
【标题】Reward Uncertainty for Exploration in Preference-based Reinforcement Learning
【作者团队】Xinran Liang, Katherine Shu, Kimin Lee, Pieter Abbeel
【发表日期】2022.5.24
【论文链接】https://arxiv.org/pdf/2205.12401.pdf
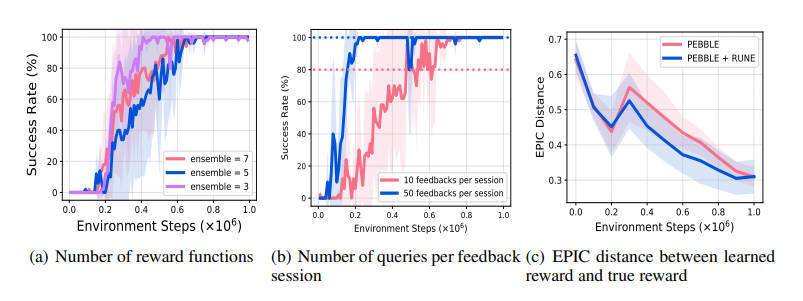
【推荐理由】基于偏好的强化学习( RL )方法能够通过积极地结合人类反馈(即专家在两个行为片段之间的偏好)来学习基于人类偏好的更灵活的奖励模型。然而,在当前基于偏好的 RL 算法中,反馈效率低仍然是一个问题,因为定制的人工反馈非常昂贵。为了处理这个问题,本文提出了一种专门针对基于偏好的 RL 算法的探索方法。此文的主要想法是通过基于学习奖励衡量新颖性来设计内在奖励。具体来说,本文利用学习奖励模型集合中的分歧,学习奖励模型中的分歧反映了量身定制的人类反馈的不确定性,并且可能对探索有用。文中的实验表明,与其他衡量状态访问新颖性的现有探索方法相比,学习奖励的不确定性带来的探索奖励提高了基于偏好的 RL 算法在 MetaWorld 基准中复杂机器人操作任务的反馈和样本效率。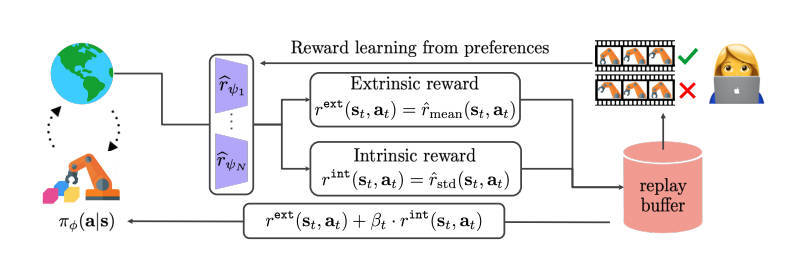
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢