练数据,这是一种基于目标的 SAC 变量。最后,作者展示了展示了大量无监督训练对目标达成策略的影响,通过SOTA效果的基于姿势的Hopper、Walker、Halfcheetah、Humanoid和Ant实施例控制。
论文下载:https://arxiv.org/pdf/2211.03521.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢