

一、研究背景
近年来自监督预训练技术已在文档智能领域进行了许多的实践,大多数技术是将图片、文本、布局结构信息一起输入统一的Transformer架构中。在这些技术中,经典的流程是先经过一个视觉模型提取额外文档图片信息,例如OCR引擎或版面分析模型,这些模型通常依赖于有标注数据训练的视觉骨干网络。已有的工作已经证明一些视觉模型在实际应用中的性能经常受到域迁移、数据分布不一致等问题的影响。而且现有的文档有标注数据集稀少、样式单一,训练出来的骨干网络并非最适用于文档任务。因此,有必要研究如何利用自监督预训练技术训练一个专用于文档智能领域的骨干网络。本文针对上述问题,利用离散变分编码器和NLP领域的常用预训练方式实现了文档图像的预训练。
 Fig 1 Visually-rich business documents with different layouts and formats for pre-training DiT
Fig 1 Visually-rich business documents with different layouts and formats for pre-training DiT二、DiT原理简述
2.1总体结构
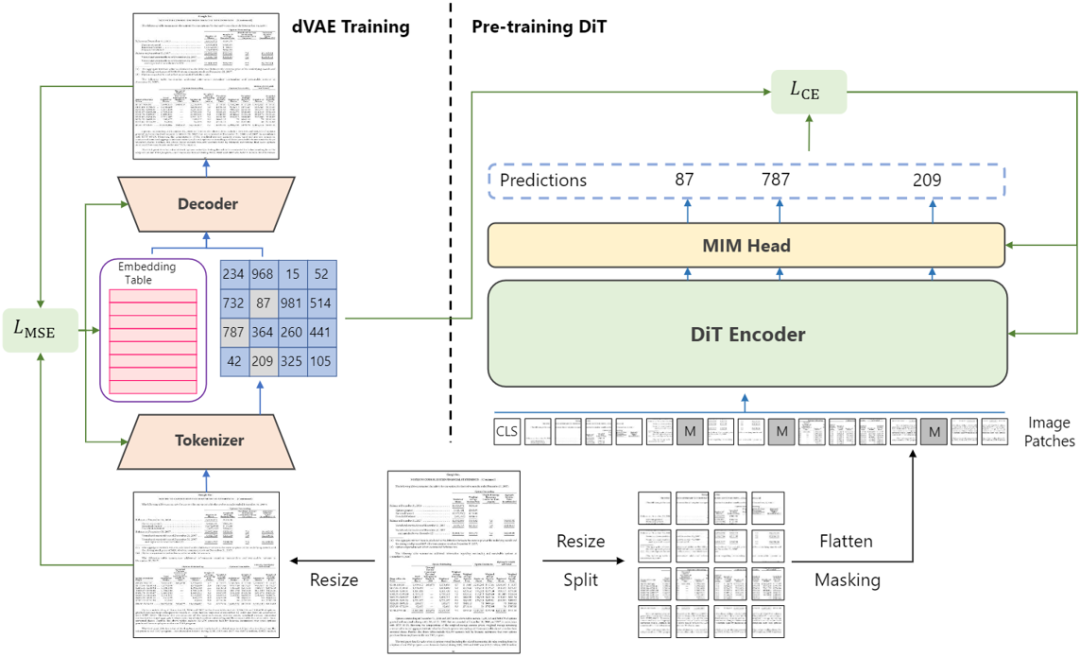 Fig 2 Overall Architecture of DiT
Fig 2 Overall Architecture of DiTFig 2是DiT的整体结构。DiT使用ViT[3]作为预训练的骨干网络,模型的输入是图像Patch化后的Embedding特征向量,Patch的数量和离散变分编码器的下采样比例有关。输入经过ViT后输出到线性层进行图像分类,分类层的大小是8192。预训练任务和NLP领域的完型填空任务一致,先对输入的Patch随机掩膜,在模型输出处预测被遮盖的Patch对应的Token,Token由Fig 2 中左侧的离散变分编码器生成,作为每个Patch的Label,预训练过程使用CE Loss监督。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢