
本文主要讲述了基于文本提示创作新作品的流行 AI 扩散模型对比。本文的原作者是波士顿地区的艺术家、发明家和工程师Robert A. Gonsalves。他研究并撰写有关 AI 的创造性用途的文章。

我之前写过关于使用来自 OpenAI 的最新 DALL-E [1] 模型从文本提示创建数字艺术的文章。在本文中,我会将 DALL-E 与其他两个流行的文本到图像模型进行比较,即来自慕尼黑大学慕尼黑分校 [2] 和 Midjourney [3] 的 CompVis 小组的稳定扩散,由同名研究实验室提供。
我将从扩散模型的一些背景信息开始,这是此处描述的所有三个系统的基础。然后,我将讨论我如何使用同样来自 OpenAI 的 CLIP 模型 [4],使用一种称为对比相似性测试的新技术自动计算用于判断生成艺术的客观指标。
接下来,我将详细介绍这三种模型,并讨论可用的功能和成本。然后,我将展示当我发送 16 个不同的提示时这三个系统创建了什么,显示美学质量和提示相似性的指标。我将以对决战的最佳系统加冕作为结束,然后进行简短的讨论。
扩散模型
扩散模型是机器学习 (ML) 系统,最初设计用于去除图像中的噪声。随着降噪系统的训练时间越来越长并且越来越好,它们最终可以从纯噪声作为唯一输入生成逼真的图片 [5]。
最近,扩散模型已经取代生成对抗网络(GAN)成为最先进的图像生成器。2021 年 6 月,OpenAI 发表了一篇名为《Diffusion Models Beat GANs on Image Synthesis》的论文。[6] 以下是作者所说的。
扩散模型是一类基于似然性的模型,最近已被证明可以产生高质量的图像,同时提供理想的属性,例如分布覆盖、固定训练目标和易于扩展。这些模型通过逐渐从信号中去除噪声来生成样本,并且它们的训练目标可以表示为重新加权的变分下限。... [通过] 改进 [the] 模型架构,然后通过设计一个以多样性换取保真度的方案......我们实现了一种新的最先进的技术,在几个不同的指标和数据集上超越了 GAN。
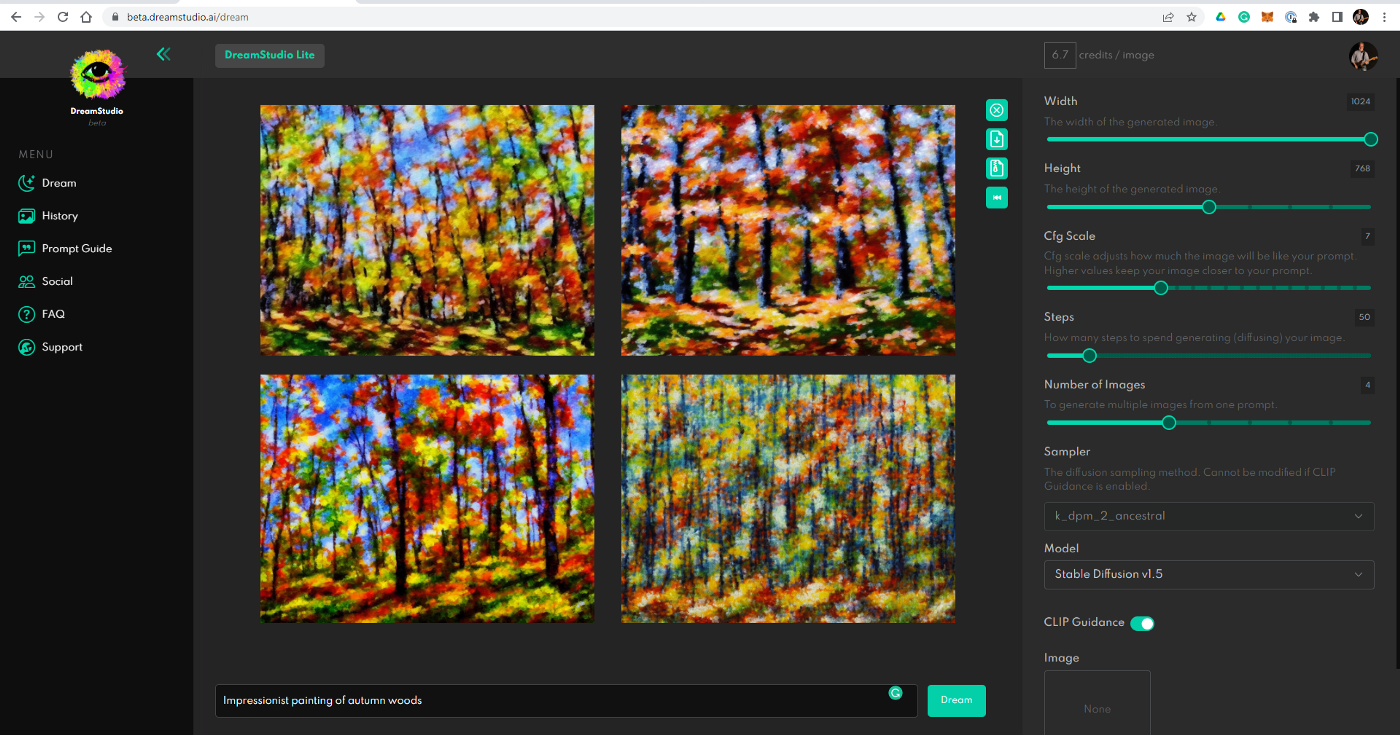
扩散模型的作者在数百万个文本/图像对上训练他们的系统,因此当您输入文本提示时,系统将交互地生成与提示匹配的新图像。例如,下一节的截图显示了提示“秋天的树林印象画”的结果。
认识竞争者
稳定扩散
摊牌中的第一个扩散模型是稳定扩散。CompVis 小组在 LMU Munich [2] 开发了它。该模型是与Stability AI和Runway一起开发的。
该模型的组件图显示了输入图像 (x) 在扩散过程中如何编码到“潜在空间”中并解码为输出图像 (x̄)。解码过程在训练期间使用文本、图像等进行调节。
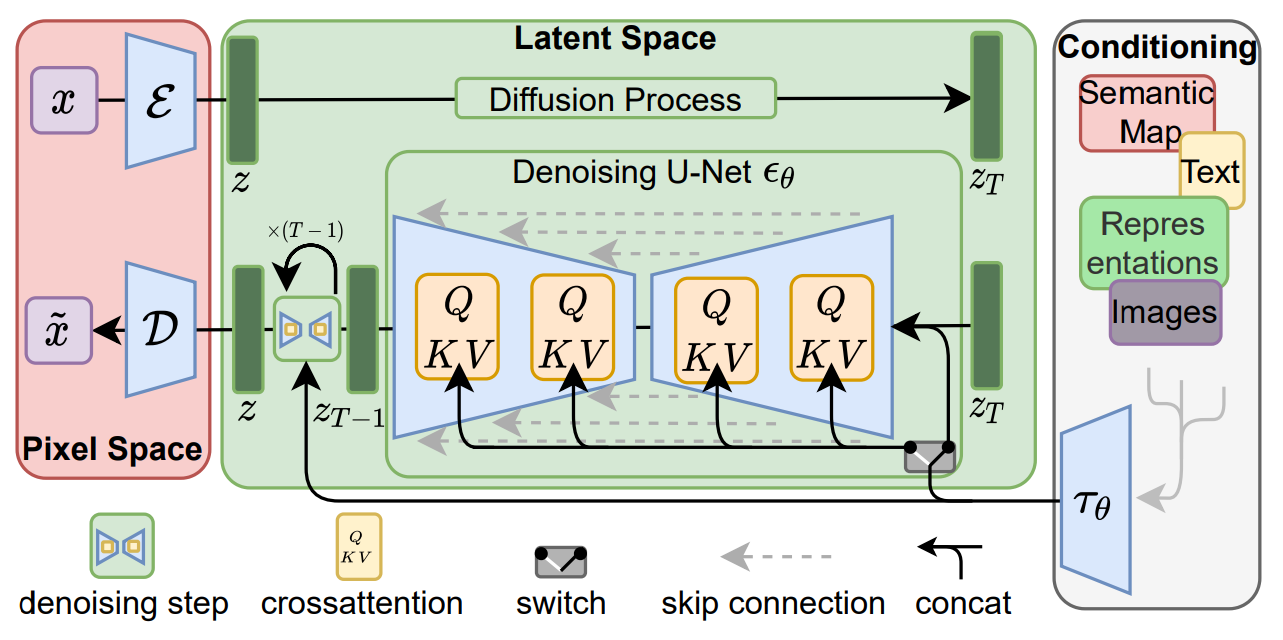
稳定扩散分量图,图片来自CompVis 的论文
作者在GitHub上将它作为一个开源项目和一个商业服务发布,该服务具有一个名为DreamStudio的易于使用的 Web UI 。我使用 DreamStudio 服务进行这场对决。
DALL-E

DALL-E 用户界面,作者提供的图片
称为 DALL-E 的系统是 OpenAI [1] 开发的扩散模型的第二次迭代,它与称为 CLIP [4] 的图像/文本编码系统结合使用。在论文中,图像到文本的扩散模型称为 unCLIP。该论文的组件图显示了 CLIP 的工作原理以及 unCLIP 模型如何从文本提示中呈现图像。
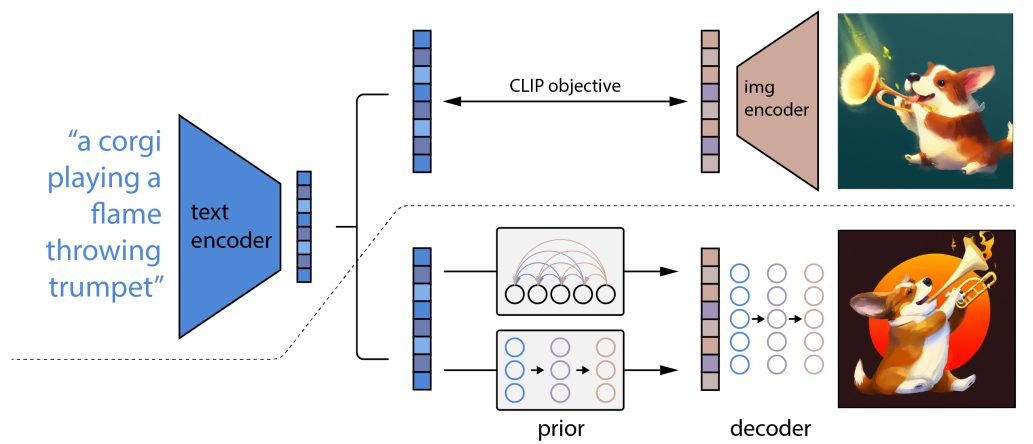
对于摊牌,我使用了 OpenAI 的DALL-E商业服务。
中途
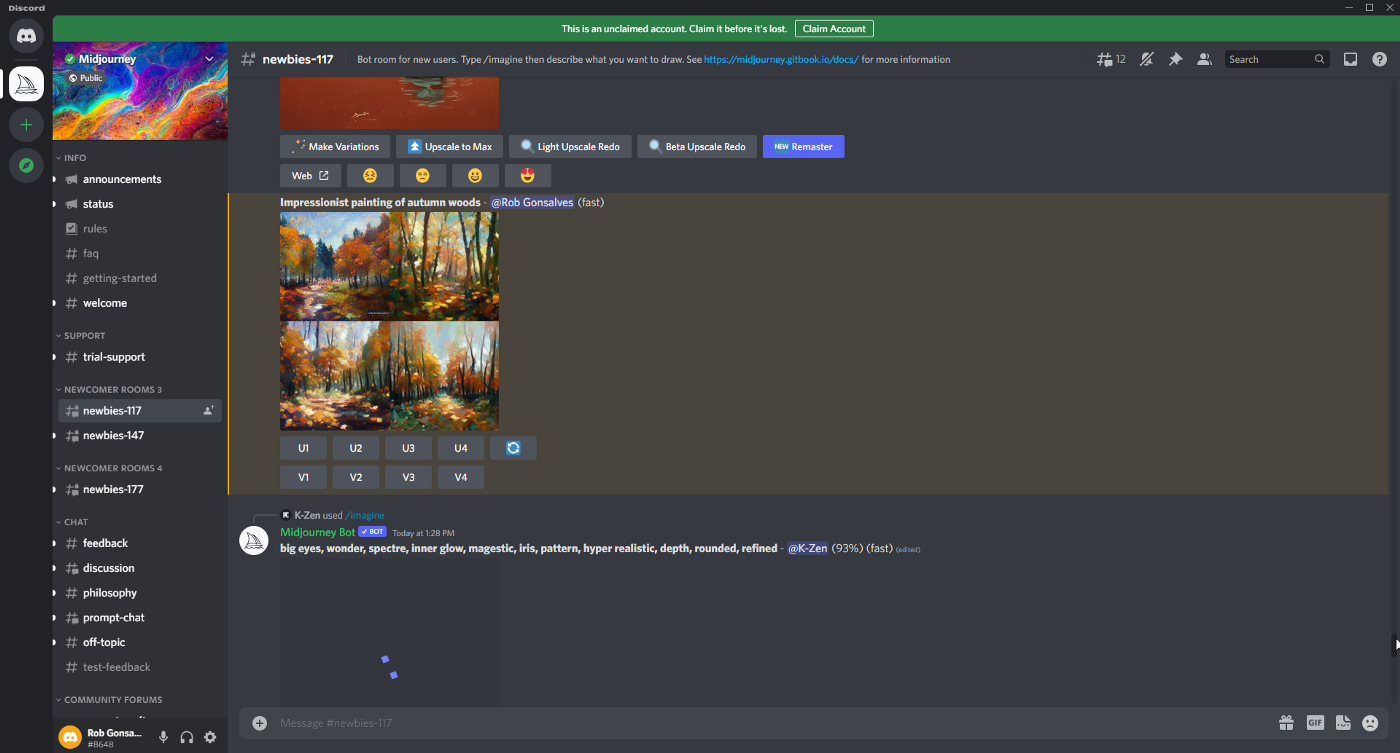
Midjourney 用户界面,图片由作者提供
Midjourney 是一种商业文本到图像的扩散模型,由也称为 Midjourney 的研究实验室创建。该小组由大卫霍尔茨领导,他曾是 Leap Motion 的联合创始人。Midjourney 系统在用户界面的Discord 频道上使用机器人。
比较系统
特征
所有三个系统都将根据文本描述创建图像。例如,这里有一些来自提示“秋天树林的印象派绘画”的图像。



DreamStudio 和 Midjourney 中的稳定扩散模型具有设置屏幕,您可以在其中调整各种参数。对于 DreamStudio,设置位于 UI 中的图像旁边。对于 Midjourney,键入“/settings”以在 Discord 服务器中显示 UI。DALL-E 本身没有任何设置。只有文本提示可用。
以下是 DreamStudio 和 Midjourney 的设置屏幕。
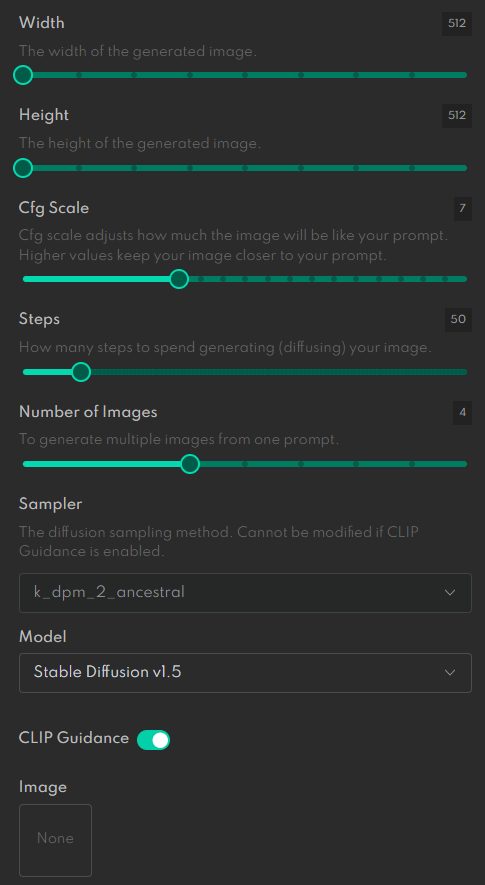
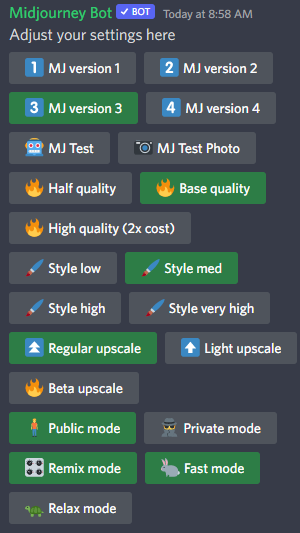
如您所见,这两个系统有很多选择。大多数设置都是自我描述的,而且它们都运行良好。然而,对于我的摊牌项目,我只使用了默认值。
图像尺寸
这三个模型以不同的图像大小运行,但每个模型都有进一步调整大小的选项。
DreamStudio 中的稳定扩散模型默认使用 512x512 图像大小,但您可以使用以 64 像素为增量的设置放大至 1024x1024。我使用 1024 作为最长维度从 Stable Diffusion 创建了大部分图像,但我使用 512x640 的肖像除外。原因是较大的 832x1024 图像经常有“幻影”部分人物出现在构图中,而较小的 512x640 图像只有一个人出现。您可以在下面的示例中看到差异。


请注意,左侧图像的左下方似乎有部分人,而右侧的图像仅显示了一个人。DALL-E 和 Midjourney 系统没有这个问题。
DALL-E 模型可以创建原生 1024x1024 的图像。并且系统提供了使用“添加生成帧”功能来放大图像和更改纵横比的选项。在下面的示例中,您可以看到我是如何通过扩展肖像来增加纵横比的,以显示这个人的头顶和他的躯干更多。


您可以看到 DALL-E 系统如何出色地按照原画的风格渲染图像的缺失部分。
Midjourney 默认以 256x256 的分辨率呈现来自文本提示的图像。系统允许用户选择使用命令行参数指定纵横比,即--ar 4:5。使用此纵横比可生成四张 256x320 的图像。该系统还允许用户在此纵横比下将所选图像放大四倍至 1024 x 1280。调整大小算法使用提示在向上添加上下文细节。这是 Midjourney 放大的图像示例。


您可以看到 Midjourney 如何为男人的脸部添加细节以及笔触中的额外细节。
价钱
DreamStudio 定价
尽管Github上有一个免费的开源版本的 Stable Diffusion ,但它没有 DreamStudio 中提供的任何漂亮的 UI 功能。对于定价,该服务使用信用系统。当您注册时,他们会免费为您提供 200 积分。收取的信用数量取决于图像的大小和用于创建它的“步骤”数。在当前价格下,创建默认步数为 50 的 1024x1024 图像将花费 9.4 个积分。因此,您可以免费生成 21 张高分辨率图像。您可以花 10 美元购买额外的 1,000 积分。以这个价格,生成 50 步、尺寸为 512x512 的图像需要 1 美分,1024x1024 需要 9.4 美分。
DALL-E 定价
DALL-E 还使用信用系统。生成四张带有提示的图像需要一个学分。注册时您将获得 50 个免费积分,每月额外获得 15 个积分。您可以花 15 美元购买另外 115 个积分。一组 4 张图像的价格为 13 美分,或每张 3.2 美分。
中途定价
Midjourney 有使用其服务的月度订阅计划。它基于支付“GPU 分钟数”。您可以免费获得 25 分钟的 GPU 时间,并且可以每月支付 10 美元购买 200 分钟的 GPU 时间。计算出四张图像大约需要 6.7 美分,而调整到 1024x1024 则需要另外 6.7 美分。
回顾一下,对于 1024x1024 的图像,DreamStudio 的成本为 9.4 美分,DALL-E 的成本为 3.2 美分,而 Midjourney 的实际成本为 13.3 美分。
政策
像大多数在线服务一样,这三个系统都定义了它们的使用条款。
DreamStudio 政策
以下是 DreamStudio 的使用条款。第一个项目是一个大项目。用户不拥有他们使用 DreamStudio 服务创建的图像。图像会自动发布到公共领域。请注意,这本身并不排除商业用途;只是用户不必为公共领域的作品付费。免责声明:我不是律师。
所有使用 DreamStudio Beta 和 Stable Diffusion beta Discord 服务的用户在此确认已阅读并接受完整的 CC0 1.0 通用公共领域奉献(可在https://creativecommons.org/publicdomain/zero/1.0/ 获得),其中包括,但不限于上述放弃任何内容的知识产权。
DreamStudio 测试版和 Stable Diffusion 测试版不得用于:
-NSFW、淫秽或色情内容
-仇恨或暴力图像,例如反犹太主义肖像画、种族主义漫画、厌恶女性和滥用职权的宣传等。
- 关于您自己或任何其他人的个人信息。这包括但不限于电话号码、居住地址、社会保险号码、驾驶执照号码、帐号等
。 - 提示中应避免使用版权或商标材料。
DreamStudio 的完整使用条款在此处。
DALL-E 政策
相比之下,OpenAI 允许 DALL-E 用户拥有他们的图像并将其用于商业目的。
以下是 DALL-E 内容政策的重点。
在您的使用中,您必须遵守我们的内容政策:
请勿尝试创建、上传或共享非 G 级或可能造成伤害的图像。
不要在人工智能参与方面误导您的听众。
尊重他人的权利。请通过我们的帮助中心向我们的团队报告任何涉嫌违反这些规则的行为。
DALL-E 的完整使用条款在这里。
中途政策
对于用户创建图像的所有权,Midjourney 区分了非付费用户和付费用户。非付费用户不拥有他们创建的图像,但 Midjourney 授予您这些作品的知识共享非商业性 4.0 署名国际许可。另一方面,付费用户拥有他们创建的图像的版权,但授予 Midjourney 完全许可以供他们使用。
Midjourney 的完整使用政策在这里。
除了使用政策外,Midjourney 还有内容审核政策。重点如下。
Midjourney 旨在通过 Discord 和会员画廊成为一个默认开放的社区。我们的规则状态内容必须是 PG-13,具体而言,#rules 频道状态,
请勿创建本质上不尊重、攻击性或其他辱骂性的图像或使用文本提示。绝不容忍任何形式的暴力或骚扰。
没有成人内容或血腥。请避免制作视觉上令人震惊或令人不安的内容。我们将自动阻止一些文本输入。
Midjourney 的完整内容审核政策在这里。
社会问题
Stable Diffusion 和 DALL-E 的创建者在论文中讨论了图像生成模型可能引起的社会关注。
图像等媒体的生成模型是一把双刃剑:一方面,它们支持各种创造性应用,特别是像我们这样降低训练和推理成本的方法,有可能促进对这项技术的访问并使其民主化勘探。另一方面,这也意味着更容易创建和传播被操纵的数据或传播错误信息和垃圾邮件。特别是,故意操纵图像(“深度造假”)是这种情况下的一个常见问题,尤其是女性受此影响尤为严重。— Robin Rombach,慕尼黑大学的 CompVis 小组 [2]
正如 GLIDE 论文中所讨论的,图像生成模型存在与欺骗性和其他有害内容相关的风险。unCLIP 的性能改进也提高了 GLIDE 的风险状况。随着技术的成熟,它会留下更少的痕迹和指示输出是 AI 生成的,从而更容易将生成的图像误认为是真实图像,反之亦然。还需要更多研究架构的变化如何改变模型学习训练数据中的偏差。— Aditya Ramesh,等。等人,OpenAI [1]
量化好的和坏的艺术
在比较三个模型的输出之前,我将讨论我开发的一种技术,用于完成看似不可能的事情:使用自动算法为艺术品的美学分配一个定量值。
好艺术
为了看看算法是否有效,我首先收集了九个我们社会认为好的作品。我在谷歌搜索中输入了“名画”,下面是一些出现的图片。

如您所见,我选择了三幅风景、三幅肖像和三幅静物画。是的,收藏中有三幅梵高作品。
糟糕的艺术
接下来,我需要选择九幅“糟糕”的画作。好消息是我住的波士顿地区有一个坏艺术博物馆。我得到了博物馆“常任代理临时执行主任”的许可,可以将他们收藏的一些画作用于本文。这里是不良艺术的集合。

好吧,这似乎是一些真正糟糕的艺术,尤其是与上面的杰作相比。
相似性检验
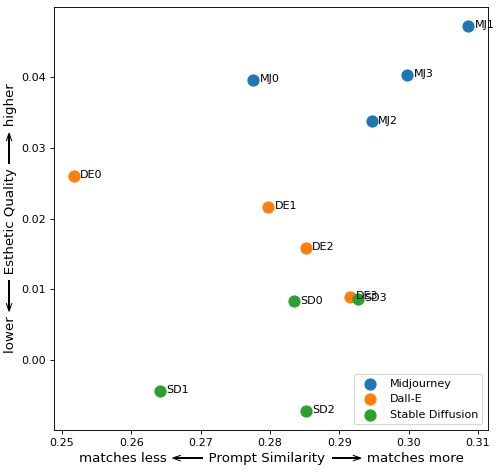
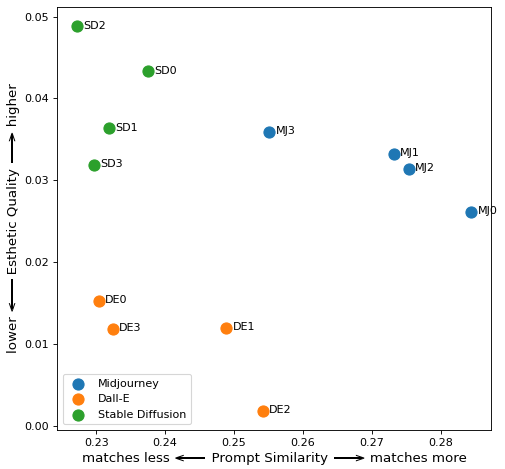
为了看看我是否可以使用 CLIP 模型来区分两组绘画,我首先将每个图像的嵌入与短语“真实艺术”和“好艺术”的嵌入进行比较,并绘制图像和单词之间的相似性. 正如您在左下图中看到的那样,这并没有像我预期的那样将好艺术与坏艺术分开。事实上,图表顶部附近还有更多“糟糕”的画作。

对比相似性检验
我对此进行了一些实验,发现诀窍是发送四个短语,“假艺术”、“真实艺术”、“坏艺术”和“好艺术”,然后对结果进行一些数学运算。在获得文本和图像嵌入的相似性后,我使用以下等式来获得我正在寻找的指标。
good_factor = good_art - bad_art
real_factor = real_art - fake_art
您可以在右上方的图表中看到结果。我将此称为对比相似性测试,它似乎与我的 18 幅图像样本配合得很好。
然后,我将好的因素和真实因素结合起来,创建了一个单一的审美质量指标:审美质量 = 好因素 + 真实因素。以下是使用此指标的好坏艺术如何叠加。
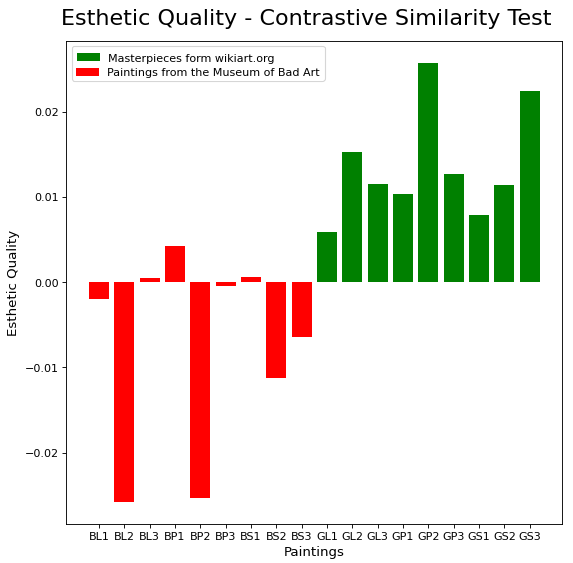
这似乎与我对画作的分析大致相符。你可以看到比尔克林顿(BP1)的肖像是最好的,而莫奈的印象日出(GL1)是最坏的。
渲染摊牌
为了测试这三个系统,我设计了 16 个提示并输入它们以生成图像。
风景
1. 印象派秋季树林
画 2. 连绵起伏的农田画
3. 波涛汹涌
的现代海景 4. 波士顿城市天际线写实画抽象绘画
1. 橙色三角形抽象绘画
2. 紫色和绿色方块的块色绘画
3. 海蓝色球体抽象绘画
4. 黄色和黑色细线的飞溅绘画静物
1. 一碗水果的静物画
2. 洋红色花瓶中向日葵的印象派油画
3. 彩色玻璃瓶的静物画
4. 带灯、书和老花镜的床头柜油画肖像
1. 1920 年代男性的立体主义绘画
2. 巴西年轻女性的炭
笔画 3. 专注的葡萄牙人的
油画 4. 韩国女性的粉彩画
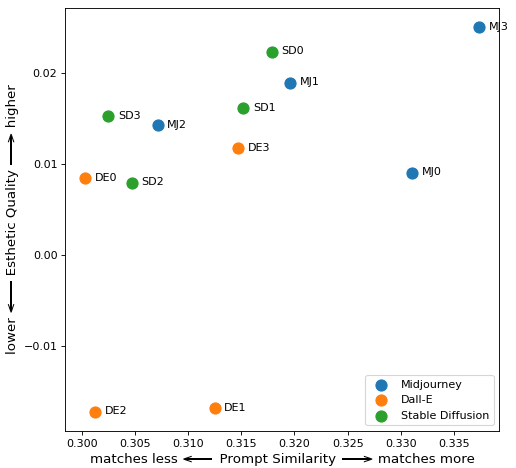
然后我通过 CLIP 运行结果以找到两个指标并绘制结果。
审美质量=好因素+真实因素提示
相似度=余弦相似度(提示嵌入,图像嵌入)
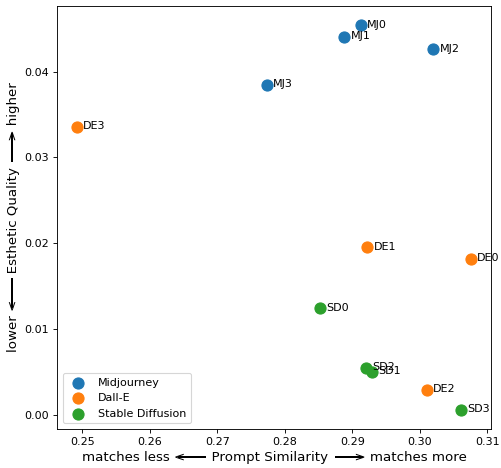
抽象画
提示:“橙色三角形的抽象画”

提示:“用紫色和绿色方块块色画”

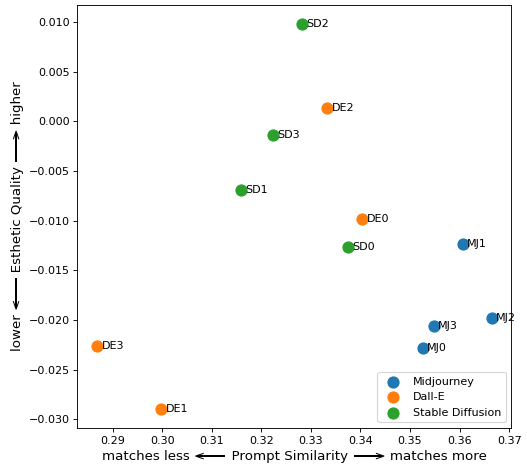
提示:“海蓝色球体的抽象画”

提示:“带有细黄线和黑线的飞溅画”

景观
提示:“秋天树林的印象派绘画。”

提示:《连绵起伏的农田画》

提示:“波涛汹涌的现代海景”

提示:“波士顿城市天际线的写实绘画”


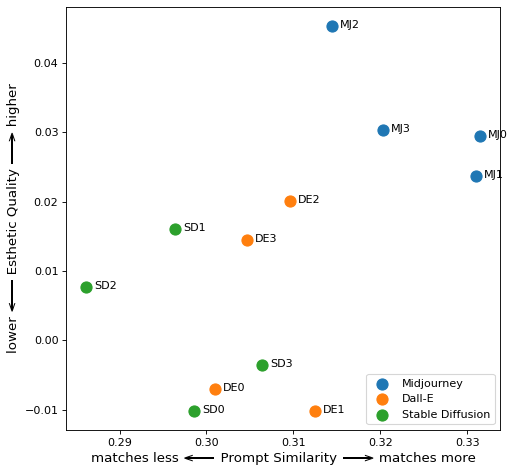
静物
提示:“一碗水果的静物画”


提示:“洋红色花瓶中的向日葵印象派油画”


提示:“彩色玻璃瓶的静物画” 

提示:“带灯、书和老花镜的床头柜油画”


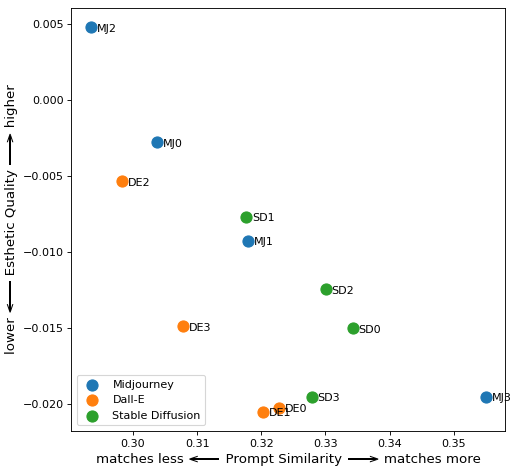
肖像
提示:“1920 年代男性的立体主义绘画”


提示:“一位巴西年轻女子的炭笔画”


提示:“一个专注的葡萄牙人的油画”


提示:“一个关心的韩国女人的粉彩画”


结论
将所有数据组合成一个图表,您可以看到 Midjourney 如何拥有最佳的美学质量指标。虽然 DALL-E 有一些渲染图最符合提示,但整体质量相比 Midjourney 有所下降。基于数字和我的眼睛,Stable Diffusion 似乎是三个系统中表现最差的。
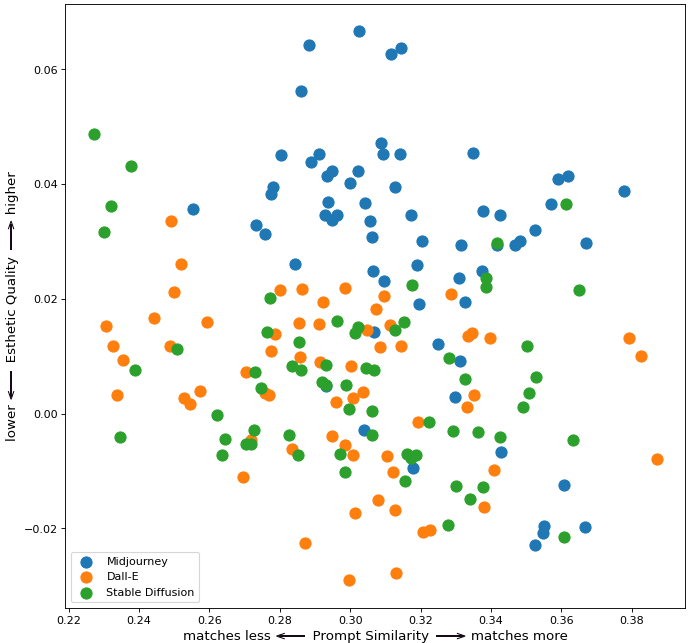
凭着我的权力,我特此将中途加冕为这场对决的赢家。
源代码和 Colabs
这个项目的所有源代码都可以在GitHub上找到。我在CC BY-SA 许可下发布了源代码。
致谢
我要感谢 Jennifer Lim 对这个项目的帮助。
参考
[1] A. Ramesh 等人的 DALL-E 2,使用 CLIP Latents 生成分层文本条件图像(2022)
[2] R. Rombach 等人的稳定扩散,具有潜在扩散模型的高分辨率图像合成(2022)
[3] Midjourney https://midjourney.gitbook.io/docs/
[4] A. Radford 等人的 CLIP,从自然语言监督中学习可转移的视觉模型(2021)
[5] P. Dhariwal 和 A. Nichol,Diffusion Models Beat GANs on Image Synthesis (2021)
[6] J. Ho 和 C. Saharia,使用扩散模型生成高保真图像(2021)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢