
在云计算时代,软件系统的可靠性至关重要,一点小问题就可能引发蝴蝶效应,影响百万用户。为了了解并保障软件系统的稳定,日志被广泛用于观测并忠实记录系统的内部状态,是分析与解决系统故障的基础。然而,使用人工分析体量巨大的日志并不现实,因此自动化日志分析日渐兴起,而日志解析是关键且基础的步骤。在实践中,日志数据往往存在着数据量巨大、极度不均衡、数据漂移且没有标注等问题。为了解决这些问题,并将日志解析真正落实到复杂的云环境中,微软亚洲研究院的研究员们和微软 Azure 的工程师们提出了支持用户反馈的大数据场景下的日志解析方法 SPINE,并将其落地到了产品线中。
近日,SPINE 被软件工程领域的全球顶级会议 ESEC/FSE 2022 接收,并荣获 “杰出论文奖” (ACM SIGSOFT Distinguished Paper Award)。

论文链接:
https://www.microsoft.com/en-us/research/publication/spine-a-scalable-log-parser-with-feedback-guidance-2/
ESEC/FSE 大会全称为 ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) ,与 ICSE、ASE 并列为软件工程领域三大顶级会议,在学术界和工业界都具有极大的影响力。今年的 ESEC/FSE 大会有效投稿量为449,最终接收99篇,接收率约为22%,会议将于2022年11月14日至18日在新加坡举办。
日志解析:智能日志分析的关键核心
日志解析可从形式上被定义为:从原始日志信息中提取日志模板和日志参数的任务。日志信息的主体通常由两部分构成:(1) 模板:描述系统事件的静态的关键字,通常为一段自然语言,这些关键字被显式地写在日志语句的代码中。(2) 参数:也称为动态变量,是在程序运行期间的某个变量的值。

图1:日志解析示例
现阶段,大量的自动化日志解析工作致力于准确高效地分离日志中的模板和参数部分。尽管这些日志解析器在公开的基准日志数据集上取得了良好成效,但它们在实际应用中仍然面临诸多挑战。微软的研究员和工程师们通过在实际工业环境中进行的大量例证研究,揭示出其中的两个核心挑战。
大规模、不平衡的日志数据
首先,大多数现有的日志解析器只能在单线程模式下运行。然而,现实世界的日志数据量极为庞大。例如,在例证研究中,仅微软某个内部服务,平均每天就会产出约50亿条日志,合每小时约2亿条。如此规模的数据量超出了任何单一计算核或节点的处理能力,尤其难以满足实时日志分析的需要。
表面上,日志解析似乎是一项很容易并行化的任务。然而,工业实践中日志数据的内在不平衡性将大大降低并行化的效率。这促使研究员们设计一种能够在多个计算单元上进行更有效的横向扩展的日志解析器。
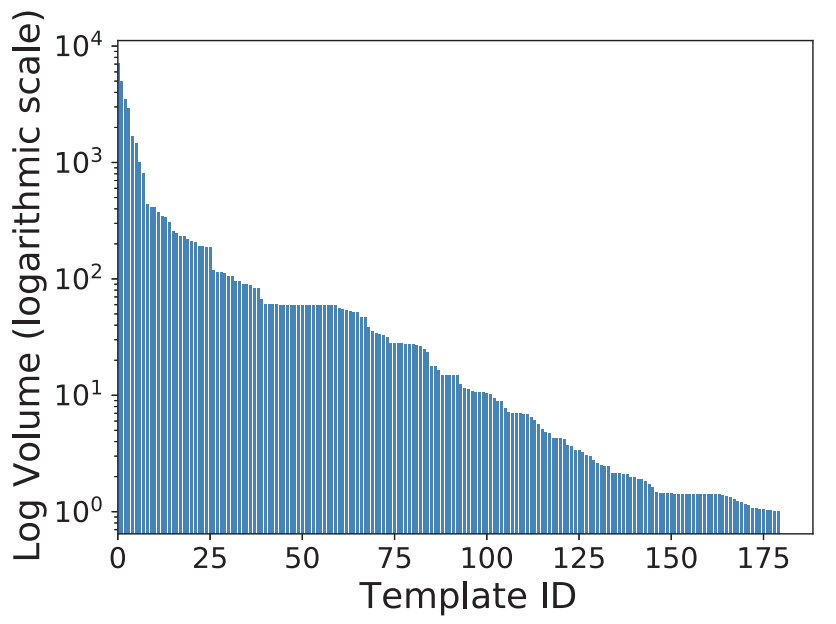
图2:不同日志模板下日志数量分布:X 轴表示模板 ID,Y 轴表示对应于该模板的日志数量(Y 轴为对数标度)。
日志漂移与解析器的快速适应
另一个挑战来自于日志伴随着软件系统的迭代而不断发生变化。研究员们在微软某内部服务中收集了8周的日志,并计算随着时间推移而新出现的日志模板的数量,结果如图3所示。由于持续集成/交付(CI/CD)的开发范式,日志模板的数量会随时间增加,日志解析器也应不断地更新,以适应数据的漂移,否则解析的准确度会随时间流逝而逐渐下降。
遗憾的是,因为缺少足够的有标签数据,现有的日志解析器大多采用无监督的方法,例如聚类、频繁模式挖掘、最长共同子序列提取等来识别日志的公共部分作为模板。这需要大量的人工标注来进行繁琐的模型超参数调整,并且要求用户对日志解析方法的内部原理极为熟悉。因此,研究员们认为日志解析应当降本增效,尽可能地降低用户反馈机制的成本,提高用户体验,以达到快速调整日志解析器参数的效果。
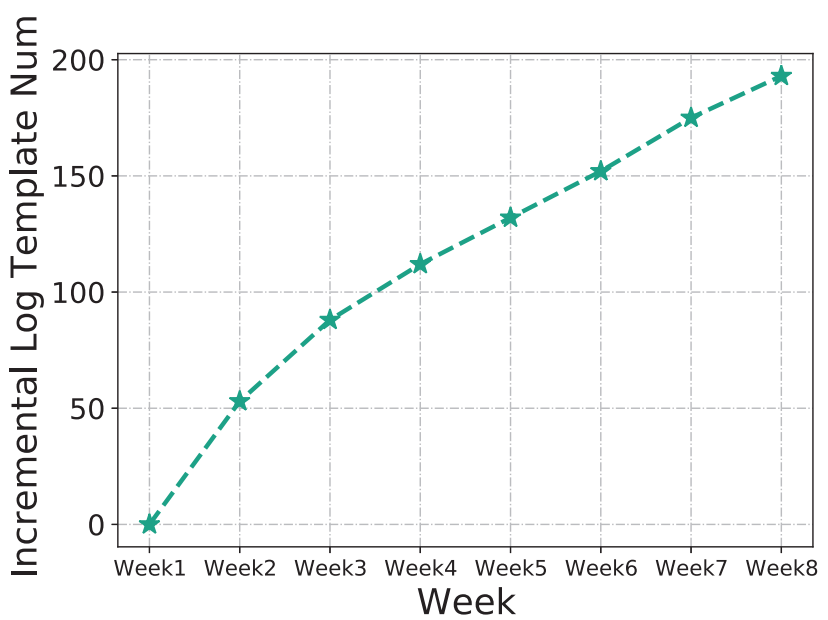
图3:新日志模板数量增加曲线
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢