
作者:Xiaoran Fan, Chao Pang, Tian Yuan, 等
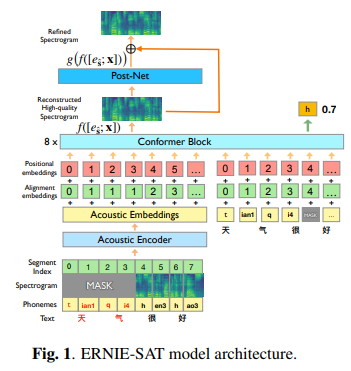
简介:本文研究跨语言场景中的语音文本联合预训练框架。语音表示学习,改进了单一语言的语音理解和语音合成任务。但是,尚未探索其在跨语言场景中的能力。在本文中,作者扩展了跨语言多说话人语音合成任务的预训练方法,包括跨语言多说话人语音克隆和跨语言多说话人语音编辑。作者提出了一个语音-文本联合预训练框架,在给定语音示例及其转录的情况下,作者随机屏蔽频谱图和音素。通过学习用不同语言重建输入的掩码部分,作者的模型显示出比基于说话人嵌入的多说话人 TTS 方法有很大改进。此外,作者的框架对于训练和推理都是端到端的,无需任何微调。在跨语言多说话人语音克隆和跨语言多说话人语音编辑任务中,实验表明:作者的模型优于基于说话人嵌入(speaker-embedding-based)的多说话人 TTS 方法。代码和模型可在 PaddleSpeech 上公开获得。
论文下载:https://arxiv.org/pdf/2211.03545.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢